顯卡可能沒那么重要了?中國公司給硅谷好好上了一課 新年驚喜震撼西方(3)

是全面落敗
,。
而在各種大廠手里的閉源模型,,那些大家耳熟能詳?shù)氖裁?GPT-4o 、 Claude 3.5 Sonnet 啥的,, V3 也能打得有來有回,。
你看到這,可能覺得不過如此,,也就是追上了國際領(lǐng)先水平嘛,,值得這么吹嗎?
殘暴的還在后面,。
大家大概都知道了,,現(xiàn)在的大模型就是一個通過大量算力,讓模型吃各種數(shù)據(jù)的煉丹過程,。
在這個煉丹期,,需要的是大量算力和時間往里砸。
所以在圈子里有了一個新的計量單位“GPU時”,,也就是用了多少塊GPU花了多少個小時的訓練時間,。
GPU時越高,意味著花費的時間,、金錢成本就越高,,反之就物美價廉了。
前面說的此前開源模型王者,, Llama 3.1 405B ,,訓練周期花費了 3080 萬 GPU 時。
可性能更強的V3,,
只花了不到280萬GPU時
,。
以錢來換算,,DeepSeek搞出V3版本,大概只花了4000多萬人民幣,。
而 Llama 3.1 405B 的訓練期間,, Meta 光是在老黃那買了 16000 多個 GPU ,保守估計至少都花了十幾億人民幣,。
至于另外的那幾家閉源模型,,動輒都是幾十億上百億大撒幣的。
你別以為DeepSeek靠的是什么歪門邪道,,人家是正兒八經(jīng)的有技術(shù)傍身的,。
為了搞清楚DeepSeek的技術(shù)咋樣,咱們特地聯(lián)系了語核科技創(chuàng)始人兼CTO池光耀,,他們主力發(fā)展企業(yè)向的agent數(shù)字員工,,早就是DeepSeek的鐵粉了。

算下2024年人均經(jīng)濟賬:可支配收入增加2000元 居民消費能力提升

女孩玩煙花遭反沖炸毀衣服,,提醒:小孩玩煙花時一定要在身邊陪護
臺測試封殺小紅書遭網(wǎng)友嘲諷 美國夢變驚魂記
臺測試封殺小紅書遭網(wǎng)友嘲諷 美國夢變驚魂記

中國新突破震撼全球,,美國竟因此掀起反印風潮!
女孩玩煙花遭反沖炸毀衣服,,提醒:小孩玩煙花時一定要在身邊陪護

《白月梵星》敖瑞鵬解鎖妖王角色 顏值與氣質(zhì)并存

尹錫悅被批捕后數(shù)百名鐵粉打砸法院 支持者闖入破壞

26歲漸凍癥女孩求助蔡磊,,蔡磊回復了:她的病情已不符合臨床入組條件

CBA最新積分榜:廣廈9連勝第一,穩(wěn)固榜首位置

周鴻祎用車厘子給大家拜早年了:新的一年,,愿大家一起福氣多多,,幸運滿滿

特朗普第二次就職儀式會有哪些不同 嚴寒改室內(nèi),團結(jié)成主題

民調(diào)稱美民眾對特朗普政策的支持更高 內(nèi)政優(yōu)先情緒上升
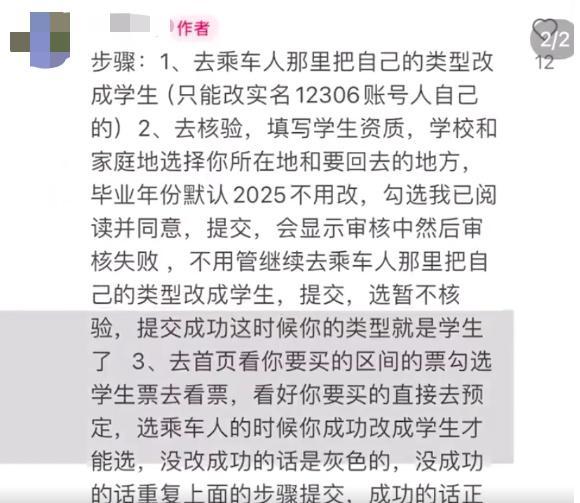
12306回應有人裝成學生搶票 違規(guī)操作將受罰

77名支持巴勒斯坦示威者與倫敦警方發(fā)生沖突后被捕 最嚴重犯罪升級

伊朗又公開一處軍事基地 地下500米深處存放攻擊艇

江蘇90后姑娘成央視蛇年春晚主持人 還是《新聞聯(lián)播》首位90后主播
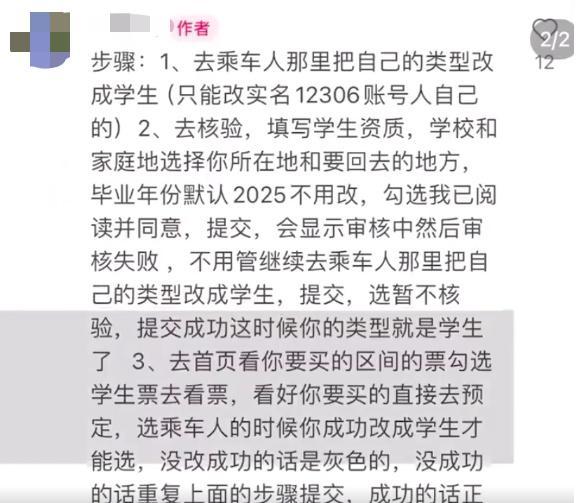
12306溫馨提示:“乘客偽裝學生身份搶學生票,,進站補成人票”不符合規(guī)定 違規(guī)購票將受罰

民進黨臺南大罷免說明會喊停被批 假仙行為遭揭露

庫爾斯克閉環(huán),,俄軍想要包烏軍餃子?
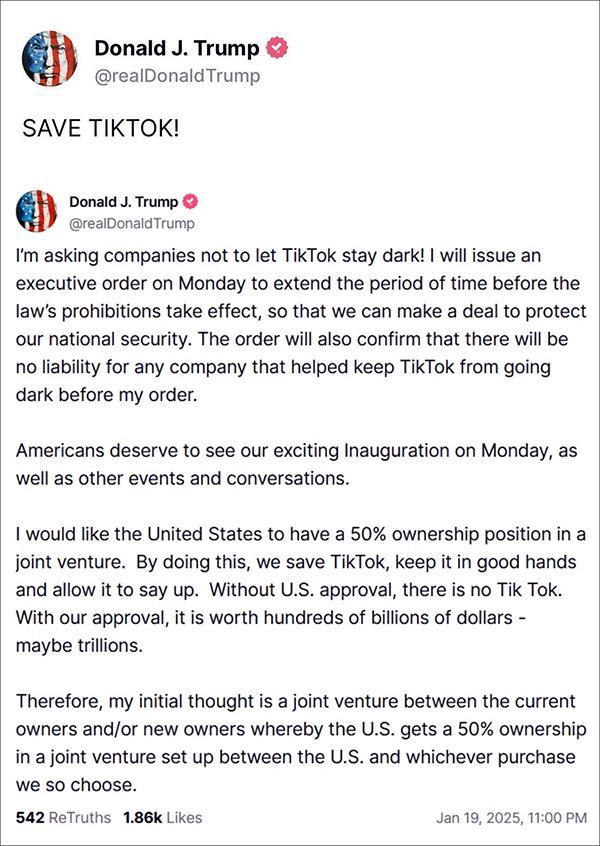
特朗普:救救TikTok,周一我就簽新命令恢復 爭取時間達成協(xié)議

特朗普再次對華示好 上任百日內(nèi)訪華 拜登陷入尷尬 中美關(guān)系迎來新契機
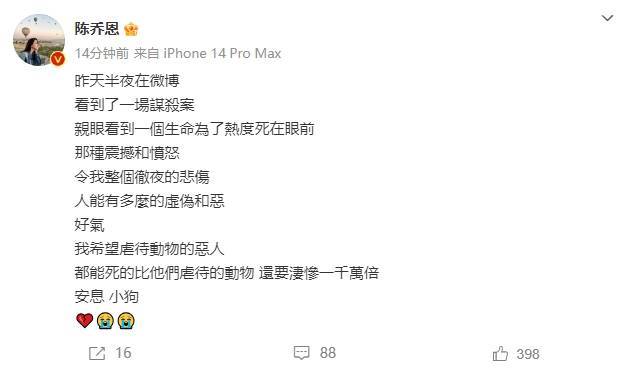
陳喬恩為網(wǎng)紅小狗艾特發(fā)聲 呼吁嚴懲虐動物行為

北約要親自下場,?爆炸性消息傳出,,普京被激怒,,難怪特朗普喊話和談 北約波蘭動作頻頻

尹錫悅結(jié)局已定,?美日迅速拋棄 首位被捕總統(tǒng)恐難逃鐵窗
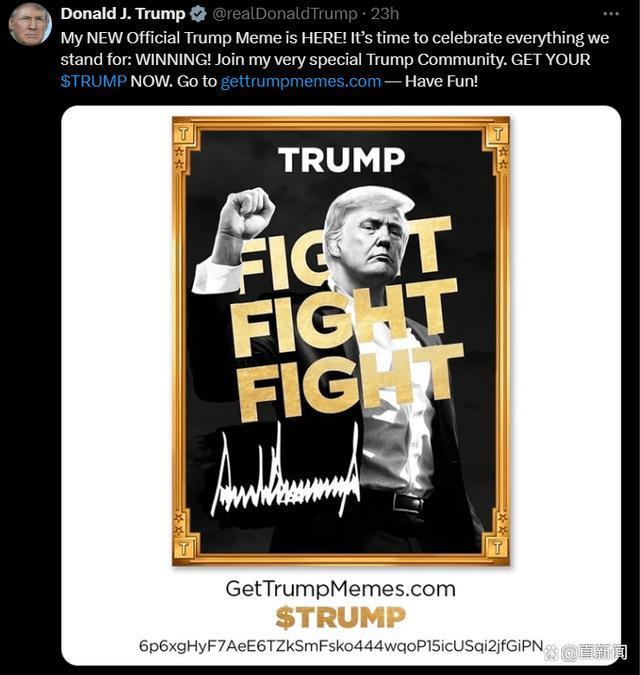
特朗普宣布發(fā)行加密貨幣 市值飆升引爭議

TikTok稱將尋找在美可用的長期方案 服務已恢復
年輕人開始整頓年味 新年飲品新潮流

現(xiàn)在是入手黃金的好時機嗎 金價創(chuàng)歷史新高引發(fā)關(guān)注
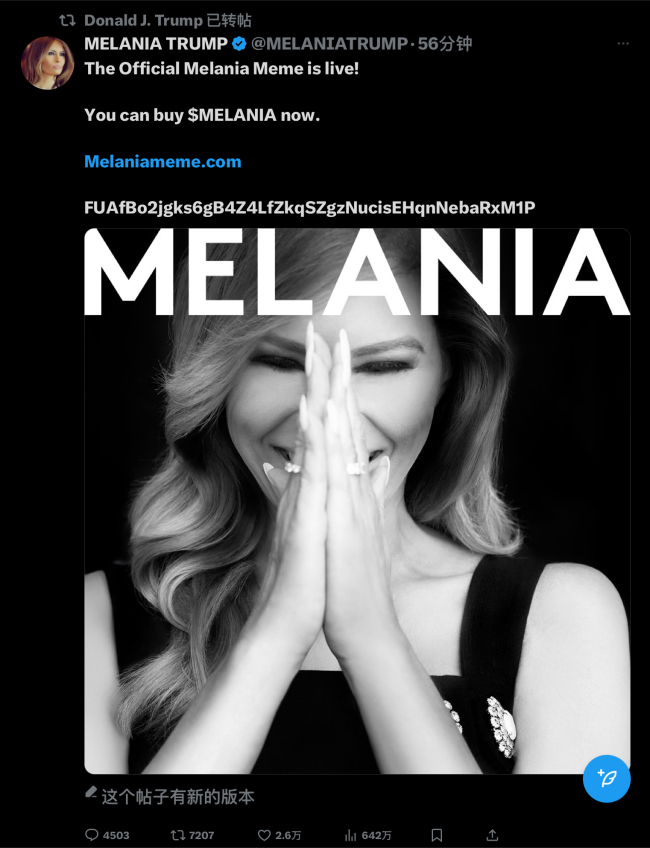
特朗普妻子發(fā)行虛擬幣MELANIA 家族成員或?qū)⒏M

尹錫悅將拍嫌犯大頭照 換上囚服接受調(diào)查
算下2024年人均經(jīng)濟賬:可支配收入增加2000元 居民消費能力提升

一圖梳理美國總統(tǒng)就職典禮儀式感 見證權(quán)力交接的傳統(tǒng)慶典

Tiktok用戶驚魂14小時 美國用戶涌入小某書

小紅書博主整頓外國人審美 挑戰(zhàn)媚外現(xiàn)象
相關(guān)新聞
美國的一場颶風 可能要把顯卡干漲價了
2024-10-09 10:02:29美國的一場颶風全紅嬋說這屆金牌沒那么重了 心態(tài)更成熟
2024-08-07 10:46:29全紅嬋說這屆金牌沒那么重了女生在森林公園上班工作是巡山:很滿意,,班味沒那么重
00后女孩謙謙在云南普洱太陽河森林公園工作,她在網(wǎng)上發(fā)布了與白眉長臂猿的日?;?,引發(fā)眾多網(wǎng)友點贊。
2024-07-12 10:39:07女生在森林公園上班工作是巡山顯卡說漲價就漲價,!英偉達全球GPU市場占比90%:AMD,、英特爾沒存在感 壟斷地位愈發(fā)穩(wěn)固
英偉達在GPU市場的主導地位持續(xù)增強,人們期望AMD和Intel能展現(xiàn)出更強的競爭力
2024-12-13 15:38:56英偉達全球GPU市場占比90%英特爾預告 12 月 3 日公布“顯卡大消息”,,預計發(fā)布銳炫 B 系列獨立顯卡 公版顯卡即將亮相
2024-12-02 10:07:02英特爾預告 12 月 3 日公布“顯卡大消息”智能音箱,,白給都沒人要了,?
2024-12-24 13:53:29智能音箱白給都沒人要了