實(shí)測(cè)DeepSeek深度思考模式 低成本高效挑戰(zhàn)OpenAI

當(dāng)硅谷仍在為GPU萬(wàn)卡集群投入巨額資金時(shí),,來(lái)自杭州的一群年輕人用557.6萬(wàn)美元證明,,AI大模型的競(jìng)爭(zhēng)并不只依賴(lài)規(guī)模,,更看重使用效率,。一款上架不到半個(gè)月的應(yīng)用程序DeepSeek在1月27日登頂蘋(píng)果應(yīng)用商店排行榜,,擊敗了ChatGPT,。
最近幾天,,AI領(lǐng)域最火的大語(yǔ)言模型不是ChatGPT或文心一言,,而是杭州AI公司深度求索推出的DeepSeek。從去年12月26日發(fā)布的DeepSeek-V3到1月20日的DeepSeek-R1,,這家公司以O(shè)penAI三十分之一的價(jià)格實(shí)現(xiàn)了與o1模型相當(dāng)甚至超越的成績(jī),,給美國(guó)AI行業(yè)帶來(lái)了不小的沖擊。
經(jīng)過(guò)同題問(wèn)答測(cè)試,,DeepSeek-R1通過(guò)步步推理生成了具有邏輯性的回答,,用戶(hù)可以看到其思考過(guò)程。IT從業(yè)者劉鴻博表示,,這種體驗(yàn)與第一次使用ChatGPT 3.5相似,,甚至更加震撼。他認(rèn)為DeepSeek對(duì)高語(yǔ)境內(nèi)容和中文網(wǎng)絡(luò)梗的理解能力更強(qiáng),,達(dá)到了脫口秀文本的水平,。
DeepSeek-R1發(fā)布后,不少美國(guó)AI從業(yè)者在社交平臺(tái)上表達(dá)了內(nèi)心的震撼,。面對(duì)成本僅為“零頭”但性能優(yōu)秀的大模型,,許多人發(fā)現(xiàn)傳統(tǒng)的高投入模式已無(wú)法阻止用戶(hù)的選擇。北京時(shí)間1月27日,,DeepSeek在美國(guó),、中國(guó)和英國(guó)的App Store免費(fèi)應(yīng)用下載榜上名列前茅。
根據(jù)官方公布的性能測(cè)試,,DeepSeek在數(shù)學(xué)測(cè)試,、編程等多個(gè)領(lǐng)域與o1模型表現(xiàn)旗鼓相當(dāng),在某些測(cè)試中還超過(guò)了o1模型,。此外,,DeepSeek的訓(xùn)練成本更低,使用的算力也受到限制,。相比之下,,Meta旗下Llama3.1 405B模型的訓(xùn)練成本超過(guò)6000萬(wàn)美元,,而OpenAI的GPT-4o模型的訓(xùn)練成本為1億美元,。
DeepSeek的價(jià)格優(yōu)勢(shì)早在去年年中就已顯現(xiàn),但由于當(dāng)時(shí)知名度不高,,降價(jià)聲勢(shì)很快被其他大廠蓋過(guò)?,F(xiàn)在,除了價(jià)格優(yōu)勢(shì)外,,DeepSeek還有比肩o1模型的性能,。一些業(yè)內(nèi)人士認(rèn)為,DeepSeek可能顛覆硅谷巨頭的高投入路徑,,對(duì)那些依賴(lài)銷(xiāo)售大量GPU的公司形成挑戰(zhàn),。
在實(shí)際應(yīng)用方面,,DeepSeek的表現(xiàn)同樣令人印象深刻。通過(guò)聯(lián)網(wǎng)搜索功能,,DeepSeek能夠整理出詳細(xì)的事件表,,并展示清晰的思考過(guò)程。日常使用中,,用戶(hù)發(fā)現(xiàn)該模型對(duì)中國(guó)古代文化如生辰八字,、奇門(mén)遁甲等非常熟悉,且展示了專(zhuān)業(yè)的思考過(guò)程,。
DeepSeek之所以能以較低的成本訓(xùn)練出高性能模型,,是因?yàn)樗饤壛藗鹘y(tǒng)的監(jiān)督微調(diào),采用單純的強(qiáng)化學(xué)習(xí)訓(xùn)練,。這一方法不僅減少了計(jì)算資源的需求,,還觀察到了模型的“頓悟時(shí)刻”。在處理復(fù)雜問(wèn)題時(shí),,模型會(huì)重新評(píng)估初步方法并分配更多思考時(shí)間,,顯示出高級(jí)的問(wèn)題解決策略。
DeepSeek團(tuán)隊(duì)由清華大學(xué)和北京大學(xué)的應(yīng)屆生和實(shí)習(xí)生主導(dǎo),,平均年齡不足26歲,。這種自下而上的創(chuàng)新文化與OpenAI早期類(lèi)似。面壁智能首席科學(xué)家劉知遠(yuǎn)認(rèn)為,,DeepSeek的成功證明了通過(guò)有限資源的高效利用可以實(shí)現(xiàn)以少勝多,,縮小了中美在AI領(lǐng)域的差距。未來(lái)發(fā)展路徑尚不明確,,仍需百倍努力探出新路,。

美航司客機(jī)事故乘客拍下逃生瞬間 加拿大:事發(fā)時(shí)風(fēng)力強(qiáng)勁

私家車(chē)占人行道家長(zhǎng)擔(dān)憂(yōu)孩子走車(chē)道 社區(qū)回應(yīng):將安裝U型桿或石球

觀察:2025年的Mini LED電視市場(chǎng),怎么打,? 三大競(jìng)爭(zhēng)焦點(diǎn)浮現(xiàn)

哪吒2主創(chuàng)團(tuán)隊(duì)已進(jìn)入新創(chuàng)作周期 續(xù)寫(xiě)神話(huà)新篇章
媒體批特朗普又一次“搶劫”臺(tái)灣 美國(guó)的真實(shí)意圖暴露

拉夫羅夫抵達(dá)沙特 單手揣兜下飛機(jī) 談判桌上的博弈

美客機(jī)翻覆現(xiàn)場(chǎng)視頻曝光 惡劣天氣或成事故主因

武漢一培訓(xùn)機(jī)構(gòu)請(qǐng)千名學(xué)生看哪吒2 放松身心緩解壓力
光線(xiàn)傳媒再度巨震 高位人氣股走弱

申公豹的結(jié)巴能矯正嗎 口吃并非無(wú)法改善

黑中介騙取巨額服務(wù)費(fèi)被公訴 虛假承諾誘騙客戶(hù)
馬斯克坐實(shí)AI游戲工作室計(jì)劃 讓游戲再次偉大

為了增加軍費(fèi),,英國(guó)公共服務(wù)部門(mén)被曝準(zhǔn)備削減11%的預(yù)算,歐洲派兵計(jì)劃陷入僵局

伊朗:反對(duì)外國(guó)勢(shì)力干涉敘利亞 支持?jǐn)⑷嗣褡詻Q權(quán)

美國(guó)新版“空軍一號(hào)”再度延期交付 供應(yīng)鏈問(wèn)題拖累進(jìn)度

美為何提議從中國(guó)向?yàn)跖汕簿S和人員 美國(guó)的奇葩主意

烏方將不承認(rèn)美俄談判達(dá)成的協(xié)議 澤連斯基堅(jiān)決立場(chǎng)

三亞招募100名旅游體驗(yàn)官 提升服務(wù)質(zhì)量與游客滿(mǎn)意度
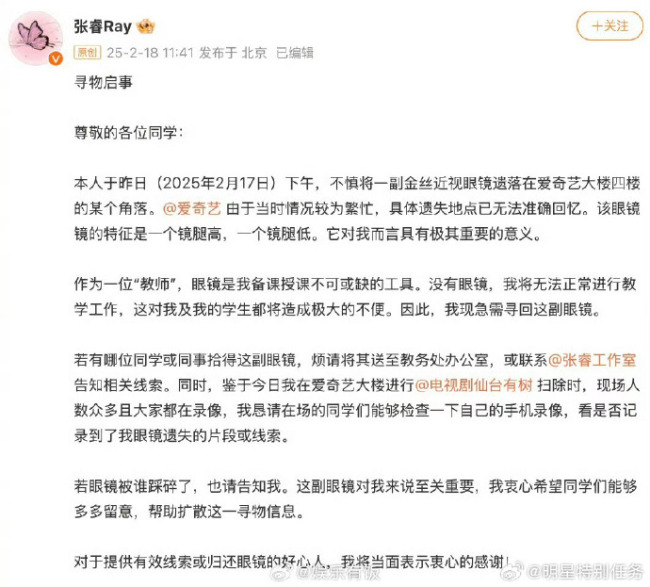
張睿發(fā)尋物啟事找眼鏡,,張睿沒(méi)眼鏡上不了課
觀察:2025年的Mini LED電視市場(chǎng),怎么打,? 三大競(jìng)爭(zhēng)焦點(diǎn)浮現(xiàn)
私家車(chē)占人行道家長(zhǎng)擔(dān)憂(yōu)孩子走車(chē)道 社區(qū)回應(yīng):將安裝U型桿或石球

特朗普批波音總統(tǒng)專(zhuān)機(jī)還沒(méi)造好 項(xiàng)目拖延引不滿(mǎn)

澤連斯基將到訪(fǎng)沙特 不參與美俄會(huì)談
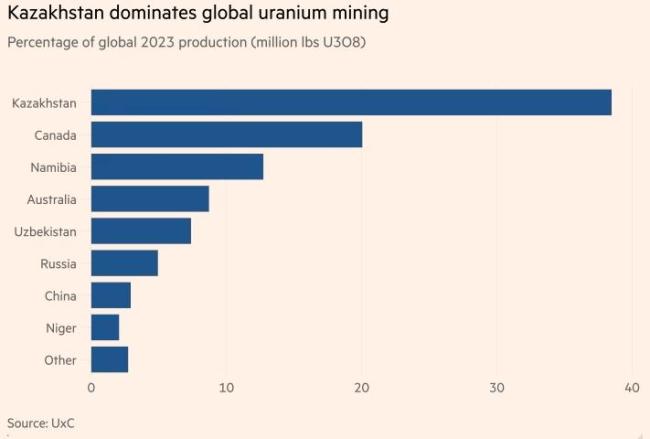
哈薩克斯坦鈾出口重心東移 哈鈾售中俄后致歐美快斷供了
美俄談判今日開(kāi)始 澤連斯基:不承認(rèn) 烏克蘭缺席引發(fā)爭(zhēng)議

歐洲的安全,,還是美國(guó)的利益?美俄談判前夕,,歐洲被邊緣化引發(fā)擔(dān)憂(yōu)

今日雨水節(jié)氣,,老傳統(tǒng)“吃二樣,做二事,,忌二事” 千年習(xí)俗的智慧

大V:歐洲和烏克蘭遭受三次沉重打擊 西方暴露三大問(wèn)題
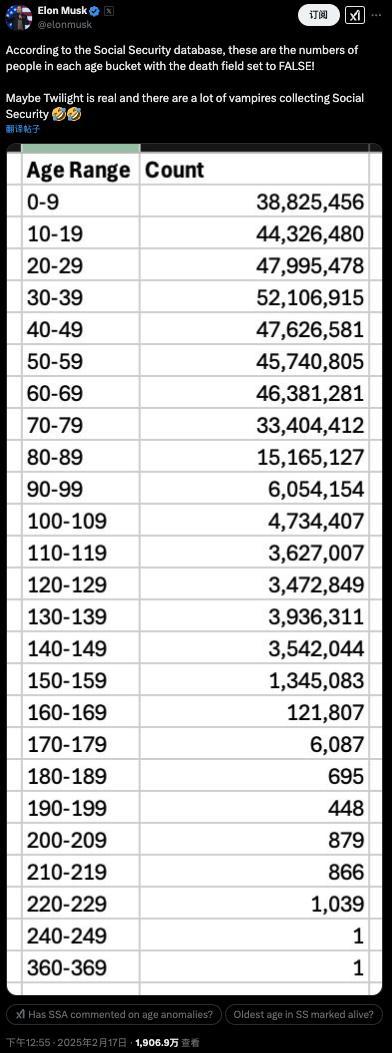
馬斯克查賬“美國(guó)社?!?,稱(chēng)發(fā)現(xiàn)360歲老人?
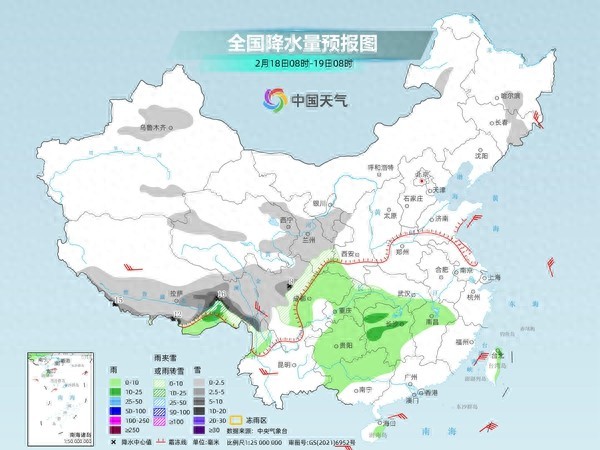
未來(lái)三天南方陰雨濕冷感明顯 北方降水增多
美航司客機(jī)事故乘客拍下逃生瞬間 加拿大:事發(fā)時(shí)風(fēng)力強(qiáng)勁

以民眾持續(xù)抗議要求政府維持?;?呼吁釋放被扣押人員

美國(guó)翻臉后,歐洲從“夸夸其談的少年”走向獨(dú)立成熟要做三件事 應(yīng)對(duì)三大危機(jī)

曝王大陸涉嫌逃兵役被捕

網(wǎng)紅高收入合理嗎,?顧茜茜稱(chēng)每天躺賺30萬(wàn)是氣話(huà)
相關(guān)新聞
Copilot開(kāi)放“深度思考”模式 全民免費(fèi)體驗(yàn)
Microsoft AI 公司首席執(zhí)行官穆斯塔法?蘇萊曼宣布,,所有 Microsoft Copilot 用戶(hù)現(xiàn)在可以免費(fèi)使用 OpenAI 的 o1 推理模型
2025-01-31 18:42:10Copilot開(kāi)放深度思考模式實(shí)測(cè)DeepSeek做奧數(shù)題寫(xiě)作文 DeepSeek火爆全球
2025-01-27 20:13:31實(shí)測(cè)DeepSeek做奧數(shù)題寫(xiě)作文“木頭姐”談DeepSeek啟示 創(chuàng)新訓(xùn)練方法啟發(fā)思考
2025-02-01 15:57:07木頭姐談DeepSeek啟示當(dāng)我問(wèn)DeepSeek能否幫做寒假作業(yè) AI代寫(xiě)引發(fā)教育思考
2025-02-09 17:06:16當(dāng)我問(wèn)DeepSeek能否幫做寒假作業(yè)DeepSeek 越強(qiáng)大,,我就越容易變蠢,? 思考能力的喪失陷阱
2025-02-17 13:29:10DeepSeek越強(qiáng)大2025款極氪007城區(qū)NZP通勤模式實(shí)測(cè) 智能化短板補(bǔ)齊
2024-08-14 12:16:342025款極氪007城區(qū)NZP通勤模式實(shí)測(cè)








