業(yè)內(nèi):DeepSeek或準(zhǔn)備適配國(guó)產(chǎn)GPU 繞過(guò)CUDA展現(xiàn)工程實(shí)力

盡管春節(jié)假期已經(jīng)過(guò)半,,但“來(lái)自東方的神秘力量的 DeepSeek”仍在全球范圍內(nèi)引起熱議。各路業(yè)內(nèi)人士從不同角度分析 DeepSeek 的模型和技術(shù),。
韓國(guó) Mirae Asset Securities Research 的一名分析師在 X 撰寫(xiě)長(zhǎng)文分析稱,,這一突破是通過(guò)實(shí)施大量細(xì)粒度優(yōu)化和使用英偉達(dá)的匯編式 PTX 編程實(shí)現(xiàn)的,而非通過(guò) CUDA 中的某些功能,。CUDA 是由英偉達(dá)開(kāi)發(fā)的一種通用編程框架,,允許開(kāi)發(fā)者利用 GPU 進(jìn)行通用計(jì)算。如果 DeepSeek 繞過(guò)了 CUDA,,這說(shuō)明其研發(fā)團(tuán)隊(duì)在大模型訓(xùn)練中采用了不同的技術(shù)路徑,。
對(duì)于程序開(kāi)發(fā)人員來(lái)說(shuō),CUDA 類似于一種高級(jí)語(yǔ)言,,降低了開(kāi)發(fā)難度,,使開(kāi)發(fā)者能夠?qū)W⒂谒惴ㄟ壿嫸鵁o(wú)需過(guò)多考慮硬件執(zhí)行細(xì)節(jié)。例如,,使用高級(jí)語(yǔ)言進(jìn)行變量賦值操作只需一條命令,,而用匯編語(yǔ)言則需要多條指令并理解寄存器、內(nèi)存等概念,。因此,CUDA 便于開(kāi)發(fā)基于 GPU 的算法設(shè)計(jì),。
大模型開(kāi)發(fā)商通?;?CUDA 進(jìn)行研發(fā),因?yàn)?CUDA 已經(jīng)封裝了一些常用函數(shù),,簡(jiǎn)化了開(kāi)發(fā)過(guò)程,。然而,這種通用性也帶來(lái)了一定的靈活性損失,。對(duì)于有特定需求的開(kāi)發(fā)者,,如需要精細(xì)化控制多個(gè) GPU 之間的數(shù)據(jù)傳輸,CUDA 可能無(wú)法提供高效的解決方案,。
當(dāng)使用單個(gè) GPU 時(shí),,CUDA 非常適用。但在多節(jié)點(diǎn)多 GPU 環(huán)境下,,CUDA 的抽象層面效率較低,。開(kāi)發(fā)者可以通過(guò)組合 GPU 驅(qū)動(dòng)提供的函數(shù)接口來(lái)提高效率,或者直接調(diào)用底層硬件接口以實(shí)現(xiàn)更高效的大模型研發(fā),。繞過(guò) CUDA 可以直接根據(jù) GPU 的驅(qū)動(dòng)函數(shù)進(jìn)行新的開(kāi)發(fā),,從而實(shí)現(xiàn)更加細(xì)粒度的操作,。
DeepSeek 在多節(jié)點(diǎn)通信時(shí)繞過(guò)了 CUDA 直接使用 PTX,這使得模型訓(xùn)練速度更快,。這意味著在相同時(shí)間內(nèi)可以處理更多數(shù)據(jù),,間接提高了模型效果。繞過(guò) CUDA 并非新鮮做法,,一些開(kāi)源框架如 Triton 也在嘗試替代 CUDA,。

鹿晗關(guān)注了Sana的ins 粉絲熱議不斷

醫(yī)療主題基金迎戰(zhàn)略機(jī)遇期 AI技術(shù)驅(qū)動(dòng)增長(zhǎng)

1月廈門(mén)維修進(jìn)境飛機(jī)增兩成 航空維修產(chǎn)業(yè)迎“開(kāi)門(mén)紅”

今年雨水不一般,60年一遇,,有3大特點(diǎn),,4大特殊
俄美今日開(kāi)談?wù)勈裁矗繛楹芜x在沙特,?烏歐又在“焦慮”什么,? 烏克蘭問(wèn)題成焦點(diǎn)
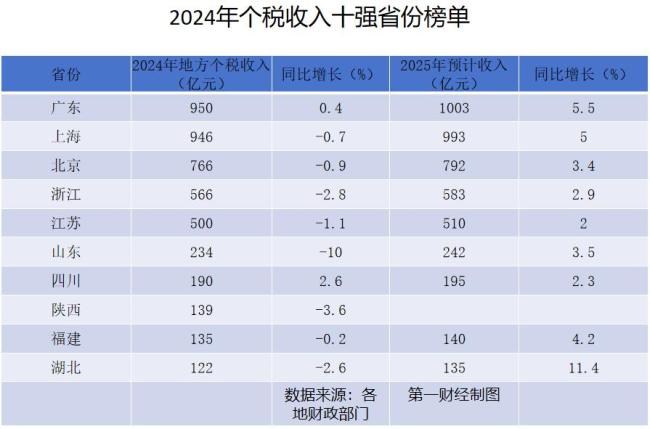
個(gè)稅收入十強(qiáng)省份公布 廣東重奪榜首

哈馬斯一名軍事指揮官在黎南部遭以色列無(wú)人機(jī)襲擊死亡 以軍確認(rèn)行動(dòng)成功

曾被雷軍千萬(wàn)年薪挖角!親屬稱羅福莉與丈夫研究領(lǐng)域相同

外媒:以色列內(nèi)閣投票確認(rèn)扎米爾為下任以軍總參謀長(zhǎng) 即將于3月5日就職

拉夫羅夫抵達(dá)沙特 單手揣兜下飛機(jī) 談判桌上的博弈
1月廈門(mén)維修進(jìn)境飛機(jī)增兩成 航空維修產(chǎn)業(yè)迎“開(kāi)門(mén)紅”

大V:歐洲和烏克蘭遭受三次沉重打擊 西方暴露三大問(wèn)題

哪吒2出現(xiàn)錯(cuò)別字 光線傳媒回應(yīng) 將討論并回復(fù)

本·西蒙斯曬出海釣魚(yú)視頻 快船新旅程開(kāi)啟
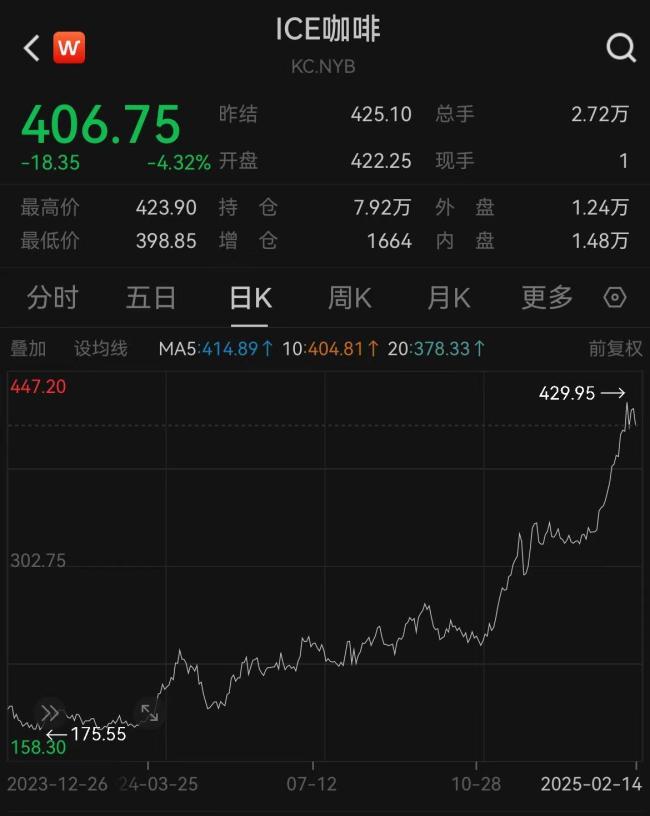
多品牌回應(yīng)咖啡是否漲價(jià) 成本上漲引關(guān)注

CTA與皇馬代表談判罰等議題 友好氛圍中進(jìn)行會(huì)談

王大陸經(jīng)紀(jì)人拒接電話 事件非同小可

17歲小將黃振文首球即完美世界波 華裔新星閃耀澳超

洛杉磯街頭出現(xiàn)科比東契奇巨幅壁畫(huà) 湖人誠(chéng)意打動(dòng)?xùn)|契奇

宇樹(shù)科技創(chuàng)始人王興興曾差點(diǎn)沒(méi)考上高中 從內(nèi)向少年到科技領(lǐng)軍人物

曝知名男星涉嫌逃兵役被捕 王大陸被帶回偵辦

朗普新任期將滿月:政策落地遇阻,,全球市場(chǎng)格局生變

外援斯蒂爾再度控訴NBL江西男籃欠薪 薪水拖延問(wèn)題持續(xù)發(fā)酵

美為何提議從中國(guó)向?yàn)跖汕簿S和人員 美國(guó)的奇葩主意

特朗普上一任期讓做的專機(jī)至今沒(méi)好 項(xiàng)目拖延引不滿

特朗普批波音:總統(tǒng)專機(jī)怎么還沒(méi)造好 項(xiàng)目拖延引不滿

美政府裁員引發(fā)抗議 改革浪潮爭(zhēng)議不斷
醫(yī)療主題基金迎戰(zhàn)略機(jī)遇期 AI技術(shù)驅(qū)動(dòng)增長(zhǎng)

美方:烏克蘭能“上桌”談判 歐洲被排除引發(fā)爭(zhēng)議
媒體批特朗普又一次“搶劫”臺(tái)灣 美國(guó)的真實(shí)意圖暴露

0日將允許戶籍欄登記可填“臺(tái)灣” 外交部敦促 恪守一個(gè)中國(guó)原則

美國(guó)東部8州遭洪災(zāi)影響上億人,?肯塔基緊急狀態(tài),真有這么嚴(yán)重嗎 致命風(fēng)暴致8人死亡
鹿晗關(guān)注了Sana的ins 粉絲熱議不斷
陳曉陳妍希官宣離婚 感恩遇見(jiàn)各自安好
下賽季全明星周末或?qū)⒁雴翁糍?巨星積極響應(yīng)
相關(guān)新聞
業(yè)內(nèi)稱A股仍面臨嚴(yán)峻考驗(yàn) ,!
2025-01-06 15:42:45業(yè)內(nèi)稱A股仍面臨嚴(yán)峻考驗(yàn)業(yè)內(nèi):取消公攤計(jì)價(jià)模式是大勢(shì)所趨
2024-12-16 10:09:22取消公攤計(jì)價(jià)模式是大勢(shì)所趨業(yè)內(nèi)稱2025年金價(jià)仍存上行空間
2025-01-07 16:11:45業(yè)內(nèi)稱2025年金價(jià)仍存上行空間業(yè)內(nèi):市場(chǎng)進(jìn)入“慢?!毙星?穩(wěn)中求進(jìn)
2024-11-16 11:28:50業(yè)內(nèi):市場(chǎng)進(jìn)入“慢?!毙星?/span>最新消息!業(yè)內(nèi)解析A股本輪階段性調(diào)整
11月13日以來(lái),,A股經(jīng)歷階段性調(diào)整,,各指數(shù)與行業(yè)板塊呈現(xiàn)普跌態(tài)勢(shì),市場(chǎng)整體觀望情緒加重,。
2024-11-25 09:42:30業(yè)內(nèi)解析A股本輪階段性調(diào)整業(yè)內(nèi):短線A股走勢(shì)漸漸樂(lè)觀起來(lái)
周三A股市場(chǎng)出現(xiàn)探底回升的態(tài)勢(shì),。
2024-11-28 09:03:11業(yè)內(nèi):短線A股走勢(shì)漸漸樂(lè)觀起來(lái)








