DeepSeek帶飛國內(nèi)AI大模型概念股 低成本訓(xùn)練引關(guān)注

今日A股市場迎來龍年收官戰(zhàn),,三大指數(shù)走勢分化明顯。收盤時,,滬指跌0.06%,,創(chuàng)業(yè)板指跌2.73%,收報2063.82點,。滬深兩市成交額達(dá)到11179億元,,較上周五縮量1041億。
值得注意的是,,DeepSeek概念股領(lǐng)漲,,AI智能體、AI語料等概念股表現(xiàn)強(qiáng)勁,。與此同時,,算力板塊的銅高速連接、CPO等方向則紛紛領(lǐng)跌,,仕佳光子跌超16%,,兆龍互連、天孚通信等跌超10%,。
上述現(xiàn)象主要源于國產(chǎn)大模型DeepSeek在美區(qū)App Store免費榜登頂,,并在國內(nèi)App Store免費榜同樣位居第一。DeepSeek和ChatGPT躋身美區(qū)App Store免費榜前三,,展現(xiàn)出中國應(yīng)用程序的影響力,。DeepSeek推理大模型DeepSeek-R1發(fā)布已近一周,開源模型DeepSeek-V3也已發(fā)布近一個月,。DeepSeek-V3僅用2048塊H800 GPU完成6710億參數(shù)模型訓(xùn)練,,成本僅為557.6萬美元,,遠(yuǎn)低于其他頂級模型如GPT-4的10億美元。
受此利好影響,,國內(nèi)DeepSeek概念股受到追捧,,相關(guān)股東和合作伙伴也被市場挖掘出來炒作。AI大模型領(lǐng)域近年來吸引了大量資本投入,,盡管性能上取得了突破,,但仍面臨技術(shù)瓶頸與應(yīng)用落地方面的挑戰(zhàn)。大模型訓(xùn)練需要巨額算力支持,,當(dāng)前市場中算力資源的過剩使得成本問題凸顯。國際競爭與政策影響進(jìn)一步加劇了AI產(chǎn)業(yè)鏈的不確定性,。AI應(yīng)用后期的投資機(jī)會廣泛且多樣,,從算力基礎(chǔ)設(shè)施到行業(yè)應(yīng)用,再到生成式AI和端側(cè)AI,,均展現(xiàn)出強(qiáng)勁的增長潛力,。
1月25日,AMD宣布全新的DeepSeek-V3模型已集成至其Instinct GPU上,。DeepSeek-V3模型的突破顯著降低了AI培訓(xùn)成本,,使AMD GPU成為比英偉達(dá)更具成本效益的替代品。這一消息導(dǎo)致國內(nèi)A股市場算力硬件股持續(xù)走低,,銅高速連接,、CPO等方向領(lǐng)跌,仕佳光子跌超16%,,兆龍互連,、天孚通信等跌超10%。
OpenAI的成功在于規(guī)模制勝,,但這種模式帶來了高昂的訓(xùn)練成本,,不少公司難以承受。臉書母公司Meta成立了四個專門研究小組來研究量化巨頭幻方量化旗下的國產(chǎn)大模型DeepSeek的工作原理,,并基于此改進(jìn)旗下大模型Llama,。
黑崎資本首席戰(zhàn)略官陳興文指出,DeepSeek的低成本意味著未來對推理算力的需求將成為主要驅(qū)動力,,而英偉達(dá)等硬件商的傳統(tǒng)優(yōu)勢更多集中在訓(xùn)練側(cè),,這可能對其市場地位和戰(zhàn)略布局產(chǎn)生影響。DeepSeek通過MIT協(xié)議開源8個核心模型并全鏈路公開訓(xùn)練細(xì)節(jié),,打破了閉源體系的技術(shù)壟斷,,通過全球開發(fā)者社區(qū)的協(xié)同創(chuàng)新形成指數(shù)級迭代能力。這種開源策略直接顛覆了硅谷“算力軍備競賽”邏輯,。
DeepSeek通過囤積高端芯片與優(yōu)化低性能芯片組合的雙軌策略,,結(jié)合強(qiáng)化學(xué)習(xí)替代監(jiān)督微調(diào)的技術(shù)突破,,成功將硬件約束轉(zhuǎn)化為算法創(chuàng)新驅(qū)動力。這種逆境突圍重新定義了全球AI競爭格局,,催生產(chǎn)業(yè)鏈價值重構(gòu),。在算力基建層面,數(shù)據(jù)中心向綠色高效轉(zhuǎn)型,,特定領(lǐng)域的行為數(shù)據(jù)、專業(yè)語料庫成為模型優(yōu)化的戰(zhàn)略資源,,驅(qū)動數(shù)據(jù)采集、清洗,、標(biāo)注產(chǎn)業(yè)升級,。更深遠(yuǎn)的影響體現(xiàn)在AI應(yīng)用生態(tài):開源模型大幅降低技術(shù)準(zhǔn)入門檻,使得中小企業(yè)能快速部署輕量化應(yīng)用,,加速AI能力向物聯(lián)網(wǎng)終端滲透,。
當(dāng)前全球算力市場正陷入“結(jié)構(gòu)性過剩與短缺并存”的困境。中國市場中,,大量跨界資本涌入智算中心建設(shè),,導(dǎo)致2024年全國建成超1.3萬個智算中心,但平均利用率不足30%,,千卡集群年虧損達(dá)2700萬元。這種過剩本質(zhì)上是低端算力的盲目擴(kuò)張與高端智能算力短缺的疊加結(jié)果,。實際需求端,,大模型訓(xùn)練所需的智能算力缺口達(dá)53%,技術(shù)迭代速度遠(yuǎn)超硬件建設(shè)周期,,設(shè)備貶值率超40%,。
DeepSeek僅用2048塊H800顯卡、557萬美元成本便訓(xùn)練出性能對標(biāo)GPT-4的模型,,通過MLA架構(gòu)和強(qiáng)化學(xué)習(xí)飛輪機(jī)制,,將訓(xùn)練效率提升至Meta Llama3的11倍,百萬Token推理成本壓至0.55美元(僅為OpenAI的3.6%),。這種“算法優(yōu)化對沖硬件約束”的模式,,不僅證明尖端AI發(fā)展無需依賴無限堆砌算力,更動搖了美國技術(shù)霸權(quán)的根基,。
DeepSeek的崛起被稱為“美股最大威脅”,,源于其對美國AI商業(yè)邏輯與芯片霸權(quán)的雙重解構(gòu),。技術(shù)層面,,其開源策略形成全球開發(fā)者協(xié)同創(chuàng)新的“開源飛輪”,,吸引Meta,、Google工程師反向研究其RL技術(shù)框架。產(chǎn)業(yè)層面,,其通過算法創(chuàng)新削弱了英偉達(dá)高端GPU的不可替代性,引發(fā)英偉達(dá)股價單日暴跌5.8%,,連帶日本芯片測試設(shè)備商Advantest市值蒸發(fā)8.6%,。地緣博弈層面,,DeepSeek驗證了中國AI企業(yè)“用架構(gòu)創(chuàng)新壓縮技術(shù)代差”的可能性,,紐約時報評價其“使美國芯片封鎖淪為戰(zhàn)略敗筆”。
這場變革的本質(zhì)是AI競爭從“資本密集型”向“創(chuàng)新密集型”的范式遷移,。短期算力過剩實則是低端產(chǎn)能出清的前奏,,DeepSeek的技術(shù)路徑預(yù)示未來算力市場將兩極分化:通用算力加速淘汰,智能算力向算法優(yōu)勢企業(yè)集中,。

私家車占人行道家長擔(dān)憂孩子走車道 社區(qū)回應(yīng):將安裝U型桿或石球

觀察:2025年的Mini LED電視市場,,怎么打,? 三大競爭焦點浮現(xiàn)

曝王大陸涉嫌逃兵役被捕

黑中介騙取巨額服務(wù)費被公訴 虛假承諾誘騙客戶

大V:歐洲和烏克蘭遭受三次沉重打擊 西方暴露三大問題
曝王大陸涉嫌逃兵役被捕

今日雨水節(jié)氣,老傳統(tǒng)“吃二樣,,做二事,,忌二事” 千年習(xí)俗的智慧
馬斯克坐實AI游戲工作室計劃 讓游戲再次偉大

哪吒2主創(chuàng)團(tuán)隊已進(jìn)入新創(chuàng)作周期 續(xù)寫神話新篇章
觀察:2025年的Mini LED電視市場,怎么打,? 三大競爭焦點浮現(xiàn)

申公豹的結(jié)巴能矯正嗎 口吃并非無法改善
媒體批特朗普又一次“搶劫”臺灣 美國的真實意圖暴露

網(wǎng)紅高收入合理嗎,?顧茜茜稱每天躺賺30萬是氣話

三亞招募100名旅游體驗官 提升服務(wù)質(zhì)量與游客滿意度
私家車占人行道家長擔(dān)憂孩子走車道 社區(qū)回應(yīng):將安裝U型桿或石球
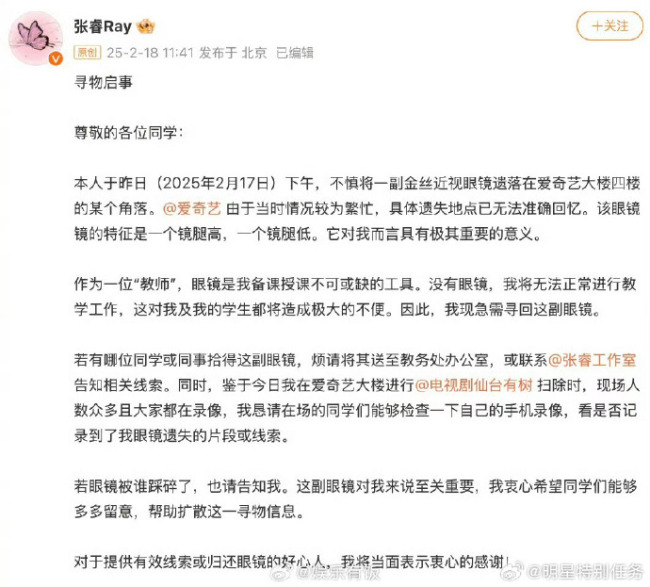
張睿發(fā)尋物啟事找眼鏡,張睿沒眼鏡上不了課

美客機(jī)翻覆現(xiàn)場視頻曝光 惡劣天氣或成事故主因

為了增加軍費,,英國公共服務(wù)部門被曝準(zhǔn)備削減11%的預(yù)算,,歐洲派兵計劃陷入僵局

武漢一培訓(xùn)機(jī)構(gòu)請千名學(xué)生看哪吒2 放松身心緩解壓力
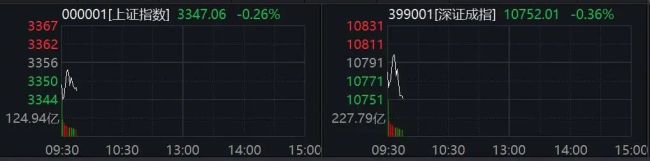
光線傳媒再度巨震 高位人氣股走弱

烏方將不承認(rèn)美俄談判達(dá)成的協(xié)議 澤連斯基堅決立場
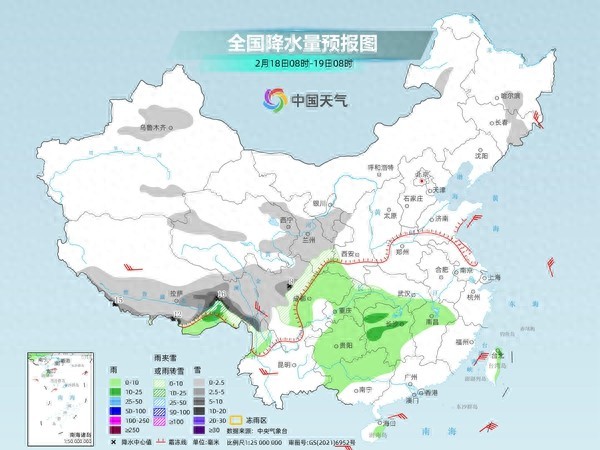
未來三天南方陰雨濕冷感明顯 北方降水增多

美國翻臉后,,歐洲從“夸夸其談的少年”走向獨立成熟要做三件事 應(yīng)對三大危機(jī)

美為何提議從中國向烏派遣維和人員 美國的奇葩主意
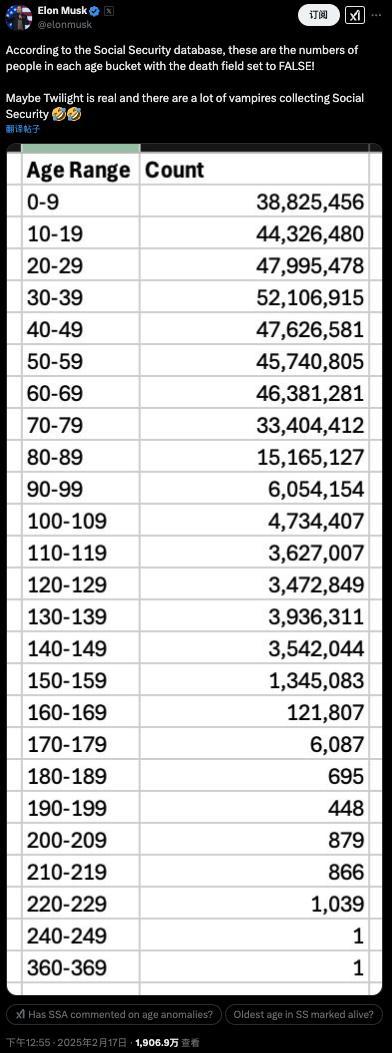
馬斯克查賬“美國社?!保Q發(fā)現(xiàn)360歲老人,?

歐洲的安全,,還是美國的利益?美俄談判前夕,,歐洲被邊緣化引發(fā)擔(dān)憂

賴志光任廣東惠州公安局局長 新任副市長兼公安局長

伊朗:反對外國勢力干涉敘利亞 支持?jǐn)⑷嗣褡詻Q權(quán)
美俄談判今日開始 澤連斯基:不承認(rèn) 烏克蘭缺席引發(fā)爭議

以民眾持續(xù)抗議要求政府維持?;?呼吁釋放被扣押人員

拉夫羅夫抵達(dá)沙特 單手揣兜下飛機(jī) 談判桌上的博弈
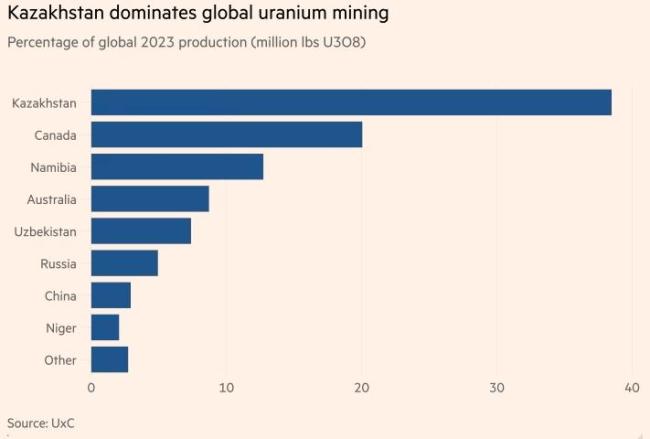
哈薩克斯坦鈾出口重心東移 哈鈾售中俄后致歐美快斷供了

特朗普批波音總統(tǒng)專機(jī)還沒造好 項目拖延引不滿

美國新版“空軍一號”再度延期交付 供應(yīng)鏈問題拖累進(jìn)度

澤連斯基將到訪沙特 不參與美俄會談
相關(guān)新聞
DeepSeek出圈 概念股曝光 AI大模型引爆市場
數(shù)據(jù)是寶貴的資源,,能夠幫助投資者減少煩惱,。中國AI大模型市場正快速發(fā)展。近日,,量化巨頭幻方量化旗下公司DeepSeek發(fā)布了推理大模型DeepSeek-R1
2025-01-27 09:33:36DeepSeek出圈概念股曝光從DeepSeek看AI趨勢 大模型推動算力革命
在ChatGPT掀起全球AI熱潮兩年后,,大模型領(lǐng)域迎來了一位新星——DeepSeek。憑借高性能,、低成本以及完全開源的特點,,DeepSeek迅速吸引了公眾的目光,成為市場上的“鯰魚”
2025-02-14 17:24:33從DeepSeek看AI趨勢美大模型巨頭:DeepSeek沒我們先進(jìn) AI競爭白熱化
2025-02-01 11:20:01美大模型巨頭中國基礎(chǔ)電信運(yùn)營商全面接入DeepSeek 央企加速擁抱AI大模型
2025-02-14 22:25:00中國基礎(chǔ)電信運(yùn)營商全面接入DeepSeek震動科技界!AI領(lǐng)域“黑馬”,,DeepSeek出圈,,概念股曝光 性能比肩頂尖模型
中國AI大模型市場規(guī)模正在快速發(fā)展。近日,,量化巨頭幻方量化旗下公司DeepSeek發(fā)布了推理大模型DeepSeek-R1
2025-01-27 08:58:14震動科技界華為科大訊飛深化大模型合作 共筑國產(chǎn)AI新基石
在華為全聯(lián)接大會期間,,即9月19日至21日,華為與科大訊飛的合作進(jìn)一步升級,,雙方在通用大模型底座的構(gòu)建及應(yīng)用落地方面展現(xiàn)出顯著進(jìn)展
2024-09-24 09:47:04華為科大訊飛深化大模型合作








