稚暉君搞了個(gè)“好東西”,,網(wǎng)上的視頻也能拿來(lái)訓(xùn)練機(jī)器人了 提高復(fù)雜任務(wù)成功率

稚暉君搞了個(gè)“好東西”,,網(wǎng)上的視頻也能拿來(lái)訓(xùn)練機(jī)器人了 提高復(fù)雜任務(wù)成功率,!上周五,稚暉君在微博預(yù)告了一波“好東西”。周一,,智元機(jī)器人就展示了新產(chǎn)品。這款機(jī)器人能夠端茶倒水、煮咖啡,,還能把面包放進(jìn)面包機(jī),涂抹果醬,,并將面包端到面前,。此外,它還可以充當(dāng)迎賓前臺(tái),。
不過,,這些功能在現(xiàn)今的人形機(jī)器人視頻中已不罕見。真正值得關(guān)注的是智元機(jī)器人發(fā)布的基座大模型GO-1(Genie Operator-1),。這個(gè)大模型解決了人形機(jī)器人長(zhǎng)期以來(lái)面臨的數(shù)據(jù)匱乏和泛化能力差的問題,。
目前,人形機(jī)器人表現(xiàn)不佳的一個(gè)重要原因就是缺乏高質(zhì)量數(shù)據(jù),,而獲取這些數(shù)據(jù)的成本非常高,。去年底,智元機(jī)器人開源了百萬(wàn)真機(jī)數(shù)據(jù)集AgiBot World,,涵蓋了超過100萬(wàn)條軌跡,、217個(gè)任務(wù)和106個(gè)場(chǎng)景。盡管如此,,這些數(shù)據(jù)仍然不足以解決機(jī)器人泛化能力差的問題,。
為此,智元機(jī)器人提出了新的ViLLA(Vision-Language-Latent-Action)架構(gòu),,這是GO-1大模型的核心,。與傳統(tǒng)的VLA架構(gòu)不同,ViLLA架構(gòu)不僅依賴于大量標(biāo)注過的真機(jī)數(shù)據(jù),,還能利用互聯(lián)網(wǎng)上的大量人類視頻數(shù)據(jù),。這意味著基于GO-1大模型的機(jī)器人可以通過觀看視頻來(lái)學(xué)習(xí)相應(yīng)動(dòng)作。
具體來(lái)說,,ViLLA架構(gòu)由VLM(多模態(tài)大模型)和MoE(混合專家)組成,。VLM處理輸入的視頻數(shù)據(jù),潛在動(dòng)作模型將其拆解成關(guān)鍵步驟,,如“抓取”,、“移動(dòng)”和“喝水”,。接著,隱式規(guī)劃器進(jìn)一步細(xì)化這些步驟,,生成更詳細(xì)的指令,。最后,動(dòng)作專家將這些指令轉(zhuǎn)換成機(jī)器人可以理解并執(zhí)行的動(dòng)作信號(hào),。
相比傳統(tǒng)VLA架構(gòu),,ViLLA架構(gòu)在執(zhí)行復(fù)雜任務(wù)時(shí)表現(xiàn)更出色,且任務(wù)泛化能力更強(qiáng),。此外,,ViLLA架構(gòu)生成的是通用動(dòng)作標(biāo)記,不依賴特定硬件,,更容易遷移到其他機(jī)器人平臺(tái),。
GO-1使機(jī)器人能夠從互聯(lián)網(wǎng)上的人類視頻數(shù)據(jù)中學(xué)習(xí),并具備拆解任務(wù)的能力,,提高了復(fù)雜任務(wù)的成功率和泛化能力,。如果GO-1的效果如官方描述,這將是整個(gè)人形機(jī)器人行業(yè)的一大進(jìn)步,。至于智元是否會(huì)繼續(xù)開源GO-1,,還有待觀察。聽說智元機(jī)器人明天還將公布一個(gè)驚喜,,讓我們拭目以待,。

中國(guó)救援隊(duì)救出緬甸女孩被不停感謝 星夜馳援展現(xiàn)中國(guó)擔(dān)當(dāng)

知名音樂人王偉去世,年僅39歲 古琴界痛失英才

國(guó)企5折收房,,開發(fā)商不愿“割肉” 探索存量房收儲(chǔ)新思路
美防長(zhǎng)為何在硫磺島稱贊日軍勇敢 引發(fā)爭(zhēng)議言論

烏士兵被炸傷后又遭一槍爆頭 戰(zhàn)爭(zhēng)殘酷無(wú)情

美防長(zhǎng)訪菲“挑事” 想拿菲當(dāng)槍使嗎 解放軍強(qiáng)硬回應(yīng)

直擊空軍戰(zhàn)機(jī)實(shí)彈地靶訓(xùn)練 精準(zhǔn)打擊錘煉實(shí)戰(zhàn)技能

美借"二級(jí)關(guān)稅"威脅多國(guó) 經(jīng)濟(jì)戰(zhàn)爭(zhēng)新概念引發(fā)爭(zhēng)議

緬甸地震中幸存的中國(guó)玉石商人 經(jīng)歷生死瞬間
知名音樂人王偉去世,,年僅39歲 古琴界痛失英才

44歲外賣員跳水救人犧牲 英雄事跡感動(dòng)全城

夫妻車禍?zhǔn)軅愤^釣友救人:大叔兩處骨折不停呼喊詢問“老婆怎么樣”

這是維護(hù)國(guó)家統(tǒng)一的正當(dāng)必要行動(dòng) 震懾“臺(tái)獨(dú)”分裂勢(shì)力

現(xiàn)場(chǎng):這火箭墜毀拍的好唯美 歐洲民營(yíng)火箭首飛失利

東部戰(zhàn)區(qū)發(fā)布視頻《降妖除魔》 展現(xiàn)聯(lián)合作戰(zhàn)實(shí)力
胡錫進(jìn):美國(guó)PUA日本,媒體操控真相

黃霄雲(yún)方回應(yīng)翻唱爭(zhēng)議 已獲合法授權(quán)

媒體人:特朗普連自己說的話都不認(rèn) 中東局勢(shì)再掀波瀾

匈外長(zhǎng):俄烏沖突持續(xù)不符合歐非利益 呼吁停止阻撓和談
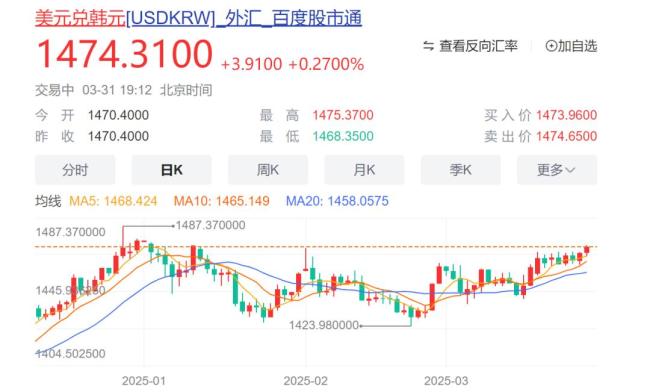
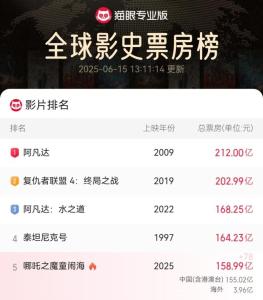
美國(guó)關(guān)稅大棒壓頂,,韓國(guó)遭遇“股匯雙殺”,,匯率跌到16年新低 多重因素致韓元貶值

學(xué)者:烏克蘭可能失去最后支持 美烏關(guān)系生變
國(guó)企5折收房,開發(fā)商不愿“割肉” 探索存量房收儲(chǔ)新思路
中國(guó)救援隊(duì)救出緬甸女孩被不停感謝 星夜馳援展現(xiàn)中國(guó)擔(dān)當(dāng)

透視30家上市券商:有高管團(tuán)隊(duì)去年降薪總額超6500萬(wàn),,行業(yè)分化明顯

罕見集結(jié),!美方證實(shí)多架B-2“幽靈”隱形轟炸機(jī) 部署迪戈加西亞基地
北京本周每日最高氣溫維持在20℃左右,大風(fēng)藍(lán)色預(yù)警中 多風(fēng)干燥請(qǐng)注意防范

顧客取消訂單外賣小哥破防,!

日本稱有特大地震風(fēng)險(xiǎn)或致30萬(wàn)死 經(jīng)濟(jì)損失或?qū)⒊?92萬(wàn)億日元

業(yè)內(nèi):特斯拉V13安全接管或達(dá)天級(jí) FSD重大更新揭曉

最新,!大摩:應(yīng)增持離岸中國(guó)股票

賽季報(bào)銷!鵜鶘官宣:錫安和麥科勒姆各自因傷提前結(jié)束本賽季 球隊(duì)無(wú)緣附加賽

伊朗就特朗普言論向聯(lián)合國(guó)發(fā)起投訴:輕率,、好戰(zhàn)

住宅新規(guī)來(lái)了:6大方面作出相應(yīng)要求,!

無(wú)激素男性避孕藥或即將問世 二期臨床試驗(yàn)進(jìn)行中

特朗普對(duì)俄烏和談心態(tài)完全改變 斡旋難見成效
相關(guān)新聞
稚暉君的GO-1大模型好在哪 開啟“類人”智能進(jìn)化
2025-03-11 15:38:23稚暉君的GO-1大模型好在哪稚暉君發(fā)布最新人形機(jī)器人 靈犀X2展現(xiàn)三智能交互
2025-03-11 10:49:39稚暉君發(fā)布最新人形機(jī)器人稚暉君介紹通用人形機(jī)器人原型機(jī) 靈犀X2亮相
2025-03-11 14:04:11稚暉君介紹通用人形機(jī)器人原型機(jī)稚暉君項(xiàng)目發(fā)布智元啟元大模型 開創(chuàng)ViLLA架構(gòu)
2025-03-10 12:06:01稚暉君項(xiàng)目發(fā)布智元啟元大模型稚暉君:距離王興興就差一個(gè)春晚了 科技新星的崛起之路
2025-03-11 22:08:32稚暉君稚暉君智元機(jī)器人公司注資增加至8045萬(wàn)余元 注冊(cè)資本大幅提升
2025-03-24 11:25:54稚暉君智元機(jī)器人公司注資增加至8045萬(wàn)余元