Meta無限長(zhǎng)文本大模型來了:參數(shù)僅7B,已開源 高效穩(wěn)定,,超越Transformer

谷歌和Meta相繼在無限長(zhǎng)上下文建模領(lǐng)域展開角逐,。Transformer模型因二次復(fù)雜度及對(duì)長(zhǎng)序列處理的局限性,盡管已有線性注意力和狀態(tài)空間模型等次二次解決方案,,但其預(yù)訓(xùn)練效率和下游任務(wù)準(zhǔn)確性仍不盡人意,。谷歌近期推出的Infini-Transformer通過創(chuàng)新方法,使大型語言模型能夠處理無限長(zhǎng)輸入,,且無需增加內(nèi)存與計(jì)算需求,,引發(fā)業(yè)界關(guān)注。
緊隨其后,Meta攜手南加州大學(xué),、CMU,、UCSD等研發(fā)團(tuán)隊(duì),推出了名為MEGALODON的神經(jīng)架構(gòu),,同樣致力于無限長(zhǎng)文本的高效序列建模,,上下文長(zhǎng)度無任何限制。MEGALODON在MEGA架構(gòu)基礎(chǔ)上,,引入了復(fù)數(shù)指數(shù)移動(dòng)平均(CEMA),、時(shí)間步歸一化層、歸一化注意力機(jī)制及具備雙特征的預(yù)歸一化殘差配置等技術(shù)組件,,旨在提升模型能力和穩(wěn)定性,。
在與LLAMA2的對(duì)比試驗(yàn)中,擁有70億參數(shù),、經(jīng)過2萬億訓(xùn)練token的MEGALODON展現(xiàn)出超越Transformer的效率優(yōu)勢(shì),。其訓(xùn)練損失為1.70,介于LLAMA2-7B(1.75)與13B(1.67)之間,。一系列基準(zhǔn)測(cè)試進(jìn)一步證實(shí)了MEGALODON在不同任務(wù)與模式中相對(duì)于Transformers的顯著改進(jìn),。
MEGALODON的核心改進(jìn)在于對(duì)MEGA架構(gòu)的優(yōu)化,利用門控注意力機(jī)制與經(jīng)典指數(shù)移動(dòng)平均法,。為增強(qiáng)大規(guī)模長(zhǎng)上下文預(yù)訓(xùn)練的能力與效率,,研究者引入了CEMA,將MEGA中的多維阻尼EMA擴(kuò)展至復(fù)數(shù)域,;并設(shè)計(jì)了時(shí)間步歸一化層,,將組歸一化應(yīng)用于自回歸序列建模,實(shí)現(xiàn)沿順序維度的歸一化,。此外,,通過預(yù)歸一化與兩跳殘差配置調(diào)整,以及將輸入序列分塊為固定塊,,確保了模型訓(xùn)練與推理過程中的線性計(jì)算與內(nèi)存復(fù)雜性,。
在與LLAMA2的直接較量中,MEGALODON-7B在同等數(shù)據(jù)與計(jì)算資源條件下,,訓(xùn)練困惑度顯著低于最先進(jìn)的Transformer變體,。針對(duì)長(zhǎng)上下文建模能力的評(píng)估涵蓋了從2M的多種上下文長(zhǎng)度到Scrolls中的長(zhǎng)上下文QA任務(wù),充分證明了MEGALODON處理無限長(zhǎng)度序列的能力,。此外,,在LRA、ImageNet,、Speech Commands,、WikiText-103和PG19等中小型基準(zhǔn)測(cè)試中,,MEGALODON在體量與多模態(tài)處理方面展現(xiàn)卓越性能,。
論文詳細(xì)介紹了MEGALODON的技術(shù)創(chuàng)新,,包括對(duì)MEGA架構(gòu)中關(guān)鍵組件的回顧及存在問題的探討。為解決MEGA面臨的表達(dá)能力受限,、架構(gòu)差異及無法大規(guī)模預(yù)訓(xùn)練等問題,,研究者創(chuàng)新提出CEMA,將多維阻尼EMA擴(kuò)展至復(fù)數(shù)域,;引入時(shí)間步歸一化,,通過計(jì)算累積均值與方差,將組歸一化擴(kuò)展至自回歸情況,;定制歸一化注意力機(jī)制以提升穩(wěn)定性,;并設(shè)計(jì)具有Two-hop殘差的預(yù)范數(shù)結(jié)構(gòu),有效應(yīng)對(duì)模型規(guī)模擴(kuò)大帶來的預(yù)歸一化不穩(wěn)定問題,。
實(shí)驗(yàn)結(jié)果顯示,,MEGALODON在長(zhǎng)上下文序列建模的可擴(kuò)展性與效率上表現(xiàn)出色。在相同訓(xùn)練token下,,MEGALODON-7B的負(fù)對(duì)數(shù)似然(NLL)優(yōu)于LLAMA2-7B,,顯示出更高的數(shù)據(jù)效率。在不同上下文長(zhǎng)度下的WPS(word/token per second)對(duì)比中,,MEGALODON-7B在處理長(zhǎng)上下文時(shí)速度明顯快于LLAMA2-7B,,印證了其在長(zhǎng)上下文預(yù)訓(xùn)練中的計(jì)算效率優(yōu)勢(shì)。
在各項(xiàng)基準(zhǔn)測(cè)試中,,MEGALODON均展現(xiàn)出優(yōu)秀性能,,無論是在短上下文任務(wù),還是長(zhǎng)上下文任務(wù),,以及指令微調(diào),、中等規(guī)模基準(zhǔn)評(píng)估(如ImageNet-1K圖像分類與PG-19文本生成)等方面,,MEGALODON均取得優(yōu)異成績(jī),,部分甚至超越已使用RLHF進(jìn)行對(duì)齊微調(diào)的模型。這些成果充分驗(yàn)證了MEGALODON在無限長(zhǎng)上下文建模領(lǐng)域的先進(jìn)性與廣泛應(yīng)用潛力,。
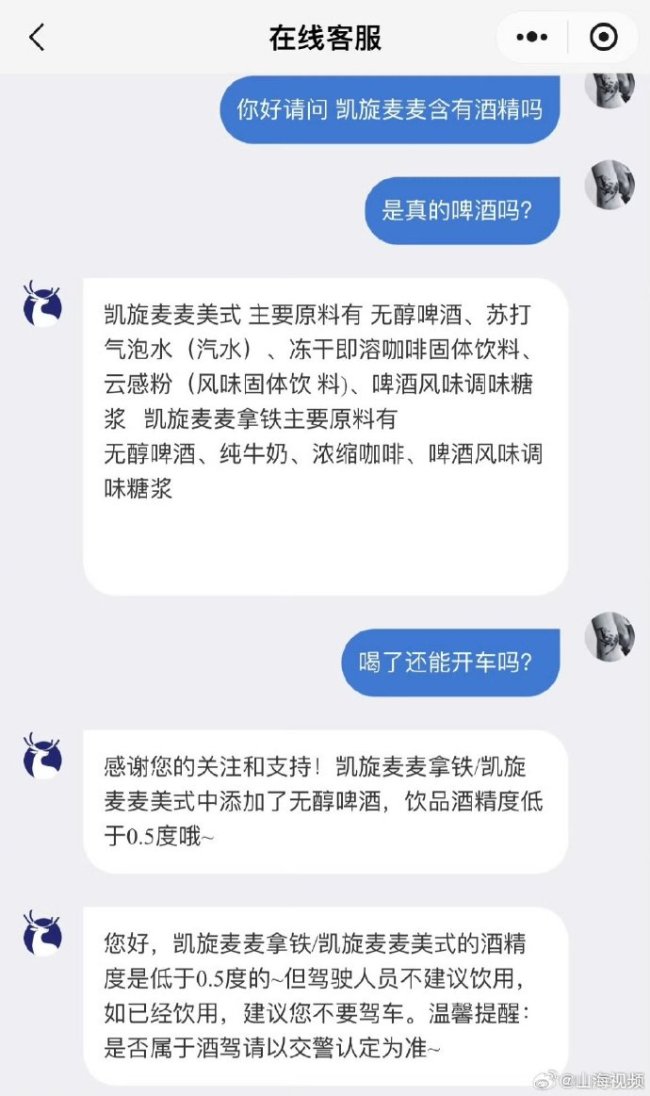
瑞幸稱凱旋麥麥酒精度低于0.5度 喝完勿開車

當(dāng)27歲的阿斯塔納遇上23歲的上合,,一起找尋青春的氣息!

什么是住房公積金年度結(jié)息,?

湖南一工作人員防汛時(shí)被水沖走失聯(lián)

菲律賓,,又傳來一個(gè)壞消息

高三女生賣游戲ID反被騙900元

農(nóng)村學(xué)生營(yíng)養(yǎng)餐補(bǔ)貼不能成“唐僧肉”
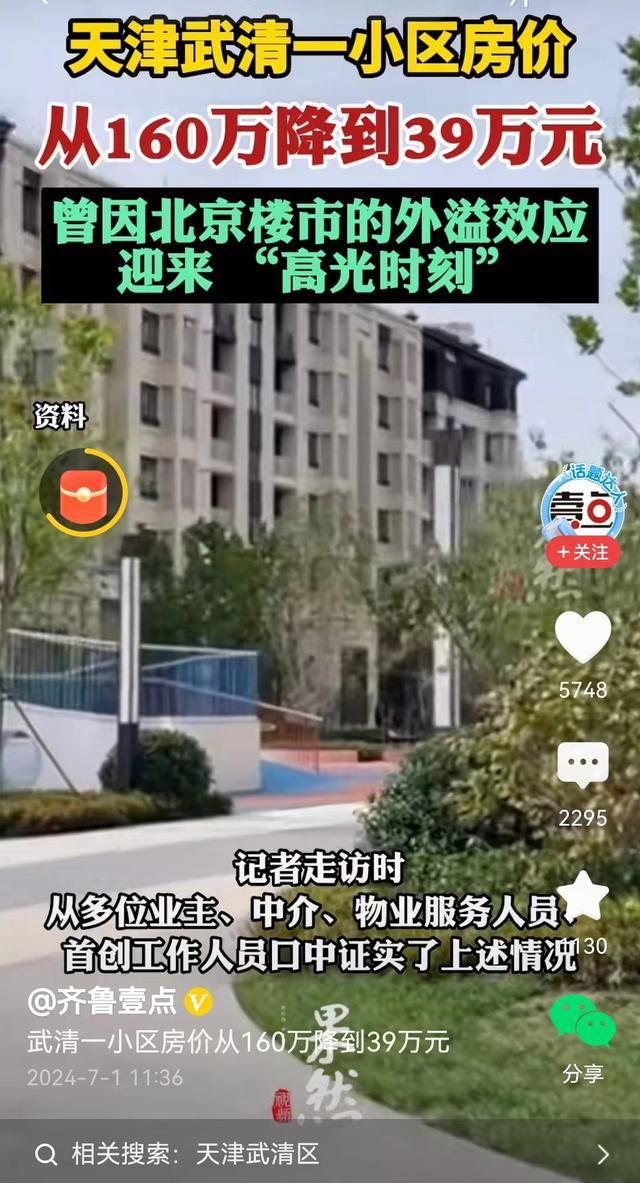
160萬房降到39萬可以不還房貸嗎,?樓市寒冬下的購房者困境

匈牙利接任歐盟輪值主席國(guó)前夕,,歐爾班發(fā)文:歐盟領(lǐng)導(dǎo)層想與俄開戰(zhàn)

炒作所謂“間諜”風(fēng)險(xiǎn),白宮欲對(duì)中國(guó)起重機(jī)加稅,,美港口群起反對(duì),!

美國(guó)究竟有多少核彈頭?最新數(shù)據(jù)
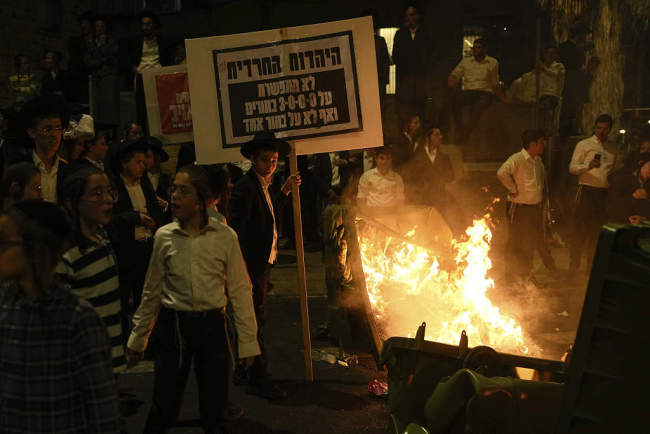
“寧愿死也不參軍,!”以色列極端正統(tǒng)派上街抗議征兵

平江暴雨為何洪水排不出去 道路塌方引擔(dān)憂

法國(guó)“屏住呼吸”舉行議會(huì)選舉,!美媒:此次選舉可能“撼動(dòng)歐盟與北約”

上海空港口岸入境旅客數(shù)量持續(xù)增長(zhǎng) 外籍旅客增幅顯著
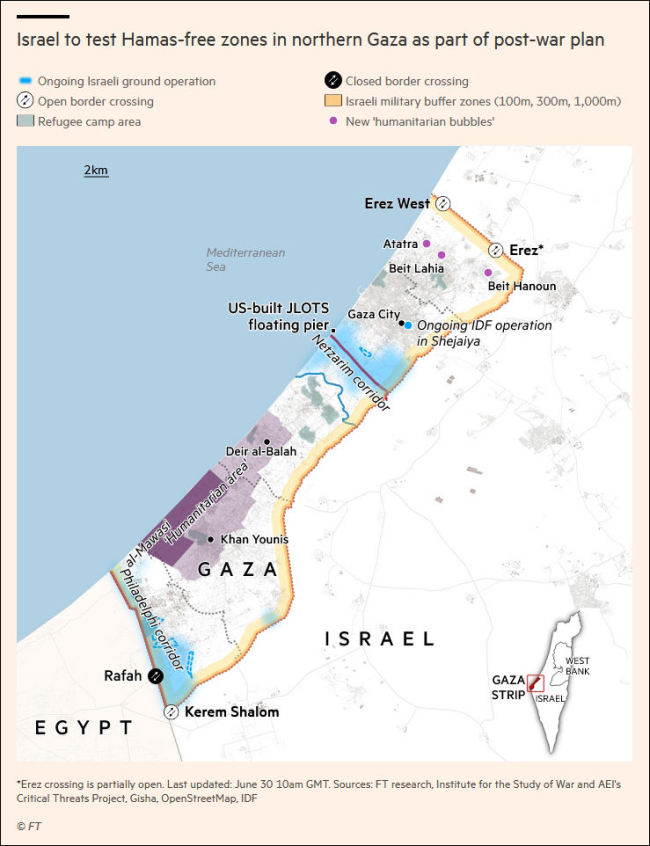
以色列在加沙試點(diǎn)逐漸取代哈馬斯,,被哈馬斯武力挫敗

高?;貞?yīng)開設(shè)"導(dǎo)彈維修技術(shù)"專業(yè):是真的

議起復(fù)盤 馬刺童話過于美好 勇士三叉戟解體終究未能復(fù)制傳奇

大選辯論后,拜登陷入“勸退”漩渦,!美媒刊文:“他已不是4年前的他了”

黨內(nèi)盟友涌向媒體,,千方百計(jì)轉(zhuǎn)移話題,,拜登開展危機(jī)公關(guān)救選情!

限制北約收集情報(bào),,威脅擊落美無人機(jī),!俄軍考慮在黑海設(shè)立禁飛區(qū)

張志杰母親聽聞噩耗病倒入院 家庭支柱驟失引悲痛

美媒炒作:盟友不是信不過拜登,,質(zhì)疑聲太多恐“便宜”了中俄

央行今年多次提示長(zhǎng)債風(fēng)險(xiǎn) 債市"糾偏"行動(dòng)升級(jí)

國(guó)會(huì)請(qǐng)?jiān)妇W(wǎng)站一度癱瘓,!80萬韓國(guó)網(wǎng)民要求“彈劾尹錫悅”

新華社談張志杰離世:生命至上應(yīng)是賽場(chǎng)的最高規(guī)則

衛(wèi)星影像顯示山東艦抵菲附近海域,外媒猜測(cè)有“威懾”之意,?軍事專家解讀
中企高管菲律賓被撕票 疑受邀前去考察
什么是住房公積金年度結(jié)息?
瑞幸稱凱旋麥麥酒精度低于0.5度 喝完勿開車
當(dāng)27歲的阿斯塔納遇上23歲的上合,,一起找尋青春的氣息,!

中國(guó)一個(gè)“管理?xiàng)l例”,又讓西方破了大防

澤連斯基稱不排除與俄“迂回”談判,,烏媒:談判態(tài)度發(fā)生“180度大轉(zhuǎn)彎”,!

百花獎(jiǎng)提名揭曉:《萬里歸途》《封神》領(lǐng)銜競(jìng)爭(zhēng)激烈

“買家秀”,!塞爾維亞首次公開展示紅旗-17AE防空系統(tǒng)
相關(guān)新聞
中國(guó)大模型登頂全球開源第一!
2024-06-27 13:34:44中國(guó)大模型登頂全球開源第一昆侖萬維宣布天工3.0大模型開啟公測(cè),擁有4000億參數(shù)
4月17日,,昆侖萬維發(fā)布重要消息:其自主研發(fā)的“天工3.0”基座大模型及“天工SkyMusic”音樂大模型已面向公眾開放公測(cè)
2024-04-17 15:00:08昆侖萬維宣布天工3.0大模型開啟公測(cè)Meta CEO扎克伯格最新采訪:最強(qiáng)開源模型Llama 3憑什么值百億美金
2024-04-19 13:49:45Meta昇騰社區(qū)回應(yīng)華為發(fā)布會(huì)被指造假:是讀取外部開源大模型實(shí)時(shí)生成的圖片
2024-05-16 14:24:44昇騰社區(qū)回應(yīng)華為發(fā)布會(huì)被指造假:是讀取外部開源大模型實(shí)時(shí)生成的圖片美國(guó)最該尷尬的,,是今天中國(guó)開源模型們重大的貢獻(xiàn) 通義大模型引領(lǐng)創(chuàng)新潮
2024-05-11 21:21:50美國(guó)最該尷尬的斯坦福AI團(tuán)隊(duì)“套殼”清華系開源大模型被實(shí)錘,,被揭穿后全網(wǎng)刪庫跑路 學(xué)術(shù)誠(chéng)信警鐘再響
近期,,斯坦福大學(xué)的人工智能研究團(tuán)隊(duì)推出了一款名為L(zhǎng)lama3-V的多模態(tài)大型模型,宣稱其性能超越了GPT-4V等其他知名模型
2024-06-04 20:06:10斯坦福AI團(tuán)隊(duì)“套殼”清華系開源大模型被實(shí)錘








