DeepSeek暴擊美股 引發(fā)全球AI界關(guān)注

DeepSeek以低成本和少量芯片實(shí)現(xiàn)了與OpenAI等巨頭媲美的性能,引發(fā)國(guó)際AI界的廣泛關(guān)注,。這意味著如果算力不再是決定AI性能的關(guān)鍵因素,,之前大量投資英偉達(dá)芯片的邏輯可能會(huì)發(fā)生變化,其他相關(guān)行業(yè)也將受到影響,。一位首席經(jīng)濟(jì)學(xué)家在微博上表達(dá)了這一觀點(diǎn),。
緊接著,周一亞洲市場(chǎng)率先感受到了“東方神秘力量”DeepSeek帶來的沖擊,。A股中的DeepSeek概念暴漲超過11%,,而算力相關(guān)的板塊如AI算力、GPU,、液冷服務(wù)器和ASIC芯片等均大跌超3%,。光芯片、高速銅互聯(lián),、光通信和光模塊等板塊跌幅更是達(dá)到5%以上,。日本半導(dǎo)體ETF也下跌了超過3%。
實(shí)際上,,DeepSeek帶來的焦慮甚至恐慌更多地體現(xiàn)在美國(guó)市場(chǎng),。周一納斯達(dá)克期貨跌近3%,計(jì)劃為美國(guó)AI投資千億美元的軟銀股價(jià)暴跌6%,。市場(chǎng)擔(dān)心的問題不僅是中國(guó)AI技術(shù)追趕甚至超越美國(guó),,還包括對(duì)DeepSeek高效訓(xùn)練方法的驚愕。這引發(fā)了關(guān)于美國(guó)科技巨頭囤積GPU的意義,、英偉達(dá)市值的真實(shí)價(jià)值以及美國(guó)政府管制先進(jìn)AI芯片出口效果的質(zhì)疑,。
令人驚訝的是,在中國(guó)獲取先進(jìn)AI芯片受到嚴(yán)格限制的情況下,,一家成立僅一年半且去年才推出首款大模型的年輕公司能夠給全球市場(chǎng)帶來如此震撼,。該公司沒有迷信傳統(tǒng)的“大力出奇跡”的尺度定律,而是專注于創(chuàng)新訓(xùn)練方法,,減少了對(duì)計(jì)算資源的需求,。
去年12月,DeepSeek發(fā)布了新一代開源大模型DeepSeek-v3,,其能力接近閉源的GPT-4,,但訓(xùn)練成本僅為557.6萬美元,使用了2048張英偉達(dá)H800 AI芯片,。相比之下,,類似能力的模型通常需要1.6萬張GPU進(jìn)行集群訓(xùn)練,,例如Meta發(fā)布的Llama-3-405B在類似的集群上花費(fèi)了3080萬GPU小時(shí),而DeepSeek僅用了約280萬GPU小時(shí),。
這種高效的訓(xùn)練方式改變了AI對(duì)先進(jìn)芯片和算力需求的邏輯,。行業(yè)分析認(rèn)為,DeepSeek開源讓一些對(duì)OpenAI封閉不滿的研究者感到高興,,更重要的是,,它展示了中國(guó)在先進(jìn)算力受限情況下研發(fā)先進(jìn)模型的能力。

“一二三四五......”司機(jī)見中草藥包變10萬現(xiàn)金驚住了
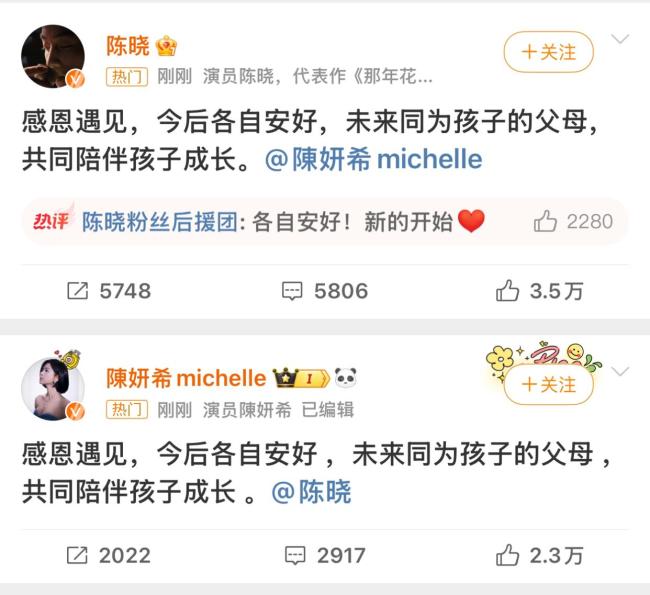
陳曉陳妍希情史回顧 九年婚姻終落幕

中國(guó)導(dǎo)演20萬美元拍出北美短劇第一 刷新票房紀(jì)錄

烏方將不承認(rèn)美俄談判達(dá)成的協(xié)議 澤連斯基堅(jiān)決立場(chǎng)

澤連斯基將到訪沙特 不參與美俄會(huì)談

特朗普批波音總統(tǒng)專機(jī)還沒造好 項(xiàng)目拖延引不滿
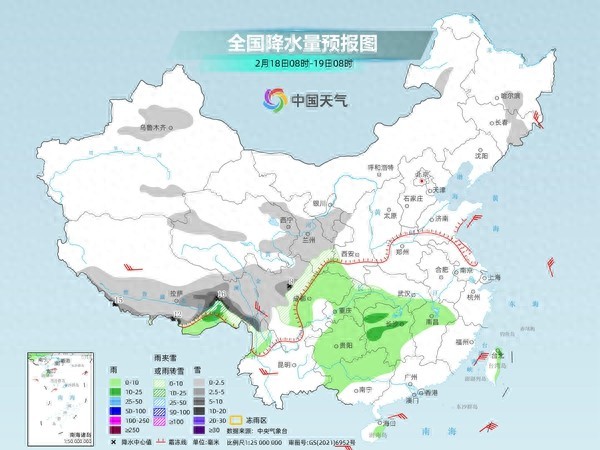
未來三天南方陰雨濕冷感明顯 北方降水增多
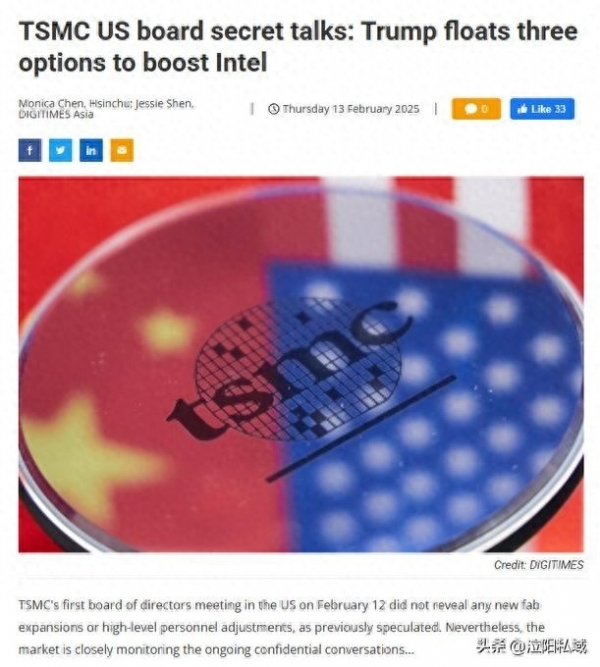
媒體批特朗普又一次“搶劫”臺(tái)灣 美國(guó)的真實(shí)意圖暴露

伊朗:反對(duì)外國(guó)勢(shì)力干涉敘利亞 支持?jǐn)⑷嗣褡詻Q權(quán)
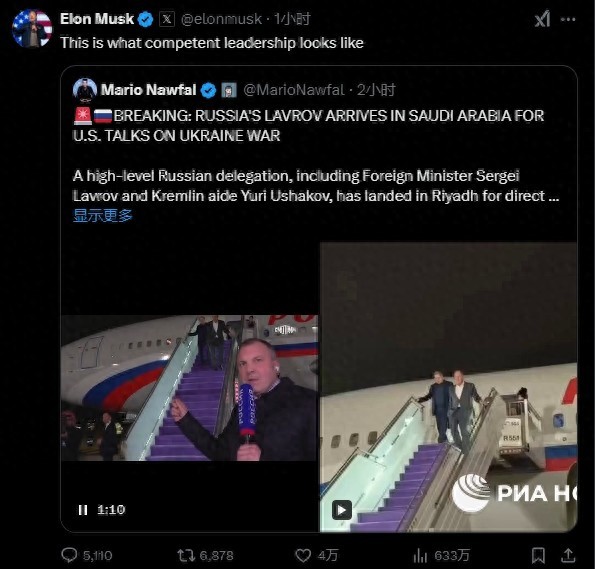
美俄談判今日開始 澤連斯基:不承認(rèn) 烏克蘭缺席引發(fā)爭(zhēng)議

私家車占人行道家長(zhǎng)擔(dān)憂孩子走車道 社區(qū)回應(yīng):將安裝U型桿或石球

武漢一培訓(xùn)機(jī)構(gòu)請(qǐng)千名學(xué)生看哪吒2 放松身心緩解壓力
陳曉陳妍希情史回顧 九年婚姻終落幕

為了增加軍費(fèi),,英國(guó)公共服務(wù)部門被曝準(zhǔn)備削減11%的預(yù)算,,歐洲派兵計(jì)劃陷入僵局
“一二三四五......”司機(jī)見中草藥包變10萬現(xiàn)金驚住了

黑中介騙取巨額服務(wù)費(fèi)被公訴 虛假承諾誘騙客戶
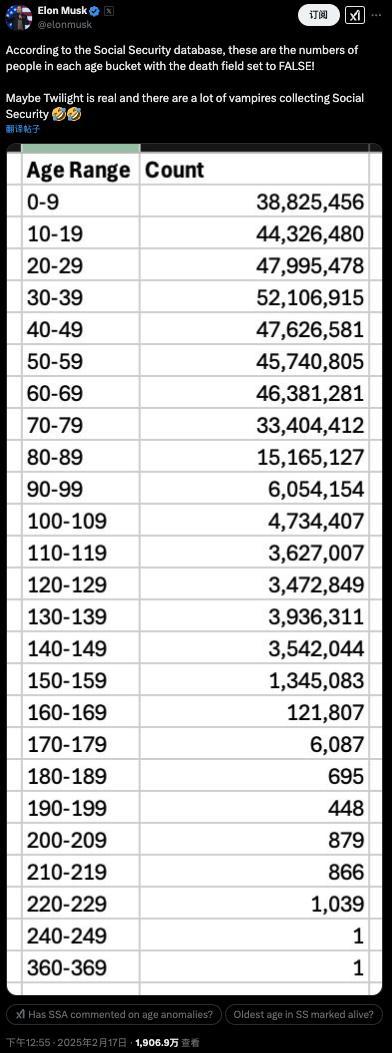
馬斯克查賬“美國(guó)社?!?,稱發(fā)現(xiàn)360歲老人?

曝王大陸涉嫌逃兵役被捕

哪吒2主創(chuàng)團(tuán)隊(duì)已進(jìn)入新創(chuàng)作周期 續(xù)寫神話新篇章

美為何提議從中國(guó)向?yàn)跖汕簿S和人員 美國(guó)的奇葩主意

美客機(jī)翻覆現(xiàn)場(chǎng)視頻曝光 惡劣天氣或成事故主因

歐洲的安全,,還是美國(guó)的利益,?美俄談判前夕,歐洲被邊緣化引發(fā)擔(dān)憂

金價(jià)連漲7周后“跳水” 金店再現(xiàn)買金熱

美航司客機(jī)事故乘客拍下逃生瞬間 加拿大:事發(fā)時(shí)風(fēng)力強(qiáng)勁

大V:歐洲和烏克蘭遭受三次沉重打擊 西方暴露三大問題

拉夫羅夫抵達(dá)沙特 單手揣兜下飛機(jī) 談判桌上的博弈
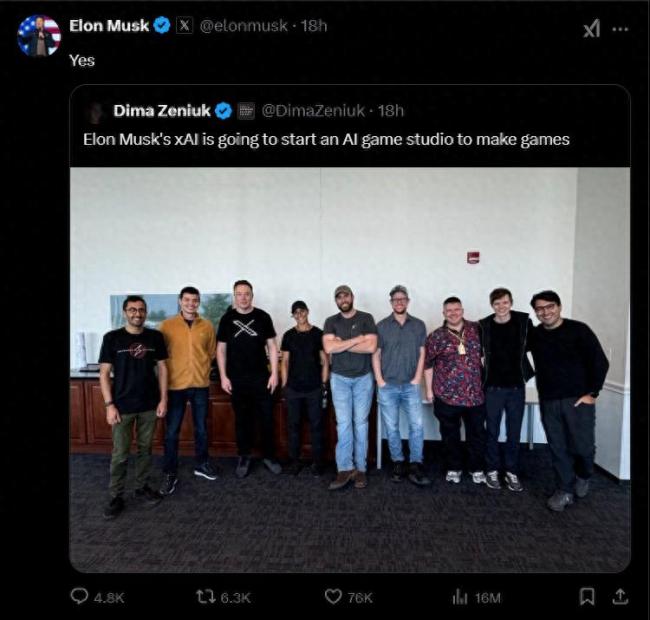
馬斯克坐實(shí)AI游戲工作室計(jì)劃 讓游戲再次偉大

觀察:2025年的Mini LED電視市場(chǎng),,怎么打,? 三大競(jìng)爭(zhēng)焦點(diǎn)浮現(xiàn)
中國(guó)導(dǎo)演20萬美元拍出北美短劇第一 刷新票房紀(jì)錄

美國(guó)新版“空軍一號(hào)”再度延期交付 供應(yīng)鏈問題拖累進(jìn)度
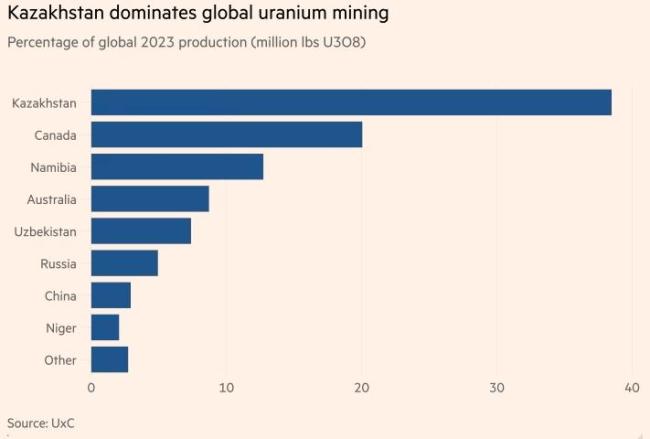
哈薩克斯坦鈾出口重心東移 哈鈾售中俄后致歐美快斷供了

今日雨水節(jié)氣,老傳統(tǒng)“吃二樣,,做二事,,忌二事” 千年習(xí)俗的智慧

美國(guó)翻臉后,歐洲從“夸夸其談的少年”走向獨(dú)立成熟要做三件事 應(yīng)對(duì)三大危機(jī)
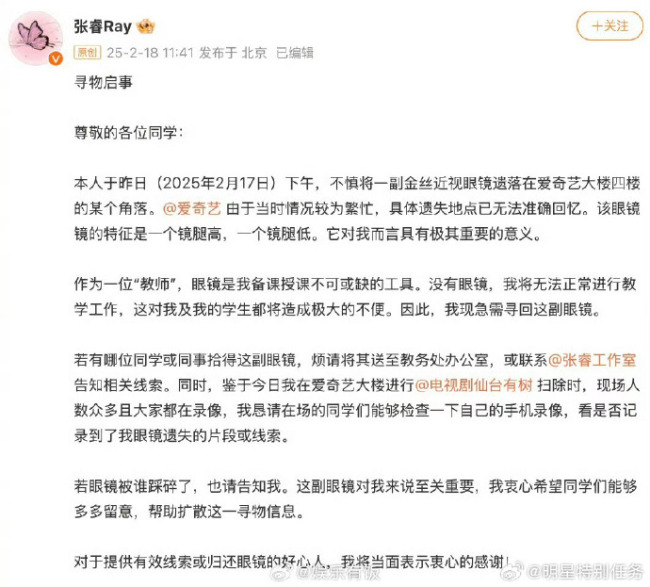
張睿發(fā)尋物啟事找眼鏡,,張睿沒眼鏡上不了課

三亞招募100名旅游體驗(yàn)官 提升服務(wù)質(zhì)量與游客滿意度
相關(guān)新聞
DeepSeek引發(fā)美股拋售潮 科技股重挫
2025-01-28 10:40:35DeepSeek引發(fā)美股拋售潮英偉達(dá)回應(yīng)股價(jià)遭DeepSeek暴擊 TTS的完美范例
2025-01-28 08:57:28英偉達(dá)回應(yīng)股價(jià)遭DeepSeek暴擊DeepSeek美股泡沫得以延續(xù) 挑戰(zhàn)硅谷霸權(quán)
2025-02-04 19:33:47DeepSeek美股泡沫得以延續(xù)DeepSeek讓美國(guó)有些人詫異了 沖擊美股科技板塊
2025-01-28 16:26:41DeepSeek讓美國(guó)有些人詫異了DeepSeek一夜掀翻美股 挑戰(zhàn)科技巨頭主導(dǎo)地位
2025-01-28 09:12:00DeepSeek一夜掀翻美股DeepSeek崛起沖擊美股 英偉達(dá)股價(jià)大跌17%
2025-01-28 07:17:05美股








