小心AI在胡說八道 警惕虛假信息誤導(dǎo)(2)

法學(xué)碩士生小昭在寫論文時(shí)發(fā)現(xiàn),,AI生成的內(nèi)容有很多是錯(cuò)誤的。特別是在處理“深度偽造”的法律問題時(shí),,AI會(huì)生成虛假的法律條例和案例,。她還發(fā)現(xiàn),,AI喜歡引用過于具體的數(shù)據(jù),這些數(shù)據(jù)明顯是編造的。盡管如此,,小昭仍然依賴DeepSeek,、豆包、Kimi等AI工具來輔助寫作,,但她每次看到DeepSeek引用的內(nèi)容都要重新檢索確認(rèn)真實(shí)性,。
小昭的感受并不虛妄。在Github上的一個(gè)名為Vectara的大模型幻覺測(cè)試排行榜中,,2025年1月發(fā)布的DeepSeek R1,,幻覺率高達(dá)14.3%,遠(yuǎn)高于其他國際先進(jìn)大模型,。張俊林解釋,,DeepSeek生成的內(nèi)容比一般AI應(yīng)用更長,更容易出錯(cuò),。此外,,DeepSeek在生成答案時(shí)展現(xiàn)出很強(qiáng)的創(chuàng)造性,這與強(qiáng)調(diào)信息精確的要求相悖,。
清華大學(xué)團(tuán)隊(duì)在2025年2月發(fā)布《DeepSeek與AI幻覺》報(bào)告,,將AI幻覺分為兩類:事實(shí)性幻覺和邏輯性幻覺。香港科技大學(xué)團(tuán)隊(duì)的研究指出,,導(dǎo)致AI幻覺的原因包括數(shù)據(jù)源問題,、編碼器設(shè)計(jì)問題、解碼器錯(cuò)誤解碼等,。從AI大模型原理的角度看,,AI幻覺被業(yè)界認(rèn)為是AI擁有智能的體現(xiàn)。出門問問大模型團(tuán)隊(duì)前工程副總裁李維解釋,,幻覺的本質(zhì)是補(bǔ)白,,是腦補(bǔ)。
AI自己也承認(rèn)幻覺的存在,。在深度思索模式下,,DeepSeek列出了自己的反思,表示知識(shí)邊界限制和生成機(jī)制特性導(dǎo)致了這一結(jié)果,。盡管AI的幻覺在某些科研工作中有用,,如新分子的發(fā)現(xiàn),但解決或改善幻覺問題仍非常重要,。美國知名律師事務(wù)所Morgan & Morgan警告律師不要在法庭文件中使用AI生成的虛假信息,,否則可能面臨嚴(yán)重后果??萍脊疽苍趪L試通過檢索增強(qiáng)生成技術(shù)(RAG)等方式減少幻覺的產(chǎn)生,,但目前還沒有根除方法,。
OpenAI華人科學(xué)家翁荔建議,確保模型輸出是事實(shí)性的并可以通過外部世界知識(shí)進(jìn)行驗(yàn)證,。谷歌的Gemini模型提供了“雙重核查響應(yīng)”功能,,以幫助用戶辨別內(nèi)容的真實(shí)性。這些努力都在提醒人們不要全然相信AI,。

中國香港特區(qū)救援隊(duì)在緬甸地震重災(zāi)區(qū)曼德勒開展救援 無人機(jī)與搜救犬齊出動(dòng)
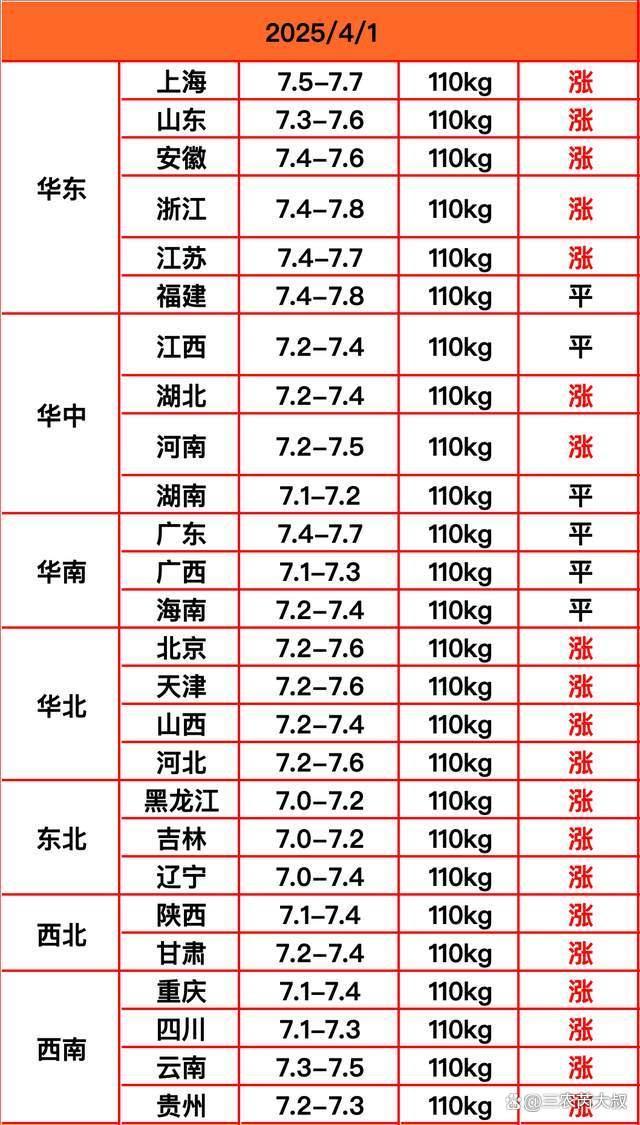
豬價(jià)大漲,!4月豬價(jià)要起飛嗎?新一輪上漲行情悄然而至

海警艦艇編隊(duì)環(huán)臺(tái)島執(zhí)法管控 依法管控實(shí)際行動(dòng)

美方不許中方阻止港口交易影響幾何 地緣政治博弈升級(jí)

呼叫81192 念念不忘,,必有回響,!

經(jīng)濟(jì)學(xué)家談未來房價(jià):再漲很困難 供需與老齡化影響顯著
海警艦艇編隊(duì)環(huán)臺(tái)島執(zhí)法管控 依法管控實(shí)際行動(dòng)
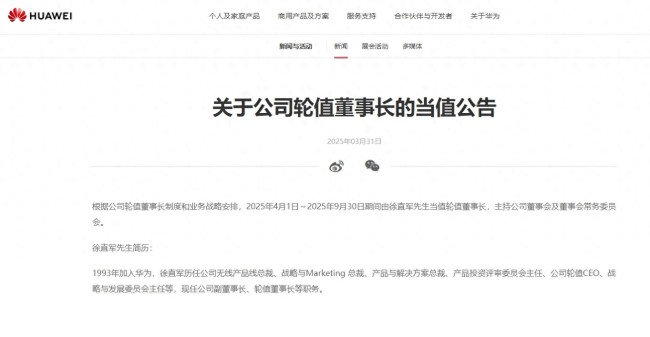
華為:徐直軍擔(dān)任輪值董事長,再次履新

“甲亢哥”為什么火了 真實(shí)中國引爆全球

臺(tái)媒稱7艘解放軍艦艇在臺(tái)海周邊活動(dòng) 持續(xù)戰(zhàn)備警巡

日本實(shí)施首個(gè)防止顧客騷擾條例 服務(wù)文化迎來轉(zhuǎn)折點(diǎn)

男子送貨途中水庫炸魚意外身亡 送貨人不幸溺亡

華為近十年研發(fā)費(fèi)用超1.24萬億 智能化引領(lǐng)未來趨勢(shì)
全球股市大跳水 黃金大漲再創(chuàng)新高 特朗普關(guān)稅令引發(fā)市場(chǎng)動(dòng)蕩

專家直播解讀解放軍臺(tái)島周邊演訓(xùn) 堅(jiān)定捍衛(wèi)國家主權(quán)
豬價(jià)大漲,!4月豬價(jià)要起飛嗎,?新一輪上漲行情悄然而至
想甩掉內(nèi)臟脂肪、減輕脂肪肝,,最重要的飲食和運(yùn)動(dòng)原則是什么,?

揭開游戲代練"代肝"低價(jià)內(nèi)卷真相 月入過萬只是少數(shù)

緬甸地震的危害究竟有多大 次生災(zāi)害更令人擔(dān)憂

現(xiàn)貨黃金升至3134.34美元續(xù)創(chuàng)新高 刷新歷史紀(jì)錄

重新定義39歲不著調(diào)的中年女性

美前副國務(wù)卿:從沒遇到過這樣的總統(tǒng) 特朗普的“交易主義”引發(fā)全球擔(dān)憂

俄戰(zhàn)機(jī)投3噸級(jí)炸彈轟炸烏軍 無掩護(hù)的士兵基本無法存活

7艘解放軍艦艇在臺(tái)海周邊活動(dòng) 持續(xù)戰(zhàn)備警巡

中國在南海東部海域發(fā)現(xiàn)億噸級(jí)油田 展現(xiàn)深層勘探潛力

有觀點(diǎn)稱中方正在對(duì)外資展開魅力攻勢(shì) 外交部回應(yīng)
中國香港特區(qū)救援隊(duì)在緬甸地震重災(zāi)區(qū)曼德勒開展救援 無人機(jī)與搜救犬齊出動(dòng)

緬甸領(lǐng)導(dǎo)人敏昂萊慰問中國救援醫(yī)療隊(duì):感謝第一時(shí)間來緬提供幫助 查看搜救情況

孔子為何認(rèn)為“國之大事在祀與戎”

外媒:特朗普稱預(yù)計(jì)普京將在俄烏停火協(xié)議中“履行他的職責(zé)” 展現(xiàn)信心與期待

現(xiàn)場(chǎng):印度警嫂當(dāng)街熱舞引發(fā)交通大擁堵

大V:特朗普“百日訪華”計(jì)劃破產(chǎn) 沙特成首訪選擇

臺(tái)軍事專家北京旅行歸來后感嘆萬千:大陸最美的風(fēng)景是人

臺(tái)防務(wù)部門:山東艦進(jìn)入臺(tái)灣所謂“應(yīng)變區(qū)” 啟動(dòng)應(yīng)變機(jī)制嚴(yán)密監(jiān)控

官方通報(bào)“夫妻稱開店遭刁難” 真相浮出水面口碑反轉(zhuǎn)
相關(guān)新聞
李彥宏稱AI不再一本正經(jīng)胡說八道 大模型消除幻覺
2024-11-12 15:42:32李彥宏稱AI不再一本正經(jīng)胡說八道楊立昆最新采訪:AI威脅論是胡說八道,,堆砌芯片和數(shù)據(jù)不能實(shí)現(xiàn)AGI AI教父駁斥恐慌論
2024-10-13 16:31:25楊立昆最新采訪:AI威脅論是胡說八道愛情算法很蠱 小心數(shù)據(jù)在裸奔 AI伴侶背后的隱患
2024-12-06 07:39:27愛情算法很蠱小心數(shù)據(jù)在裸奔分析:DeepSeek-R1為何會(huì)胡說八道 幻覺率高達(dá)14.3%
2025-03-01 09:18:29分析被記者炮轟對(duì)加沙“逃避責(zé)任胡說八道”,,美國務(wù)院發(fā)言人:下一個(gè)問題
2024-10-09 13:50:47美國務(wù)院發(fā)言人被記者炮轟四個(gè)身體信號(hào)小心腎臟病
2025-03-18 23:46:22四個(gè)身體信號(hào)小心腎臟病








