硅谷大廠相繼宣布加強AI智算中心建設 追求大算力競賽

北京時間2月7日,,Open AI宣布正在評估哪些地區(qū)適合作為“星際之門”項目的數(shù)據(jù)中心所在地,,表明該項目正在繼續(xù)推進,。在一次面向媒體的電話會議上,,首席全球事務官克里斯·萊恩表示,,隨著DeepSeek的消息傳出,,這表明這是一場非常真實的競爭,,并且事關重大,,將決定未來世界的走向,。

OpenAI表示,星際之門的第一座數(shù)據(jù)中心已經在美國德克薩斯州落地,,公司正尋求在美國國內建設更多AI智算中心,。目前有16個州對該項目感興趣。官方公告指出,,該計劃將在促進AI發(fā)展的同時創(chuàng)造數(shù)以千計的新增就業(yè)機會,,并推動美國部分地區(qū)的再工業(yè)化,。星際之門項目于2025年1月宣布,最初由OpenAI,、軟銀和甲骨文三家公司投資1000億美元,,此后4年將陸續(xù)投資共計4000億美元,用于在美國本土建設AI基礎設施,。
與此同時,,微軟、谷歌,、亞馬遜等云計算大廠也在2025年加大了資本開支,。谷歌預計2025年的資本開支增長超過40%,達到750億美元,;Meta的資本開支增長超過60%,,可能達到650億美元;微軟的資本開支增長超過80%,,達到800億美元,;亞馬遜的資本開支增長超過35%,達到1050億美元,。這些增加的資本開支主要用于打造AI智算中心為代表的AI基礎設施,,符合追求大算力的縮放定律邏輯。
縮放定律是Open AI在2020年提出的觀點,,即AI大模型性能會隨著模型參數(shù)量,、訓練數(shù)據(jù)量和計算資源的增加而提升。然而,,近期縮放定律受到了質疑,。前Open AI首席科學家伊爾亞·蘇茨克維表示,全球訓練數(shù)據(jù)量正在耗盡,,這意味著無法通過擴大訓練數(shù)據(jù)量來大幅提升AI大模型性能,。當可訓練數(shù)據(jù)放緩或停止時,即使增加計算資源和模型參數(shù),,模型性能提升也有限,。
同樣挑戰(zhàn)縮放定律的是DeepSeek V3/R1模型。該模型具備低成本和高性能特點,,V3模型訓練成本不到600萬美元,,這讓行業(yè)開始懷疑大規(guī)模投資算力是否有效。艾媒咨詢首席分析師張毅認為,,市場對算力的態(tài)度將回歸相對冷靜的狀態(tài)。不過,,Arm CEO雷內·哈斯表示,,盡管DeepSeek對于AI產業(yè)鏈是一大利好,,但這還不足夠。他認為,,云計算大廠紛紛在2025年增加資本開支,,表明我們仍處于AI浪潮的早期階段,更強大的AI所帶來的革命性能力仍在孕育之中,。
中信建投近期研報認為,,盡管縮放定律受到技術、算力,、數(shù)據(jù)影響遭遇瓶頸,,但強大的AI基礎模型仍然是各廠商未來追求的主要方向。Omdia分析師王珅認為,,縮放定律代表的大算力訓練出更好模型的邏輯依舊成立,。他同時表示,DeepSeek代表著一個輕量,、高性價比,、專注深化AI能力的探索方向,而星際之門則代表著高算力的方向,。這兩種方向在未來的發(fā)展變化還需時間觀察,。如果行業(yè)偏向于探索DeepSeek的方向,這可能會對原本高算力高投資的基礎邏輯形成一些沖擊,,大規(guī)模AI智算中心建設將會減速,。

特朗普上任半月多帶來了哪些沖擊 政策受阻與國際反彈

突發(fā)訃告!北京足球名宿谷大泉去世 曾率北京女足全運會奪金 享年69歲
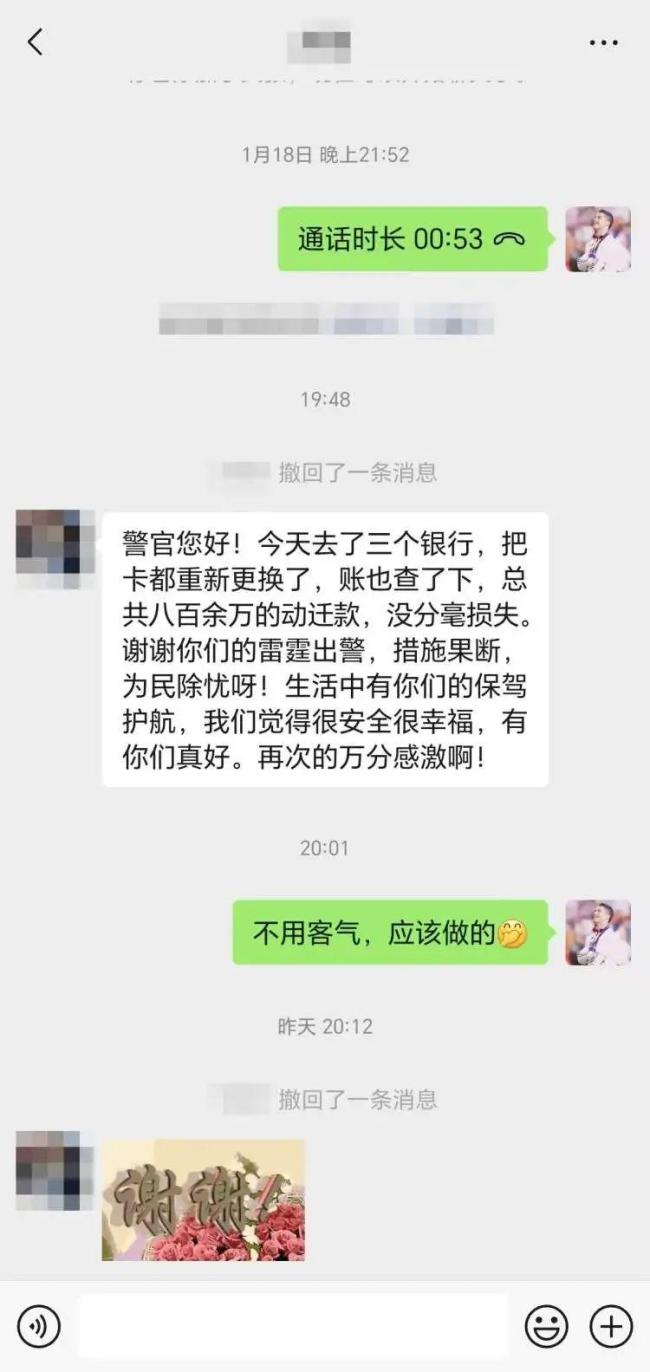
民警一把奪下手機保住老人千萬元存款 警民攜手智斗詐騙分子
為美聯(lián)儲持續(xù)按兵不動“蓋章”,?美國1月非農數(shù)據(jù)依舊穩(wěn)健 就業(yè)市場保持健康
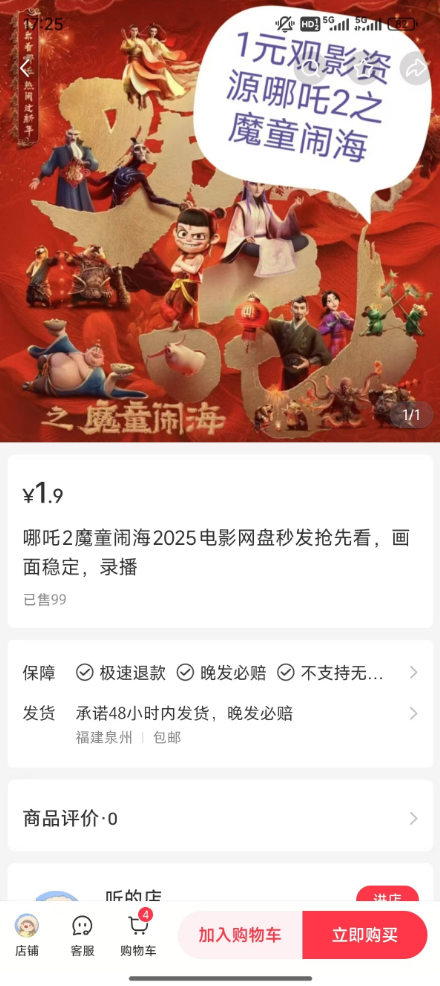
小紅書上1.9元可買到槍版《哪吒2》 盜版資源泛濫引發(fā)關注
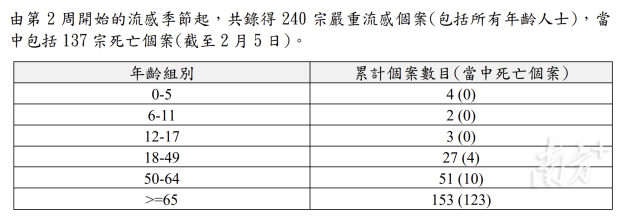
香港流感季已累計137人死亡 疫情引發(fā)廣泛關注

聯(lián)合國啟動行星安全協(xié)議 應對小行星威脅
突發(fā)訃告,!北京足球名宿谷大泉去世 曾率北京女足全運會奪金 享年69歲

美國國際開發(fā)署斥巨資請明星前往烏克蘭 引發(fā)爭議與討論

哪吒最后一個彩蛋什么意思 預示第三部精彩故事

臺名嘴:DeepSeek展現(xiàn)驚人推理能力 打破AI市場格局

熱烈歡迎!黃蜂官方曬照歡迎多爾頓-克內克特加盟球隊 湖人交易送別克內克特

A股利好,!證監(jiān)會制定《關于資本市場做好金融“五篇大文章”的實施意見》 深化投融資改革

俄軍傷亡百萬人之巨,?烏克蘭總統(tǒng)的數(shù)據(jù),為何總是前后矛盾,? 經濟與文化因素解析

特朗普簽行政令審查槍支管制政策 評估憲法第二修正案權利

女子去二姑家探親被整齊的被子驚到 強迫癥福音

《哪吒2》預測總票房達95億 8天登頂影史冠軍
客服回應網盤現(xiàn)陌生人隱私照

特朗普政府想讓美國人負責世衛(wèi)組織 推動激進改革計劃

俄媒:俄軍擊落烏空軍一架蘇-27戰(zhàn)機 烏方暫未回應

伊朗最高領袖哈梅內伊最新表態(tài) 拒與美國談判

宇宙深處驚現(xiàn)神秘雙星:超級木星VS褐矮星之謎 蓋亞探測器新發(fā)現(xiàn)
民警一把奪下手機保住老人千萬元存款 警民攜手智斗詐騙分子
特朗普上任半月多帶來了哪些沖擊 政策受阻與國際反彈

微信打電話和手機打電話區(qū)別真大 便捷與隱私的較量

于漢超:我只是完成了我的任務 穩(wěn)扎穩(wěn)打迎接新賽季

特朗普取消拜登的機密信息權限 撤銷安全許可

特朗普取消拜登獲得機密信息的訪問權限 拜登被剝奪安全許可

烏軍發(fā)起庫爾斯克軍事行動6個月 澤連斯基:我們的戰(zhàn)士取得了重大成果:歷史性突破持續(xù)施壓俄軍

騎手因外包裝破損被扣3000元 高額索賠引爭議

馬斯克將審查美國防部支出 政府效率部啟動審查

俄羅斯GDP創(chuàng)歷史新高 經濟增速達4.1%

貝弗利:馬刺在季后賽將很難對付 艱難的7場系列賽

小城奶茶咖啡爆單 有人等400多杯

特朗普剛極限施壓,,伊朗反手掏出一艘無人機航母 非核威懾戰(zhàn)略顯現(xiàn)
相關新聞
華東最大智算中心在南京投產 推動AI產業(yè)發(fā)展
2024-11-12 13:14:00華東最大智算中心在南京投產我國中部地區(qū)最大智算中心正式投產
“超級大腦”上線 我國中部地區(qū)最大智算中心正式投產日前,,中部地區(qū)規(guī)模最大的智算中心在河南鄭州正式投產。
2025-01-11 13:23:14“超級大腦”上線DeepSeek成美國大廠向AI砸錢強心劑 預見算力需求激增
DeepSeek目前在科技圈備受矚目,,它通過算法創(chuàng)新,,用更低的成本打造了接近OpenAI o1性能的開源推理模型R1和與GPT-4媲美的大模型V3
2025-02-08 08:35:01DeepSeek成美國大廠向AI砸錢強心劑轟動硅谷的他 將回廣東過年 震撼硅谷的“中國智造”,!
2025-01-27 15:37:04轟動硅谷的他將回廣東過年DeepSeek讓Meta深陷恐慌 中國AI逆襲硅谷
短短一個月內,,中國AI初創(chuàng)公司深度求索(DeepSeek)發(fā)布了兩款大模型——DeepSeek-V3和DeepSeek-R1
2025-01-26 10:34:01DeepSeek讓Meta深陷恐慌中國AI技術的快速發(fā)展“震動硅谷” 打破壟斷新格局
2025-01-29 03:13:43中國AI技術的快速發(fā)展震動硅谷