專家談如何看待我國(guó)AI現(xiàn)狀 技術(shù)與應(yīng)用迅猛發(fā)展(5)

數(shù)據(jù)質(zhì)量參差不齊,,數(shù)據(jù)偏差,、標(biāo)注錯(cuò)誤等問(wèn)題普遍存在,,嚴(yán)重影響模型訓(xùn)練效果,。在圖像識(shí)別訓(xùn)練集中,若標(biāo)注存在偏差,,會(huì)導(dǎo)致模型識(shí)別準(zhǔn)確率大幅下降,。對(duì)于像DeepSeek這樣依賴大量數(shù)據(jù)訓(xùn)練的模型,數(shù)據(jù)質(zhì)量的不穩(wěn)定會(huì)直接影響其性能表現(xiàn),。隨著AI對(duì)數(shù)據(jù)的依賴程度不斷加深,數(shù)據(jù)泄露風(fēng)險(xiǎn)日益增加,。如何在保障數(shù)據(jù)安全的前提下合理利用數(shù)據(jù),,成為AI發(fā)展面臨的重大挑戰(zhàn)。企業(yè)和機(jī)構(gòu)在收集,、存儲(chǔ)和使用數(shù)據(jù)過(guò)程中,,一旦出現(xiàn)安全漏洞,就可能導(dǎo)致大規(guī)模的數(shù)據(jù)泄露事件,,損害用戶權(quán)益,,影響AI技術(shù)的公信力。
AI臟數(shù)據(jù)是指那些包含錯(cuò)誤,、缺失,、重復(fù)或者不一致信息的數(shù)據(jù)。數(shù)據(jù)污染則是指在數(shù)據(jù)采集,、標(biāo)注或傳輸過(guò)程中,,有意或無(wú)意地引入了錯(cuò)誤數(shù)據(jù),,導(dǎo)致訓(xùn)練數(shù)據(jù)的真實(shí)性和可靠性受到破壞。在數(shù)據(jù)收集階段,,由于技術(shù)手段有限或人為疏忽,,可能會(huì)采集到不準(zhǔn)確的數(shù)據(jù)。在數(shù)據(jù)標(biāo)注環(huán)節(jié),,標(biāo)注人員的專業(yè)水平,、主觀判斷差異以及標(biāo)注流程的不規(guī)范,都可能導(dǎo)致標(biāo)注錯(cuò)誤,,從而污染數(shù)據(jù),。一旦這些臟數(shù)據(jù)和被污染的數(shù)據(jù)進(jìn)入模型訓(xùn)練過(guò)程,就會(huì)誤導(dǎo)模型學(xué)習(xí),,使模型產(chǎn)生錯(cuò)誤的決策和預(yù)測(cè),。例如,在自動(dòng)駕駛AI模型的訓(xùn)練中,,如果使用了被污染的路況數(shù)據(jù),,可能會(huì)導(dǎo)致模型在實(shí)際行駛中做出錯(cuò)誤的判斷,引發(fā)嚴(yán)重的安全事故,。
大規(guī)模AI模型訓(xùn)練需要巨大的計(jì)算資源和高昂的成本,。訓(xùn)練一個(gè)大型語(yǔ)言模型可能需要耗費(fèi)大量的電力和計(jì)算芯片資源,且訓(xùn)練時(shí)間長(zhǎng),,這對(duì)于許多科研機(jī)構(gòu)和企業(yè)來(lái)說(shuō)是巨大的負(fù)擔(dān),,限制了技術(shù)的快速發(fā)展和應(yīng)用。雖然DeepSeek在計(jì)算資源利用上有創(chuàng)新,,降低了訓(xùn)練成本和時(shí)間,,但整體AI行業(yè)對(duì)計(jì)算資源的高需求問(wèn)題依然存在。以訓(xùn)練GPT - 4為例,,其所需的計(jì)算資源成本高達(dá)數(shù)億美元,,且需要大量高端GPU芯片的持續(xù)運(yùn)行。在高端計(jì)算芯片受限的情況下,,中國(guó)AI企業(yè)包括DeepSeek仍面臨潛在的資源短缺風(fēng)險(xiǎn),。國(guó)際形勢(shì)變化可能導(dǎo)致芯片供應(yīng)受阻,使得企業(yè)在模型訓(xùn)練和迭代上遭遇困境,,限制了技術(shù)的進(jìn)一步發(fā)展和應(yīng)用拓展,。

楊妞花回老家跪祭父母 正義終得昭彰

北京未來(lái)三天以多云到晴為主 明后天最高氣溫將重回10℃以上 晝夜溫差大注意保暖

哪吒2火爆登陸新加坡 觀眾淚崩稱贊特效炸裂

巴格拉姆空軍基地被中國(guó)接管?阿富汗駁斥美方 情緒化言論遭批

明天驚蟄,,“驚蟄聞雷響,,谷米賤似泥” 農(nóng)事習(xí)俗與禁忌解析

美烏談崩 北約或成最大輸家 美國(guó)兩黨內(nèi)斗外溢

歐洲提出的俄烏和平方案能實(shí)現(xiàn)嗎 歐洲挺身而出爭(zhēng)奪主導(dǎo)權(quán)

特朗普:對(duì)澤連斯基不會(huì)再忍了 美烏關(guān)系緊張升級(jí)
哪吒2火爆登陸新加坡 觀眾淚崩稱贊特效炸裂

人大代表呼吁降低參保門檻,三項(xiàng)改革或落地 減輕靈活就業(yè)者負(fù)擔(dān)

美烏關(guān)系向何處去 復(fù)雜局勢(shì)下的博弈與分歧
楊妞花回老家跪祭父母 正義終得昭彰
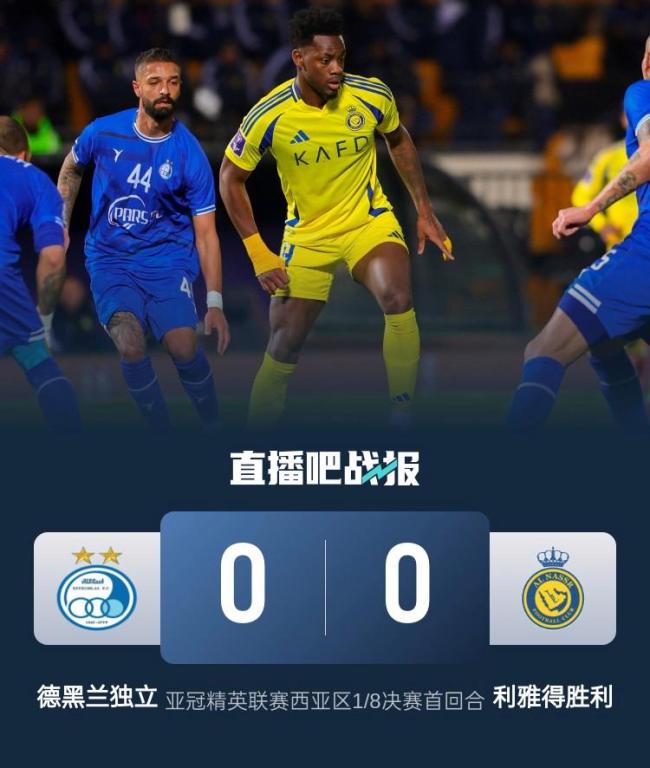
亞冠淘汰賽首回合:勝利0-0德黑蘭獨(dú)立 杜蘭中柱 屢失良機(jī) C羅缺陣 進(jìn)攻乏力憾平局

外交部駁斥魯比奧涉華言論 回?fù)衾鋺?zhàn)思維

英偉達(dá)大跌超8% 市場(chǎng)擔(dān)憂AI投入過(guò)剩

專家:美加征汽車關(guān)稅想“一石三鳥(niǎo)” 盟友反彈強(qiáng)烈

特朗普確認(rèn)對(duì)加墨征收關(guān)稅 美股重挫 市場(chǎng)恐慌情緒升高

壓力滿格了,?曼聯(lián)主帥稱自己“崩潰” 很難看到俱樂(lè)部積極一面 執(zhí)教困境凸顯

7500萬(wàn)先生引發(fā)曼聯(lián)阿森納哄搶 昔日意甲金靴成轉(zhuǎn)會(huì)香餑餑 多豪門競(jìng)購(gòu)難題浮現(xiàn)

澤連斯基10年間從意氣風(fēng)發(fā)到憔悴 命運(yùn)巨變

大V:烏克蘭將面臨三大嚴(yán)峻情況 盟友或成幕后推手

高?;貞?yīng)招聘勤雜工要求應(yīng)屆碩士 招聘已作廢引發(fā)討論
北京未來(lái)三天以多云到晴為主 明后天最高氣溫將重回10℃以上 晝夜溫差大注意保暖
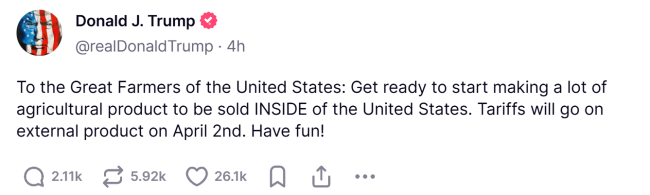
特朗普喊話美國(guó)農(nóng)民:要對(duì)外征稅了,玩得開(kāi)心,!關(guān)稅4月2日生效

美官員:特朗普未希望澤連斯基辭職 強(qiáng)調(diào)未介入烏政治

造謠80后死亡率5.2%多人被查處 謠言引發(fā)廣泛關(guān)注
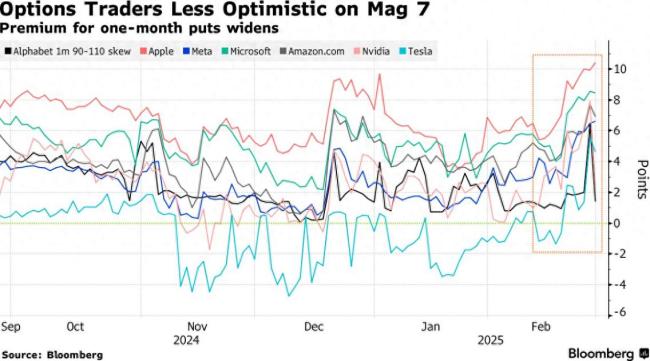
美股科技巨頭股價(jià)岌岌可危 期權(quán)成本上升引發(fā)擔(dān)憂

巴菲特罕見(jiàn)發(fā)聲 關(guān)稅或引發(fā)通脹

外媒稱特朗普上任后歐盟和中國(guó)走近 大國(guó)博弈新篇章

中國(guó)空軍赴哈瓦那看望古巴飛行員老爺爺 溫暖的雙向奔赴

小鵬汽車2月交付超3萬(wàn)輛 智能化升級(jí)體驗(yàn)

郭富城回東莞看祖居,!出動(dòng)電臺(tái)采訪,警察護(hù)送,,爺爺是金鋪大亨,!

是否會(huì)向?yàn)蹩颂m派遣維和部隊(duì)?中方回應(yīng) 支持和平解決危機(jī)

樸槿惠在私宅會(huì)見(jiàn)韓執(zhí)政黨領(lǐng)導(dǎo)層 表達(dá)對(duì)尹錫悅的憂慮和支持
甜馨發(fā)長(zhǎng)文自曝被同學(xué)孤立 回應(yīng)成長(zhǎng)爭(zhēng)議
相關(guān)新聞
專家談AI行業(yè)的2025 技術(shù)天花板與場(chǎng)景化應(yīng)用
2025-01-31 14:06:10專家談AI行業(yè)的2025莫言如何看待AI寫作 存在但勿懼怕
11月15日,,在廣西參加活動(dòng)的著名作家莫言在談到“AI寫作”時(shí)表示:“AI就是一個(gè)存在,不可忽略,,但不要被它嚇倒”
2024-11-17 14:48:00莫言如何看待AI寫作專家談AI是否會(huì)完全替代人類工作 智能角色的轉(zhuǎn)變
2025-02-19 03:56:43專家談AI是否會(huì)完全替代人類工作如何看待當(dāng)前人民幣匯率?專家解析 匯市再起波瀾
2025-01-10 16:09:15如何看待當(dāng)前人民幣匯率西方專家如何看待“殲36” 空中作戰(zhàn)系統(tǒng)核心
2025-01-09 18:15:43西方專家如何看待殲36專家就近期A股現(xiàn)狀進(jìn)行分析和展望
2024-09-29 13:27:12專家就近期A股現(xiàn)狀進(jìn)行分析和展望








