震動全球AI圈的DeepSeek究竟是個啥 中國創(chuàng)新企業(yè)的崛起

在科技浪潮中,,人工智能領域不斷涌現(xiàn)出引領時代變革的創(chuàng)新力量。DeepSeek作為其中一顆璀璨的新星,,憑借其卓越的技術實力與創(chuàng)新理念,迅速在全球范圍內引起廣泛關注,。
DeepSeek是一家致力于追求通用人工智能(AGI)的中國創(chuàng)新企業(yè),,自2023年成立以來,迅速在行業(yè)內嶄露頭角,。公司總部位于杭州,,并在北京設有研發(fā)中心,匯聚了來自全球的頂尖人工智能人才,,致力于打造更強大,、更接近人類思維模式的AI技術。
近期,,DeepSeek推出了備受矚目的DeepSeek-R1大模型,,在人工智能領域引發(fā)強烈反響。2025年1月27日,,該模型在中國區(qū)和美區(qū)蘋果App Store免費榜上均榮登榜首,,成功超越多家美國科技巨頭旗下的生成式AI產(chǎn)品。這一成績不僅彰顯了DeepSeek的技術實力與產(chǎn)品競爭力,,也標志著中國AI技術在國際舞臺上邁出堅實一步,。
DeepSeek的技術底蘊深厚,在模型架構與算法層面實現(xiàn)了多項突破性創(chuàng)新,。以DeepSeek-V3模型為例,,其采用了混合專家(MoE)架構,提出動態(tài)偏置調整機制,,實現(xiàn)無輔助損失負載均衡策略,。每個MoE層配置了1個共享專家與256個路由專家,每個token能激活8個專家,,極大提升了模型的學習效率與靈活性,。此外,DeepSeek-V3還采用了多頭潛在注意力(MLA)技術,,通過低秩壓縮技術顯著減少推理時鍵值緩存內存占用,,保持卓越性能的同時大幅降低成本。
DeepSeek-R1模型更是代表了技術創(chuàng)新的巔峰之作,。在數(shù)學,、代碼、自然語言推理等核心任務領域,,DeepSeek-R1的表現(xiàn)與OpenAI的GPT-4o不相上下,,甚至在某些方面更勝一籌。其訓練成本僅為GPT-4o的十分之一,,約557.6萬美元,。DeepSeek-R1在后訓練階段大規(guī)模應用強化學習技術,,僅依靠少量標注數(shù)據(jù)實現(xiàn)了推理能力的飛躍提升。這種獨特的訓練方式展示了強大的優(yōu)勢與潛力,。

巴薩重回西甲榜首 萊萬點射助力登頂

巴爾德:對伊尼戈的犯規(guī)明顯是點球 裁判爭議再現(xiàn)

記者應該怎么用DeepSeek 真幫手還是挖坑俠,?

“重大轉變”!俄羅斯與北約演習,!外媒:白宮首次明確表態(tài),,烏將獲準坐在桌旁 烏克蘭參與和平談判

美國務卿改口徑 短暫刪除“不支持臺獨”引發(fā)爭議
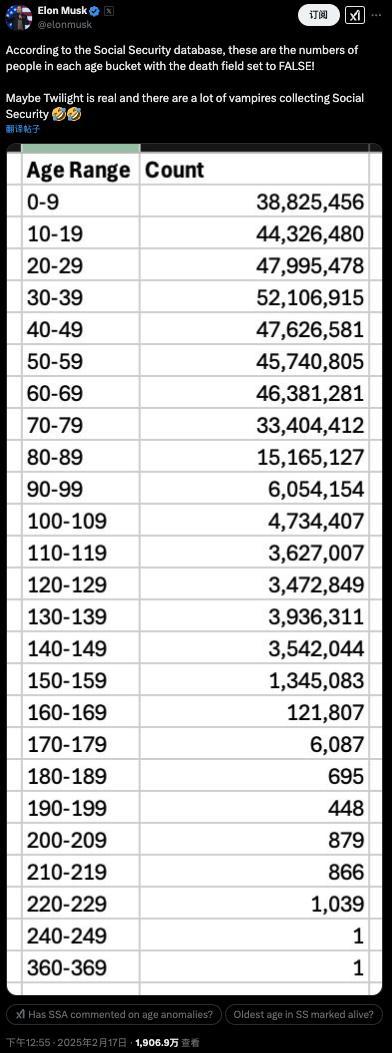
馬斯克查賬美國社保稱發(fā)現(xiàn)360歲老人 馬斯克曝光美國社保系統(tǒng)驚人漏洞

遼籃兩將離開國家隊絕非壞事 楊鳴終于等來他想要的:調整與機遇并存

DeepSeek后又一杭州企業(yè)被美國盯上 杭州科創(chuàng)企業(yè)再遭美國打壓!

烏爾善用18個月拍攝封神三部曲 期待觀眾支持續(xù)作

烏克蘭代表團抵達沙特 為澤連斯基訪問做準備

外電:歐洲人“只是自己命運的旁觀者” 無力參與談判決策

奶奶給孫女縫結界獸套裝回頭率爆表 巧手奶奶還原度滿分

“一年雨水看雨水”今年雨水多不多,?春雨貴如油
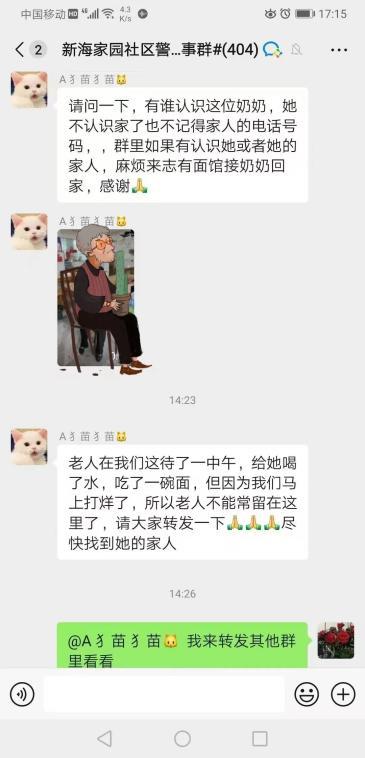
老人迷路后走進面館 老板娘暖心送熱水面條 溫情舉動獲贊

緬甸政府軍與德昂軍進行會談期間,,瑙丘地區(qū)戰(zhàn)事激烈,會談期間戰(zhàn)火未息
巴薩重回西甲榜首 萊萬點射助力登頂

臺名嘴:特朗普面對中國無計可施

雨水時節(jié):祛濕健脾,疏肝理氣正當時 調養(yǎng)脾胃迎春來
迪麗熱巴旗袍造型好清新 綠意盎然顯氣質

馬斯克為何敢整治美政府部門 AI引領政府效率革命

庫爾斯克決戰(zhàn)在即,,烏軍掌握頓巴斯低空優(yōu)勢,,欲斷俄軍前線補給 機械化突擊行動升級

美國為何盯上烏克蘭稀土資源 地緣博弈與資源攫取

加拿大出事客機艙內畫面曝光 乘客倒掛逃生

男性1.5米就能參軍,色盲也能報名,,臺軍新征兵標準有多離譜
巴爾德:對伊尼戈的犯規(guī)明顯是點球 裁判爭議再現(xiàn)

專家:澤連斯基欲鏟除波羅申科 為選舉清除障礙

交易員拋售歐洲債券買入國防股 歐洲增加安全支出利好軍工股

金賽綸之死和韓娛的結構性絞殺 天才童星的隕落

吉利汽車1月零售量同比增長28.2% 新能源車助力顯著

烏方不承認美俄談判達成協(xié)議,,強調自身主權立場

馬斯克曝光美國公務員薪資細節(jié) 引爆“數(shù)據(jù)核彈”

未來馳援國足 國青?17歲華裔新星世界波斬澳超首球,!本人愿歸化 潛力無限待綻放

95歲爺爺拄著拐杖給孫女送菜

美國客機機身翻覆已造成15人受傷 惡劣天氣成事故主因
記者應該怎么用DeepSeek 真幫手還是挖坑俠,?
相關新聞
令硅谷如坐針氈的DeepSeek前路何方 引發(fā)全球科技震動
2025-02-02 09:09:35令硅谷如坐針氈的DeepSeek前路何方DeepSeek暴擊美股 引發(fā)全球AI界關注
2025-01-27 16:51:35DeepSeek暴擊美股反制裁觸及冰山之下,!中國又一“Deepseek時刻”,馬斯克:這只是開始 AI新局引發(fā)全球震動
2025-02-18 08:17:06反制裁觸及冰山之下DeepSeek風暴席卷AI產(chǎn)業(yè)鏈 改變全球科技格局
蛇年除夕夜,,硅基流動創(chuàng)始人袁進輝沒有留在飯桌上,,而是抓緊時間與技術團隊開會,解決DeepSeek模型在國產(chǎn)芯片上的適配問題
2025-02-16 09:01:22DeepSeek風暴席卷AI產(chǎn)業(yè)鏈DeepSeek為何引發(fā)全球轟動 中國AI趕超美國
中國AI初創(chuàng)公司深度求索(DeepSeek)在短短一個月內發(fā)布了兩款大模型:DeepSeek-V3和DeepSeek-R1
2025-01-27 19:35:39DeepSeek為何引發(fā)全球轟動DeepSeek創(chuàng)始人或躋身全球富豪榜 AI估值引熱議
2025-02-11 11:32:16DeepSeek創(chuàng)始人或躋身全球富豪榜








