螞蟻集團(tuán)取得重大AI突破 降低訓(xùn)練成本20%(2)

實(shí)驗(yàn)結(jié)果最終表明,,一個(gè)規(guī)模為300B的MoE大語(yǔ)言模型可以在性能較低的設(shè)備上有效訓(xùn)練,,并在性能上達(dá)到與同規(guī)模的其他模型相當(dāng)?shù)乃?。與高性能設(shè)備相比,,在預(yù)訓(xùn)練階段使用低規(guī)格硬件系統(tǒng)可顯著節(jié)約成本,計(jì)算開支約降低20%,。
當(dāng)前最先進(jìn)的MoE模型在訓(xùn)練過程中嚴(yán)重依賴高性能AI加速器,,這類高端硬件持續(xù)供不應(yīng)求。相比之下,,性能較低的加速器更易獲得且單價(jià)更低,。這種差異凸顯出建立一種能夠在異構(gòu)計(jì)算單元和分布式集群之間無(wú)縫切換的技術(shù)體系的必要性,從而優(yōu)化訓(xùn)練與推理的整體成本,。
MoE模型的訓(xùn)練通常依賴于如英偉達(dá)所售GPU這類高性能芯片,這使得訓(xùn)練成本對(duì)許多中小企業(yè)而言過于高昂,,限制了更廣泛的應(yīng)用,。螞蟻集團(tuán)一直在致力于提高大語(yǔ)言模型的訓(xùn)練效率,并突破這一限制,。從其論文標(biāo)題即可看出,,該公司將目標(biāo)定為“在無(wú)需高端GPU的情況下擴(kuò)展模型規(guī)?!薄?/p>
這一方向與英偉達(dá)的戰(zhàn)略背道而馳,。英偉達(dá)首席執(zhí)行官黃仁勛曾表示,,即便更高效的模型出現(xiàn),對(duì)計(jì)算力的需求仍會(huì)持續(xù)增長(zhǎng),,企業(yè)要實(shí)現(xiàn)更多營(yíng)收將依賴更強(qiáng)大的芯片,,而非通過更便宜的芯片來(lái)削減成本。他堅(jiān)持打造具備更多處理核心,、更高晶體管數(shù)量和更大內(nèi)存容量的大型GPU的戰(zhàn)略,。
螞蟻集團(tuán)的研究論文凸顯出中國(guó)AI領(lǐng)域技術(shù)創(chuàng)新和發(fā)展速度的加快。如果其研究成果屬實(shí),,這將表明中國(guó)在人工智能領(lǐng)域正逐步走向自主可控,,特別是在尋求成本更低、計(jì)算效率更高的模型架構(gòu)來(lái)應(yīng)對(duì)英偉達(dá)芯片出口限制的背景下,。
針對(duì)此事,,螞蟻集團(tuán)回應(yīng)稱,他們針對(duì)不同芯片持續(xù)調(diào)優(yōu),,以降低AI應(yīng)用成本,,目前取得了一定的進(jìn)展,也會(huì)逐步通過開源分享,。

無(wú)憂渡 夜華的頭套還留著呢 段半夏從懵懂少女成長(zhǎng)為守護(hù)者的弧光

老板扛20斤硬幣付工資法官讓其清點(diǎn) 惡意刁難員工

《我的后半生》劇情有多狗血 家庭崩塌與人性覺醒
大V:烏軍在庫(kù)爾斯克損失極為慘重 俄軍反擊得勝

嚴(yán)格依法實(shí)施各項(xiàng)對(duì)美反制措施 維護(hù)國(guó)家主權(quán)安全發(fā)展利益

俄為何空襲烏克蘭蘇梅市 教堂鐘聲下的悲劇

老板為報(bào)復(fù)員工扛20斤硬幣支付工資 惡意履行觸法網(wǎng)

緬甸災(zāi)區(qū)進(jìn)入防疫消殺 中方接力馳援 救援“接力棒”持續(xù)傳遞

美防長(zhǎng)威脅:如果談判失敗,,美軍已準(zhǔn)備好確保伊朗永遠(yuǎn)不會(huì)擁有核武器 展示軍事打擊能力

剖析甲亢哥中國(guó)行直播連續(xù)劇 全民狂歡的流量盛宴
《我的后半生》劇情有多狗血 家庭崩塌與人性覺醒

專家稱關(guān)稅戰(zhàn)讓美國(guó)的盟友都不再相信它

航模愛好者自制能飛上天的“殲-20” 紙箱變身特技戰(zhàn)機(jī)

打扮成埃及女王逛大英博物館 博主吐槽引熱議

美對(duì)等關(guān)稅這劑藥反噬自身 單邊主義終損己利
無(wú)憂渡 夜華的頭套還留著呢 段半夏從懵懂少女成長(zhǎng)為守護(hù)者的弧光
老板扛20斤硬幣付工資法官讓其清點(diǎn) 惡意刁難員工

夫妻領(lǐng)走1003萬(wàn)大獎(jiǎng):不會(huì)告訴孩子,小愛好成真

高關(guān)稅背景下中企如何“活下去” 三大策略穩(wěn)住腳跟

八個(gè)有望抗住關(guān)稅沖擊的出海賽道 解鎖全球生活方式共建者新角色

楊紫《家業(yè)》逛街路透,,和美女們說(shuō)說(shuō)笑笑…

美軍將重返巴拿馬前美軍基地,?巴反對(duì)派指責(zé)美方發(fā)動(dòng)“偽裝入侵” 引發(fā)民眾反感與抗議

駐日大使館提醒注意防范地震 提高防災(zāi)意識(shí)
如何跟大國(guó)相處 美國(guó)還得補(bǔ)課

臺(tái)灣加權(quán)指數(shù)漲幅擴(kuò)大至2% 盤初表現(xiàn)強(qiáng)勁

美國(guó)若想生產(chǎn)婚紗得先培養(yǎng)縫紉工 關(guān)稅政策沖擊婚慶業(yè)

關(guān)稅博弈下A股涌現(xiàn)增持回購(gòu)潮 積極信號(hào)頻現(xiàn)
12級(jí)大風(fēng)將蒙古獒幼崽刮到牧民家,網(wǎng)友:我想要一只牛

余承東和工程師拼手速還贏了

“對(duì)等關(guān)稅”重創(chuàng)美國(guó)小企業(yè) 反噬自身經(jīng)濟(jì)

全紅嬋說(shuō)要適應(yīng)體重變化 身體成長(zhǎng)影響表現(xiàn)
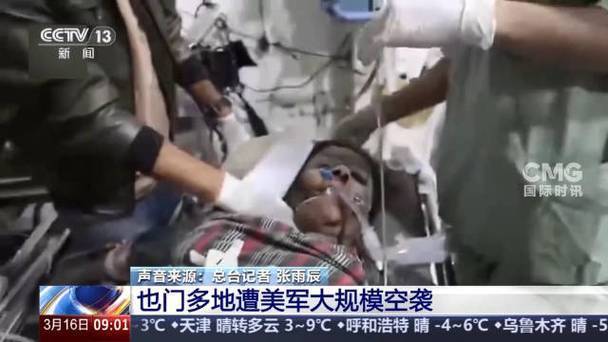
美軍再次空襲也門致多人死傷 建筑物遭襲被大火吞噬 硝煙中的平民悲劇
哪吒汽車 斷網(wǎng)事件引發(fā)信任危機(jī)

日本發(fā)生食物中毒事件 已有1人死亡 諾如病毒成疑兇

美國(guó)突然宣布: 部分商品免除所謂“對(duì)等關(guān)稅” 電子產(chǎn)品獲豁免
相關(guān)新聞
曝螞蟻集團(tuán)基于中國(guó)芯片實(shí)現(xiàn)AI突破 成本降低20%
2025-03-24 20:37:05曝螞蟻集團(tuán)基于中國(guó)芯片實(shí)現(xiàn)AI突破馬云現(xiàn)身螞蟻集團(tuán)20周年活動(dòng)現(xiàn)場(chǎng) 展望未來(lái)AI時(shí)代
2024-12-09 08:57:00馬云現(xiàn)身螞蟻集團(tuán)20周年活動(dòng)現(xiàn)場(chǎng)曝螞蟻集團(tuán)用國(guó)產(chǎn)芯片訓(xùn)練AI 性能媲美英偉達(dá)
2025-03-25 09:15:18曝螞蟻集團(tuán)用國(guó)產(chǎn)芯片訓(xùn)練AI螞蟻集團(tuán)即將借殼上市,?螞蟻回應(yīng) 無(wú)上市計(jì)劃
2024-12-19 10:56:18螞蟻集團(tuán)即將借殼上市螞蟻重大宣布:總裁韓歆毅明年將接任集團(tuán)CEO一職
中國(guó)基金報(bào)記者曹雯璟2024年12月8日是支付寶和螞蟻集團(tuán)的二十歲生日,。
2024-12-09 07:49:33螞蟻重大宣布!又一次見證歷史螞蟻集團(tuán)即將借殼上市?螞蟻回應(yīng) 無(wú)上市計(jì)劃
2024-12-19 11:40:12螞蟻集團(tuán)即將借殼上市








