誰將成為明年“AI 交通”最熱詞 世界模型引領(lǐng)潮流

1942年,科幻小說家艾薩克·阿西莫夫在他的短篇小說《轉(zhuǎn)圈圈》中首次提出了“機(jī)器人三定律”,這一定律被視為現(xiàn)代人工智能技術(shù)的基石,。八十年后,,世界在許多方面已經(jīng)接近甚至超越了阿西莫夫的想象。
如今,,人們生活在一個(gè)由人工智能滲透的世界里,。2024年,我們見證了一系列人工智能技術(shù)的創(chuàng)新與涌現(xiàn),,如AI視頻生成模型Sora和GPT-4o等,。這些新技術(shù)不僅提升了駕駛體驗(yàn),還為城市交通的安全性,、效率和可持續(xù)性帶來了新的可能,。
展望2025年,隨著人工智能與交通的進(jìn)一步融合,,BEV+OCC感知能力困局待解,。近年來,自動(dòng)駕駛領(lǐng)域熱詞依次為:BEV+Transformer,、OCC占用網(wǎng)絡(luò),、無圖NOA、端到端,。BEV網(wǎng)絡(luò)通過矢量化的鳥瞰視角檢測(cè)白名單障礙物,,而OCC通過體素化的占用網(wǎng)絡(luò)預(yù)測(cè)3D空間的占位情況,實(shí)現(xiàn)對(duì)通用障礙物的感知,。然而,,目前BEV網(wǎng)絡(luò)的感知上限大約為1000多種物體,OCC網(wǎng)格大小受限于算力和實(shí)時(shí)性,,通常只能做到10厘米左右,,難以檢測(cè)微小物體。此外,,天氣,、光照、雨霧等復(fù)雜語義也是當(dāng)前技術(shù)難以解決的問題,。
數(shù)據(jù)成為端到端方案的最大瓶頸,。相較于分模塊方案,,端到端方案主要解決了從人工邏輯代碼到數(shù)據(jù)驅(qū)動(dòng)的問題,并通過自動(dòng)抽取信息減少信息損失,。決策和規(guī)劃的進(jìn)步顯著,,但感知能力提升有限。訓(xùn)練一個(gè)完美的自動(dòng)駕駛模型需要海量數(shù)據(jù),,特斯拉2024年初的視頻訓(xùn)練片段數(shù)量將近3000萬個(gè),,但仍未達(dá)到L3級(jí)別。大模型的引入增加了數(shù)據(jù)標(biāo)注需求,,如何保證高效訓(xùn)練成為關(guān)鍵問題,。
世界模型實(shí)現(xiàn)了從感知到認(rèn)知的躍遷。生成式AI大模型具備超強(qiáng)理解能力,,能夠建立對(duì)當(dāng)下場(chǎng)景的整體認(rèn)知,。例如,大模型可以通過意圖理解判斷出行人是否要橫穿馬路,,或通過長(zhǎng)時(shí)序信息判斷車輛是否即將減速,。這種從部分到整體、從分立到連續(xù),、從感知到認(rèn)知的轉(zhuǎn)變,,使自動(dòng)駕駛系統(tǒng)更加貼近人類駕駛的知識(shí)邏輯。世界模型的訓(xùn)練數(shù)據(jù)是視頻序列,,輸入當(dāng)前時(shí)刻視頻,,輸出下一時(shí)刻視頻,可以進(jìn)行無監(jiān)督訓(xùn)練,,解決了傳統(tǒng)端到端模型需要精確標(biāo)注海量視頻數(shù)據(jù)的難題,。

張桂梅收到新年第一朵玫瑰花 傳遞美麗與敬意

捕過中華鱘的他成護(hù)漁人 從捕魚者到守護(hù)者

年化12%理財(cái)產(chǎn)品爆雷 央視報(bào)道引發(fā)關(guān)注
捕過中華鱘的他成護(hù)漁人 從捕魚者到守護(hù)者

朝鮮舉行新年大型演出金正恩攜女觀看!

洪都拉斯總統(tǒng):或要求美從本國撤軍 回應(yīng)移民驅(qū)逐威脅

朝鮮總理剛換人,,普京就收到一封賀信,,不到24小時(shí),中方打去電話 三國互動(dòng)引關(guān)注

為什么頭發(fā)越洗越油,?醫(yī)生提醒:大多數(shù)因?yàn)樗?,建議不要頻繁洗頭
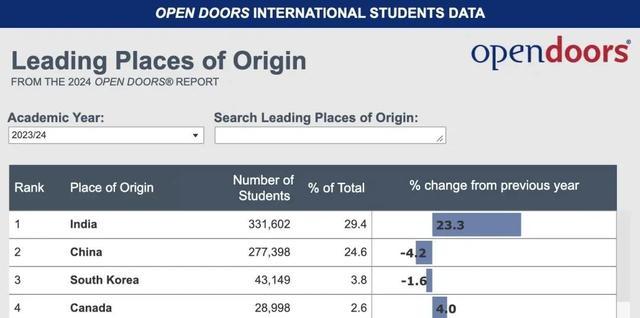
中產(chǎn)砸?guī)装偃f留學(xué)的回報(bào),被印度留子小成本實(shí)現(xiàn) 精準(zhǔn)規(guī)劃實(shí)現(xiàn)逆襲

朝鮮突然被俄羅斯爆出猛料,,美西方火速調(diào)轉(zhuǎn)“槍口” 烏俄局勢(shì)再添變數(shù)

詹姆斯小兒子加盟亞利桑那大學(xué) 四星新秀啟航

研究發(fā)現(xiàn)調(diào)整進(jìn)食時(shí)間可以緩解疲勞 通過晝夜節(jié)律干預(yù)

張小斐開大G連續(xù)違章6次,,網(wǎng)友:濾鏡碎一地,車品見人品 明星違章引反思
馬斯克“改名”引爆幣圈 神秘交易員賺翻天

2025第一個(gè)工作日開始了 新年新氣象

特朗普當(dāng)眾喊話中國,,不到24小時(shí),,中方直接把話說透 中美合作需相互尊重

爆款I(lǐng)P開播!不僅很爽,,還很好笑 多類型劇集齊開花
特朗普給海湖莊園起新名號(hào) 稱其為“宇宙中心”
張桂梅收到新年第一朵玫瑰花 傳遞美麗與敬意

加沙人冒大雨在泥水中排隊(duì)打水

馬斯克改了X昵稱和頭像 引發(fā)粉絲猜測(cè)與幣圈波動(dòng)

搬家現(xiàn)場(chǎng)3萬元現(xiàn)金消失 民警拼圖式破獲

也門某部落向美以兩國展示武力 胡塞武裝高調(diào)示強(qiáng)

美國公開中國各類彈道導(dǎo)彈數(shù)量,,打殘西太平洋美軍夠用嗎,? 導(dǎo)彈威脅引發(fā)熱議

樊振東MLB中國區(qū)冠軍榮耀大使 解鎖棒球新可能

美元持續(xù)強(qiáng)勢(shì)上漲,亞洲部分國家貨幣遭遇重創(chuàng) 多國央行考慮干預(yù)

我是陸地航母準(zhǔn)備啟程 新年啟航追夢(mèng)前行

谷愛凌:我一直代表中國 首登央視分享心路

2024年房地產(chǎn)政策力度空前 穩(wěn)樓市促回穩(wěn)
年化12%理財(cái)產(chǎn)品爆雷 央視報(bào)道引發(fā)關(guān)注
多名核心員工離開CDPR,,玩家開始擔(dān)憂《巫師4》質(zhì)量和開發(fā)進(jìn)度 核心成員流失引熱議

俄羅斯游戲主機(jī)踏上自研之路:霧游戲電視棒,、Elbrus 芯片主機(jī)雙頭并進(jìn) 探索霧游戲新領(lǐng)域

波蘭總理:北約國家準(zhǔn)備因電纜事故加強(qiáng)在波羅的海的軍事存在

馬斯克回應(yīng)拉斯維加斯爆炸案 特斯拉團(tuán)隊(duì)正調(diào)查此事
中轉(zhuǎn)換乘有這3種情況 分段購票攻略
相關(guān)新聞
端到端、世界模型,、車路云……誰將成為明年“AI+交通”最熱詞?
2024-12-13 14:37:29誰將成為明年AI+交通最熱詞誰將成為下一個(gè)入股引望的車企,?
2024-09-24 09:49:22誰將成為下一個(gè)入股引望的車企誰將成為新的哈馬斯領(lǐng)導(dǎo)人 潛在人選引發(fā)關(guān)注
2024-10-21 20:19:03誰將成為新的哈馬斯領(lǐng)導(dǎo)人今年7月成為史上最熱7月 全球熱浪預(yù)警
2024-08-02 06:13:34今年7月成為史上最熱7月誰將成為日本新首相 小泉進(jìn)次郎勝算大增
2024-09-27 07:38:50誰將成為日本新首相巴黎奧運(yùn)會(huì)或成為有史以來最熱一屆 高溫威脅運(yùn)動(dòng)員生命
2024-06-20 11:05:53巴黎奧運(yùn)會(huì)或成為有史以來最熱一屆