ChatGPT-5為何按下“暫停鍵”:是數(shù)據(jù)不夠,,還是能力太強(qiáng),? 數(shù)據(jù)瓶頸與控制難題交織

ChatGPT-5為何按下暫停鍵
關(guān)于ChatGPT-5的發(fā)布延遲,引發(fā)了廣泛猜測(cè),。人們期待新一代模型的同時(shí),,也在思考其背后的原因。是數(shù)據(jù)量不足的技術(shù)困局還是AGI(通用人工智能)的控制難題,?這些推測(cè)既帶來理性思考,,也引發(fā)深刻憂慮。
在AI領(lǐng)域,,數(shù)據(jù)被視為“石油”,,算法則是“引擎”。每個(gè)版本的ChatGPT都需要大量數(shù)據(jù)來提升語言理解和生成能力,。隨著技術(shù)的發(fā)展,,模型對(duì)數(shù)據(jù)的需求越來越大,找到足夠多的數(shù)據(jù)變得愈發(fā)困難,。這就像登山一樣,,每批新數(shù)據(jù)都是堅(jiān)實(shí)的階梯,幫助模型接近“智慧”的高峰,。然而,,當(dāng)可用數(shù)據(jù)逐漸耗盡時(shí),模型性能的提升開始放緩,。
ChatGPT-5為何按下“暫停鍵”:是數(shù)據(jù)不夠,,還是能力太強(qiáng)? 數(shù)據(jù)瓶頸與控制難題交織
科學(xué)研究中也有類似現(xiàn)象,。例如,,物理學(xué)家在上世紀(jì)大規(guī)模實(shí)驗(yàn)中發(fā)現(xiàn)新粒子,但隨著標(biāo)準(zhǔn)模型趨近完善,,發(fā)現(xiàn)新的基本粒子變得非常困難,。生物學(xué)領(lǐng)域的基因組研究早期突破后,深層挖掘同樣面臨瓶頸,。AI領(lǐng)域也遇到類似困境:過去模型總能從新內(nèi)容中學(xué)習(xí)到更多,,但現(xiàn)在再想找到大批量的新數(shù)據(jù)變得困難。這種狀態(tài)被稱為“數(shù)據(jù)瓶頸”,。
數(shù)據(jù)瓶頸不僅在于數(shù)量,,還在于高質(zhì)量數(shù)據(jù)的稀缺性,。過去,AI的進(jìn)步依賴于不斷增長(zhǎng)的數(shù)據(jù)量和模型規(guī)模,,但如今高質(zhì)量文本數(shù)據(jù)源逐漸被用盡,,新的有效數(shù)據(jù)越來越難找?;ヂ?lián)網(wǎng)上大部分公開,、高質(zhì)量的書籍、文章,、對(duì)話文本已被用于訓(xùn)練,,剩下的數(shù)據(jù)要么噪聲大,要么質(zhì)量低,,難以顯著提升模型的智力,。
另一種猜測(cè)是Open AI可能在控制問題上陷入長(zhǎng)考。如果ChatGPT-5的能力遠(yuǎn)超前代,,接近AGI水準(zhǔn),,那么問題就不只是模型是否足夠聰明,而是它是否足夠安全,。這意味著模型不再是簡(jiǎn)單的語言工具,,而是某種能夠自主學(xué)習(xí)和適應(yīng)的“智慧存在”。人類能否完全掌控這種智能成為關(guān)鍵問題,。

敬業(yè),!六旬調(diào)解員爬上數(shù)百米山峰調(diào)解矛盾

2025四大預(yù)爆藝人,有沒有你喜歡的,?

買藥材煲湯中毒身亡 斷腸草誤作海風(fēng)藤

中方的意思日本已讀懂,,石破茂最新對(duì)華表態(tài),,4字最令美國(guó)擔(dān)心 和平共處震動(dòng)美國(guó)

NBA公布12月份月最佳教練名單 雷霆與騎士主帥當(dāng)選

學(xué)者:尹錫悅以武拒捕可能性很大 局勢(shì)緊繃引發(fā)廣泛關(guān)注

外媒:中國(guó)是俄羅斯最大的貿(mào)易伙伴,,占俄貿(mào)易額的三分之一 中俄經(jīng)貿(mào)關(guān)系持續(xù)深化

特斯拉年度銷量下滑 交付不及預(yù)期引發(fā)股價(jià)下跌

若爆發(fā)第三次世界大戰(zhàn):頂級(jí)工業(yè)強(qiáng)國(guó),可能變身世界最大軍工廠,?

兩岸統(tǒng)一時(shí)間已定,?國(guó)臺(tái)辦給出11字答案!

全紅嬋感謝泳聯(lián)認(rèn)可 榮耀加冕最佳跳水運(yùn)動(dòng)員

女演員坦承抑郁經(jīng)歷,,抑郁癥的表現(xiàn)到底有哪些

特斯拉2024年全球交付超178.9萬輛 創(chuàng)歷史新高

電鉆式,、牛叫式、震唇式,、咯痰式,、斷氣式……聽到這種呼嚕聲趕緊送去醫(yī)院

為未來積攢本錢,這屆00后為了局部退休瘋狂存錢

迪馬濟(jì)奧預(yù)測(cè)尤文意超杯首發(fā) 雙前鋒領(lǐng)銜陣容

上海寶山一裝修建筑局部坍塌 3人被困救援中

臺(tái)北跨年轉(zhuǎn)播央視晚會(huì)承包商回應(yīng),!

老年人出游必備4大醫(yī)保技能 ,!
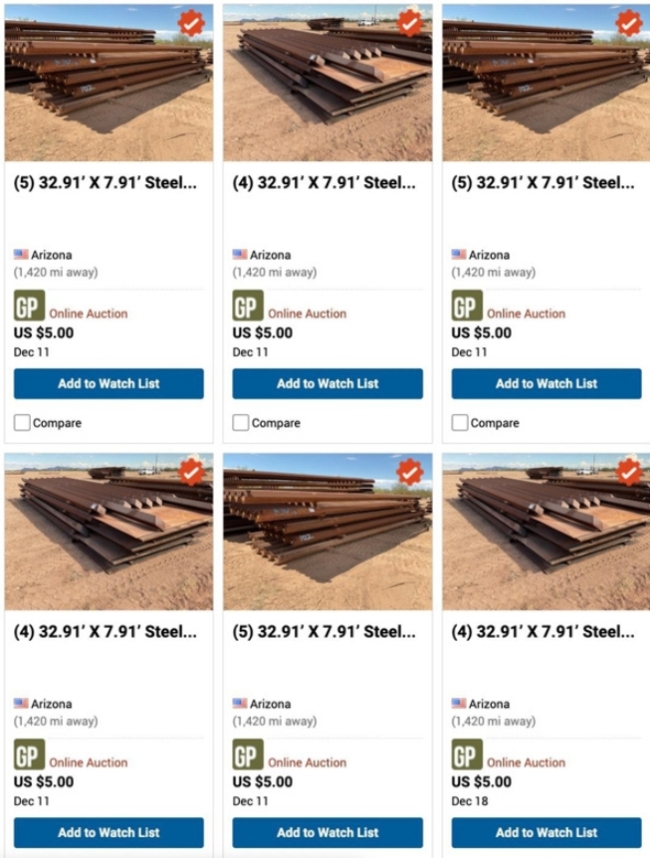
出售美墨邊境墻建設(shè)材料,,馬斯克:拜登100%叛國(guó) 低價(jià)拍賣引爭(zhēng)議
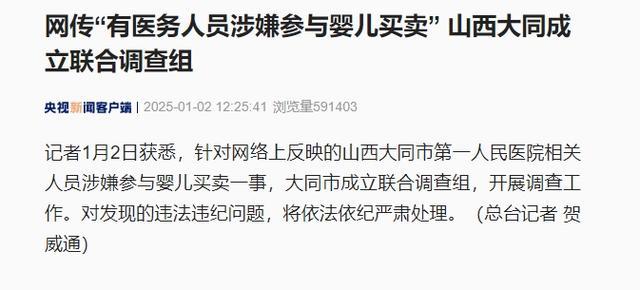
有醫(yī)院人員涉嫌參與嬰兒買賣?絕不讓地下生意改寫嬰兒的命運(yùn)
2025四大預(yù)爆藝人,,有沒有你喜歡的,?

韓國(guó)公調(diào)處執(zhí)行尹錫悅逮捕令 憲政史首次引發(fā)關(guān)注

荷蘭天然氣價(jià)格升至逾1年高位 供應(yīng)短缺推高成本

“谷子經(jīng)濟(jì)”的風(fēng),終于吹到了A股 年輕人的新寵崛起

韓總統(tǒng)官邸外氣氛緊張:支持和反對(duì)彈劾案民眾守夜集會(huì) 尹錫悅支持者高舉美國(guó)國(guó)旗高呼“保護(hù)總統(tǒng)”

美總統(tǒng)如何策劃自己的葬禮 傳統(tǒng)與個(gè)人意愿的結(jié)合

外媒盤點(diǎn)C羅潛在下家 梅西聯(lián)手引猜想
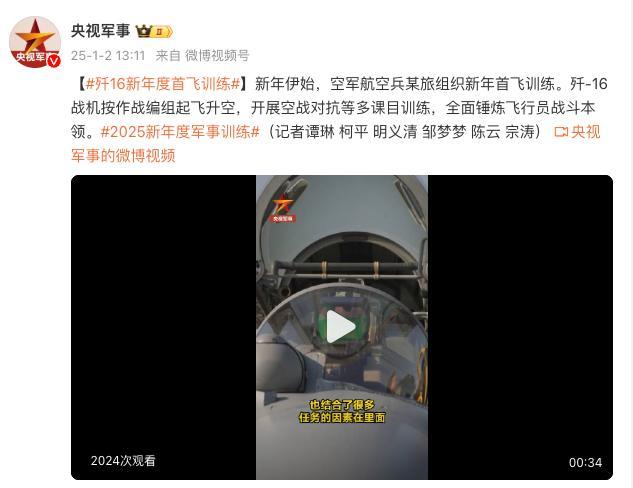
殲16新年度首飛訓(xùn)練 錘煉飛行員戰(zhàn)斗本領(lǐng)

多數(shù)韓國(guó)民眾支持彈劾尹錫悅 近七成受訪者贊同下臺(tái)

馬斯克:拜登100%叛國(guó) 邊境政策引爭(zhēng)議
敬業(yè),!六旬調(diào)解員爬上數(shù)百米山峰調(diào)解矛盾

現(xiàn)場(chǎng):韓國(guó)總統(tǒng)官邸附近部署超2800名警力

安倍晉三明明是日本人,,可為啥在他死后,墓碑上卻刻著中國(guó)漢字 文化淵源深厚
買藥材煲湯中毒身亡 斷腸草誤作海風(fēng)藤
相關(guān)新聞
央行增持黃金為何按下“暫停鍵” 高位震蕩下的成本考量
2024-07-15 08:32:32央行增持黃金為何按下“暫停鍵”夜騎開封被按下暫停鍵 安全與秩序考量
2024-11-09 21:36:00夜騎開封被按下暫停鍵“夜騎開封”按下暫停鍵 安全考量成主因
2024-11-10 01:29:00“夜騎開封”按下暫停鍵美聯(lián)儲(chǔ)會(huì)按下降息暫停鍵嗎,?今晚關(guān)鍵時(shí)刻來臨 CPI數(shù)據(jù)或掀市場(chǎng)波瀾
2024-10-10 19:47:00美聯(lián)儲(chǔ)會(huì)按下降息暫停鍵嗎,?今晚關(guān)鍵時(shí)刻來臨美聯(lián)儲(chǔ)下月會(huì)提前按下降息暫停鍵嗎 經(jīng)濟(jì)強(qiáng)韌通脹隱患重燃
2024-11-17 10:19:00美聯(lián)儲(chǔ)下月會(huì)提前按下降息暫停鍵嗎全國(guó)多地中小學(xué)按下開學(xué)“啟動(dòng)鍵”
2024年9月1日,,山東省棗莊市文化路小學(xué)的學(xué)生領(lǐng)到新課本。當(dāng)日,,全國(guó)多地中小學(xué)2024年秋季學(xué)期全面開學(xué),。
2024-09-02 00:27:58開學(xué)








