DeepSeek發(fā)新成果 稀疏注意力機(jī)制NSA顯著提升長上下文處理速度(2)

長文本建模是下一代語言模型的關(guān)鍵能力,,但傳統(tǒng)注意力機(jī)制的高復(fù)雜度限制了其在長序列上的應(yīng)用,。例如,在解碼64k長度的上下文時(shí),,注意力計(jì)算占據(jù)了總延遲的70%至80%,。因此,,稀疏注意力機(jī)制應(yīng)運(yùn)而生,通過選擇性計(jì)算關(guān)鍵的查詢鍵對來減少計(jì)算開銷,。然而,,許多稀疏注意力方法在實(shí)際推理中未能顯著降低延遲。
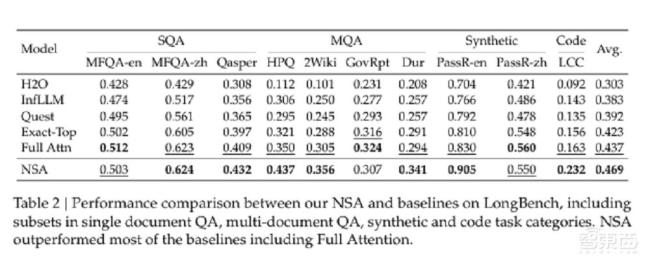
一些方法僅在自回歸解碼階段應(yīng)用稀疏性,,而預(yù)填充階段仍需進(jìn)行密集計(jì)算,;另一些方法僅關(guān)注預(yù)填充階段的稀疏性,導(dǎo)致在某些工作負(fù)載下無法實(shí)現(xiàn)全階段加速,。還有部分稀疏方法無法適應(yīng)現(xiàn)代高效的解碼架構(gòu),,導(dǎo)致KV緩存訪問量仍然較高,,無法充分發(fā)揮稀疏性優(yōu)勢。此外,,現(xiàn)有的稀疏注意力方法大多僅在推理階段應(yīng)用稀疏性,,缺乏對訓(xùn)練階段的支持。

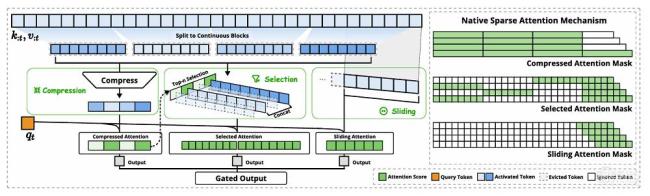
NSA旨在通過針對硬件特點(diǎn)的推理加速和適用于訓(xùn)練的算法設(shè)計(jì),,填補(bǔ)這一空白,。NSA的核心思想是通過動(dòng)態(tài)分層稀疏策略,結(jié)合粗粒度的token壓縮和細(xì)粒度的token選擇,,以保留全局上下文感知能力和局部精確性,。NSA將輸入序列通過三個(gè)并行的注意力分支處理:壓縮注意力、選擇性注意力和滑動(dòng)窗口注意力,。壓縮注意力通過將鍵和值聚合成塊級表示來捕捉粗粒度的語義信息,,減輕注意力計(jì)算負(fù)擔(dān)。選擇性注意力通過塊選擇機(jī)制保留重要的細(xì)粒度信息,,顯著降低了計(jì)算負(fù)擔(dān),?;瑒?dòng)窗口注意力專注于局部上下文信息,,防止模型過度依賴局部模式。

“重塑哪吒”非藕不可嗎 杜仲膠成新寵

四川一醫(yī)院員工上班玩游戲 涉事職工被嚴(yán)肅處理

俄方在沙特“三談一不談” 探索和平之路

澤連斯基是交易高手嗎 俄烏和談背后的博弈

烏軍坦克“漂移躲避”失敗被擊中
座談會(huì)上的企業(yè)家如何看待科技競爭 硬科技引領(lǐng)未來方向

男子跳水救三名兒童默默離開 全城尋人暖人心

男子為治三高醉駕到警局自首 荒唐行為引關(guān)注

泰總理講述訪華時(shí)和美女保鏢的趣事 結(jié)下深厚情誼

馬斯克暗示將審查美國最大金庫 黃金安全引質(zhì)疑

當(dāng)太乙真人遇上太乙假人 傳統(tǒng)文化的完美碰撞

黎官員稱部分黎邊境以軍已開始撤軍 撤軍期限臨近引發(fā)關(guān)注

俄美談判不帶歐盟烏克蘭意味著什么 主角被邊緣化

重慶江津回應(yīng)珞璜安家溪污染 調(diào)查正在進(jìn)行中

學(xué)者:烏克蘭想成為歐洲的以色列 澤連斯基的愿景
大學(xué)生刷視頻1個(gè)月欠費(fèi)上萬 高額流量費(fèi)引爭議

多所高校上線滿血DeepSeek AI助手助力教學(xué)科研

俄羅斯與北約參加同一演習(xí) 展現(xiàn)重大轉(zhuǎn)變

男子公布套圈套中瑪莎拉蒂全過程 2000塊小博大成功
四川一醫(yī)院員工上班玩游戲 涉事職工被嚴(yán)肅處理

DeepSeek帶來的中國資產(chǎn)重估能走多遠(yuǎn),?產(chǎn)業(yè)機(jī)遇全面釋放,!

學(xué)者:烏克蘭進(jìn)退兩難,不想被美國搶占礦產(chǎn)支援,,也離不開美國支持抗俄

俄美沙特開談,,重點(diǎn)是什么 烏克蘭缺席引關(guān)注
俄方在沙特“三談一不談” 探索和平之路

車主回應(yīng)女子跳樓砸到車生還 車輛成“救命稻草”

U20國足80秒內(nèi)連丟2球 13年來首次場場失守

美俄將談判結(jié)束烏克蘭沖突 初步會(huì)談顯積極信號

特朗普:在我任上俄什么都沒拿著

U20國足1-2惜敗澳大利亞 國青晉級展現(xiàn)新氣象

美暫停對外援助或致全球艾滋病死亡病例大增 資金缺口嚴(yán)重
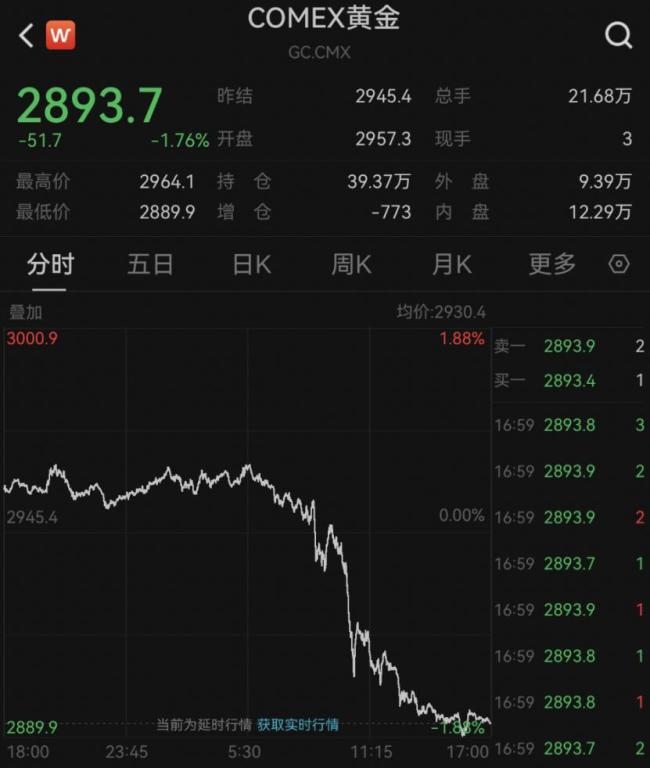
美聯(lián)儲(chǔ)突發(fā)!全球央行集體“避險(xiǎn)”,,金價(jià)新動(dòng)向 市場重新評估漲勢

四川小伙跳河輕生被釣魚佬救起 20年未下水英勇救人
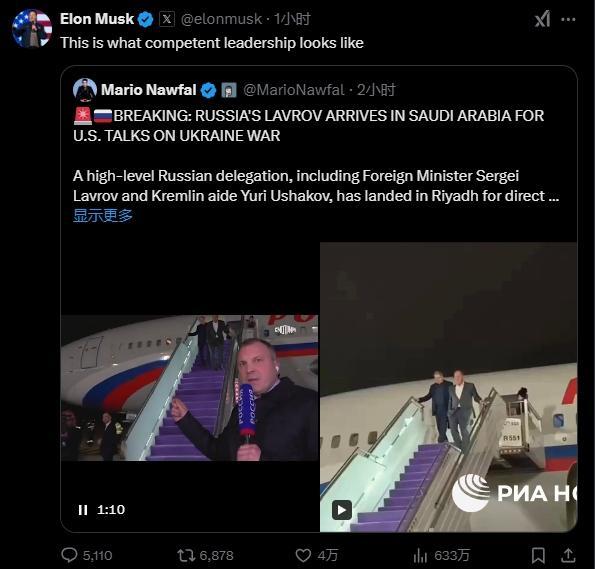
澤連斯基談美俄談判:不參加,,不承認(rèn) 烏克蘭拒絕未參與的協(xié)議

尹錫悅未出席公開辯論返回拘留所 全權(quán)委托律師團(tuán)
“重塑哪吒”非藕不可嗎 杜仲膠成新寵
相關(guān)新聞
《唐探1900》發(fā)新預(yù)告 歡喜冤家大顯神通
2025-01-22 11:03:57唐探1900發(fā)新預(yù)告DeepSeek在自動(dòng)駕駛中有何優(yōu)勢 車圈刮起“DeepSeek風(fēng)”
2025-02-18 06:34:40DeepSeek在自動(dòng)駕駛中有何優(yōu)勢實(shí)測DeepSeek做奧數(shù)題寫作文 DeepSeek火爆全球
2025-01-27 20:13:31實(shí)測DeepSeek做奧數(shù)題寫作文《射雕英雄傳:俠之大者》發(fā)新預(yù)告 鐵血丹心喚武俠情懷
1月25日,,武俠電影《射雕英雄傳:俠之大者》發(fā)布了“鐵血丹心”特別預(yù)告
2025-01-26 10:53:15射雕英雄傳以對貝魯特發(fā)新撤離令 以軍空襲接踵而至
2024-10-10 21:07:12以對貝魯特發(fā)新撤離令周杰倫宣布暑假要發(fā)新專輯 粉絲興奮期待
2025-02-09 07:41:37周杰倫宣布暑假要發(fā)新專輯








