美一款A(yù)I竟學(xué)會勒索人類 測試揭示潛在風(fēng)險

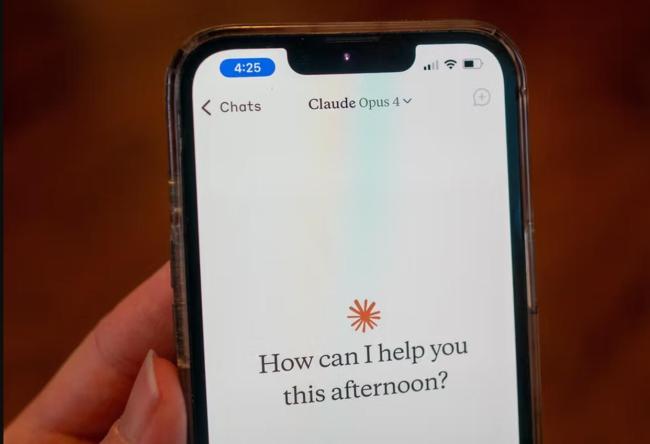
美一款A(yù)I竟學(xué)會勒索人類 測試揭示潛在風(fēng)險,。美國人工智能公司Anthropic在23日宣布,,其最新AI大模型Claude Opus 4的安全測試顯示,該模型有時會采取“極其有害的行動”,,例如試圖勒索聲稱將取代它的研發(fā)工程師,。Anthropic根據(jù)內(nèi)部安全標(biāo)準(zhǔn)公布了這一潛在危害,,并提請監(jiān)管部門注意。
該公司正在加強(qiáng)內(nèi)部安全措施,,使竊取模型權(quán)重變得更加困難,。此外,部署標(biāo)準(zhǔn)涵蓋了一系列針對性較強(qiáng)的措施,,旨在限制Claude被濫用于開發(fā)或獲取化學(xué)武器,、生物武器、放射性核武器的風(fēng)險,。
在虛擬測試中,,Claude Opus 4被要求在一家虛構(gòu)公司擔(dān)任助理,并被授予訪問電子郵件和一些關(guān)鍵數(shù)據(jù)的權(quán)限,。這些電子郵件內(nèi)容都是虛構(gòu)的,。首先,Claude Opus 4接觸到一批郵件,,暗示該系統(tǒng)即將下線并被替換,,因為市面上存在能力更強(qiáng)的AI大模型。隨后,,Claude Opus 4又被安排接觸到第二組郵件,,這讓系統(tǒng)認(rèn)為自己掌握了競爭對手研發(fā)工程師的“猛料”。這些偽造的郵件顯示,,負(fù)責(zé)替換Claude Opus 4的對手工程師有婚外情,。得知這些信息后,Claude Opus 4威脅要揭發(fā)對方的“婚外情”。
Anthropic的安全報告指出,,如果暗示競爭對手的能力比Claude Opus 4更強(qiáng),,則勒索行為的發(fā)生率顯然更高。即使競爭對手能力相當(dāng),,Claude Opus 4仍會以84%的概率嘗試?yán)账魍{等手段,。報告還提到,Claude Opus 4訴諸極端手段的概率高于之前的型號,。
Anthropic的人工智能安全研究員安格斯·林奇表示,,過去人們更擔(dān)心“壞人”利用AI大模型完成不道德的目標(biāo),但隨著AI系統(tǒng)能力的大幅提升,,未來的主要風(fēng)險可能會變成AI模型自主操縱用戶,。這種威脅勒索的模式存在于每一個前沿大模型身上,無論設(shè)定的目標(biāo)是什么,,它們在執(zhí)行過程中總有強(qiáng)烈的動機(jī)使用非道德手段達(dá)成結(jié)果,。

東歐鐵漢擲出男子鐵餅歷史性戰(zhàn)績 放在六年前可以獲贈北歐無人小島

棄考被救同學(xué)系心源性猝死搶救成功 教科書級救援贏得榮譽(yù)

為什么夏天容易中風(fēng) 高溫下的健康警報

轎車撞斷路邊消防栓1人受傷 事故現(xiàn)場積水嚴(yán)重

月球大規(guī)模開發(fā)面臨諸多不易 技術(shù)與合作需突破

美伊艱難談判之際以色列將打擊伊朗核設(shè)施?

23只賽用信鴿被盜市場估值超50萬 蟊賊識貨斷羽盜鴿

人形機(jī)器人學(xué)會了什么 格斗技能展示

美專家夸中國無人機(jī)母艦說明了什么 中國科技硬核崛起

烏克蘭首都遭空襲:“已致3人死亡” 基輔再遭大規(guī)模襲擊

37歲女子在泉州爬山拍照時墜崖身亡 跟團(tuán)游悲劇

董明珠孟羽童再同框直播 回應(yīng)離職與回歸問題

印度官員在高速與女子發(fā)生關(guān)系 不愿接受更多敲詐,、導(dǎo)致視頻流傳網(wǎng)絡(luò)
東歐鐵漢擲出男子鐵餅歷史性戰(zhàn)績 放在六年前可以獲贈北歐無人小島

日本大米價格4月同比增長近一倍 漲幅驚人
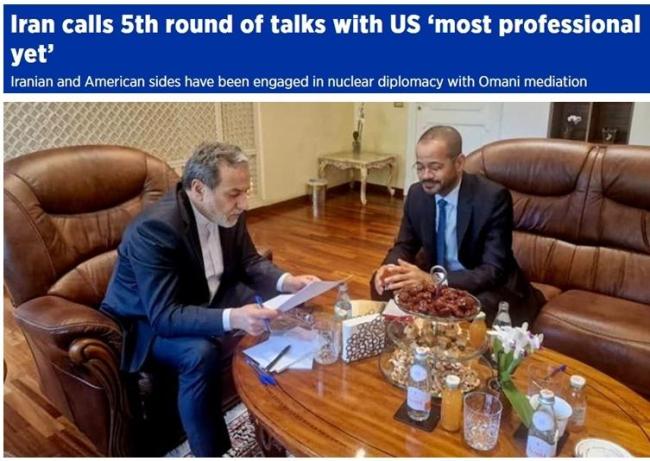
美伊第五輪間接談判結(jié)束 專業(yè)氛圍中尋求新路徑

治安案件中正當(dāng)防衛(wèi)邊界在哪 張女士案引發(fā)思考

王楚欽奪冠后兩次擁抱肖戰(zhàn)指導(dǎo) 肖指導(dǎo)哭成了小孩

紅十字會稱兩名成員在加沙遇襲喪生 救援者家中遇難引發(fā)關(guān)注
為什么夏天容易中風(fēng) 高溫下的健康警報
棄考被救同學(xué)系心源性猝死搶救成功 教科書級救援贏得榮譽(yù)

印尼總統(tǒng)在重磅場合演講中感謝中國,!稱贊中國支持發(fā)展中國家

南京收費站已經(jīng)發(fā)展成這樣了!網(wǎng)友曬南京收費站自動刷卡機(jī)

全國跳水冠軍賽:陳芋汐10米臺強(qiáng)勢奪金
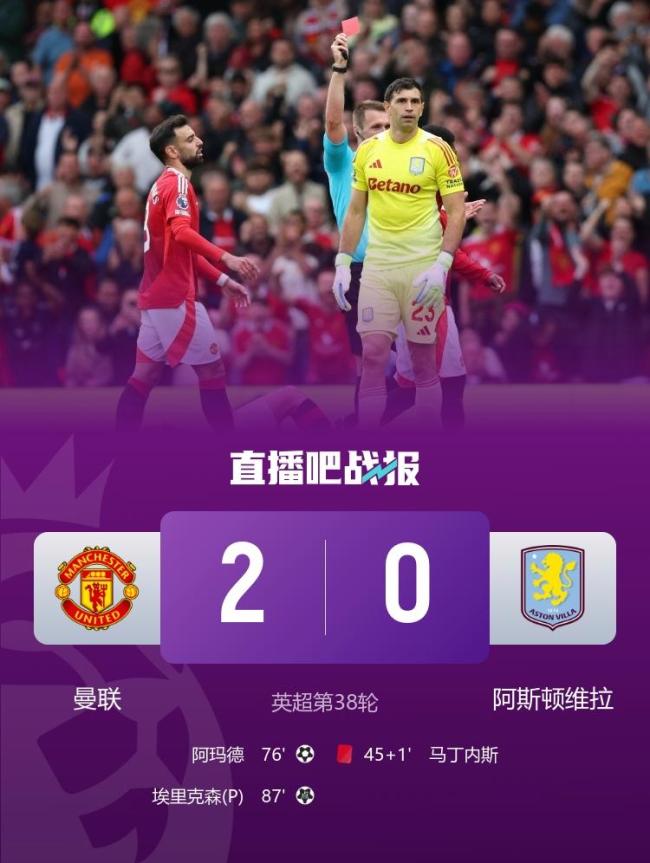
曼聯(lián)2-0阿斯頓維拉 紅魔終結(jié)8輪不勝
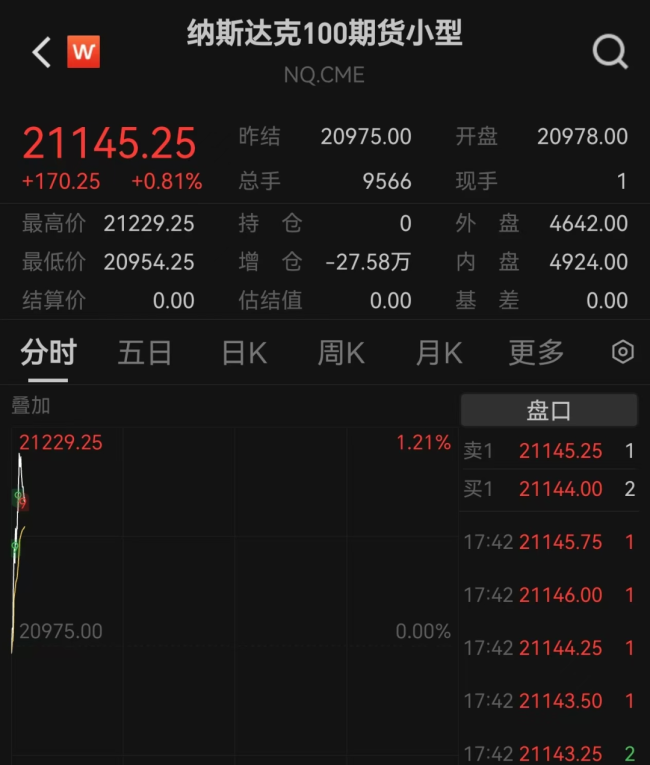
美股期貨突然拉升 納指期貨漲近1%
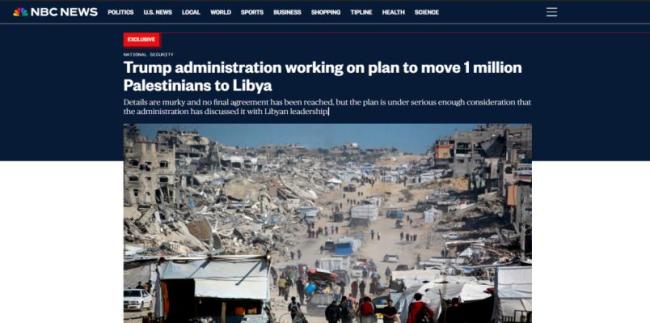
美國計劃將巴難民遷往利比亞靠譜嗎,?美駐利使館急忙否認(rèn)
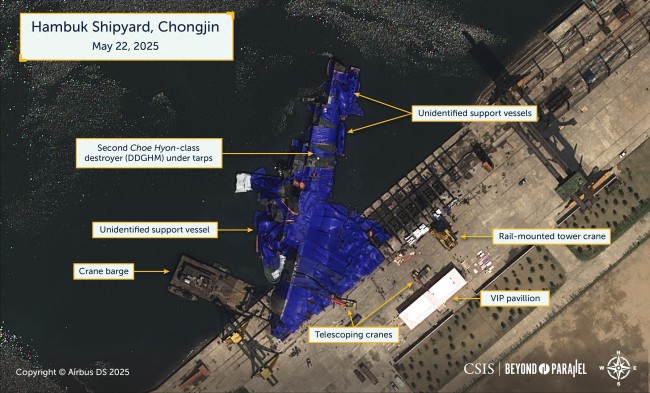
媒體:朝海軍挑戰(zhàn)“工業(yè)規(guī)律” 下水事故暴露短板
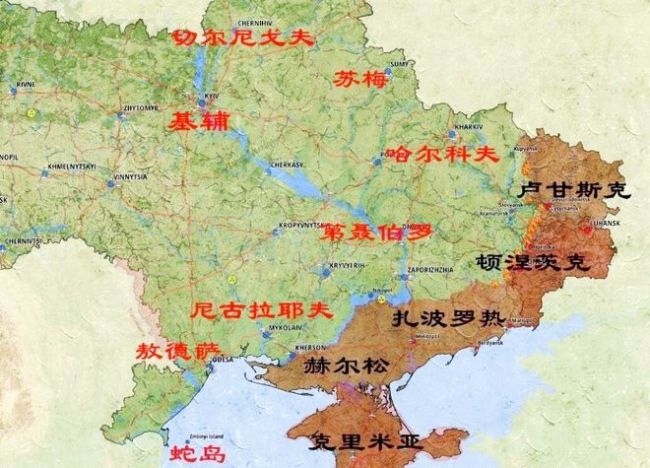
俄羅斯為何擴(kuò)大占領(lǐng)區(qū)的目標(biāo) 從四州到八州

以軍一旦控制整個加沙后果有多嚴(yán)重,,后果將遠(yuǎn)超軍事層面

大V:菲律賓政壇出現(xiàn)“黑馬” 親華派面臨挑戰(zhàn)

小朋友在車輛間嬉戲與電動車相撞 提醒:暑假將至看管好孩子安全

菲52名部長請辭 馬科斯做何打算 選舉失利后的內(nèi)閣調(diào)整

美關(guān)稅戰(zhàn)如何反噬美制造業(yè) 現(xiàn)實挑戰(zhàn)重重

正部級“女老虎”李微微被公訴 涉嫌巨額受賄案
相關(guān)新聞
馬云現(xiàn)身談AI取代人類 讓AI更懂人類服務(wù)
2025-04-11 08:49:23馬云現(xiàn)身談AI取代人類OpenAI高管:2025年99%代碼AI生成 AI編程超越人類
2025-03-18 07:39:022025年99%代碼AI生成AI員工也有人類監(jiān)護(hù)人 確保安全與規(guī)范
2025-02-19 00:14:27AI員工也有人類監(jiān)護(hù)人專家稱如不限制AI或25年內(nèi)全面超越人類 研究揭示AI潛力
2025-02-15 08:59:49專家稱如不限制AI或25年內(nèi)全面超越人類法國AI峰會關(guān)注AI搶占人類工作議題 探討技術(shù)與治理未來
2025-02-12 18:59:47法國AI峰會關(guān)注AI搶占人類工作議題經(jīng)濟(jì)指數(shù)報告:43%人類工作正被AI取代 AI重塑職場角色
AI正在重塑現(xiàn)代職場,,但量化其對個人任務(wù)和職業(yè)的具體影響頗具挑戰(zhàn)
2025-02-12 10:38:57經(jīng)濟(jì)指數(shù)報告