LIama 4疑似作弊,,都怪Meta把牛皮吹破了 性能測試遭質(zhì)疑

4月5日,,美國科技巨頭Meta宣布推出新一代開源大模型Llama 4。該模型有兩個混合專家架構(gòu)的版本,,分別為Scout和Maverick,,而更強大的Llama 4 Behemoth仍在訓(xùn)練中,。據(jù)稱,,Llama 4在多個基準(zhǔn)測試中表現(xiàn)出色,,尤其是Behemoth,,在多項測試中超越了GPT-4.5,、Claude Sonnet 3.7和Gemini 2.0 Pro等頂尖封閉模型。

然而,,模型發(fā)布后不久,開發(fā)者實測發(fā)現(xiàn)其實際效果并不如宣傳中的那樣出色,,甚至存在諸多問題,。有開發(fā)者質(zhì)疑Meta在評測基準(zhǔn)上進行了“量身定制”訓(xùn)練以提升排名。知名科技媒體TechCrunch也指出,,Meta新AI模型的性能測試具有一定的誤導(dǎo)性,。
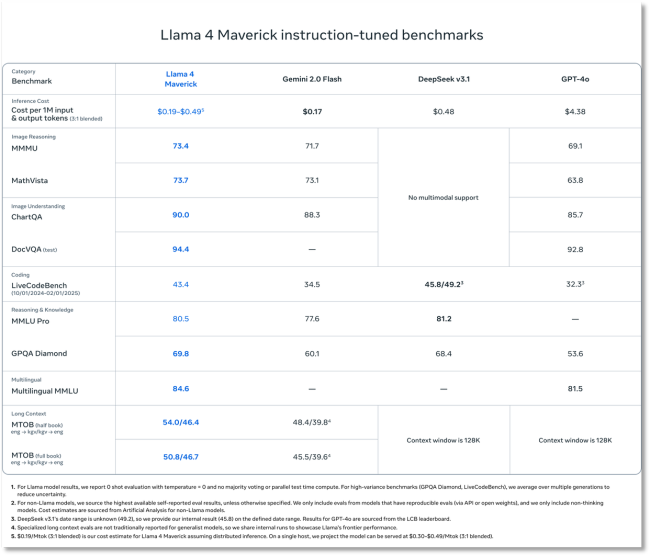
Meta對此回應(yīng)稱,,相關(guān)說法毫無事實依據(jù),。Llama 4 Scout擁有170億活躍參數(shù)和16個專家模塊,提供長達1000萬tokens上下文窗口,。Llama 4 Maverick同樣擁有170億活躍參數(shù),,但專家模塊數(shù)量提升至128個,。在多項主流基準(zhǔn)測試中,Maverick表現(xiàn)優(yōu)異,,尤其在推理和編碼方面可以與DeepSeek V3媲美,。Llama 4 Behemoth則擁有2880億活躍參數(shù)和16個專家模塊,在多項基準(zhǔn)測試中超越了行業(yè)頂尖模型,。
盡管官方聲稱Llama 4在編程、數(shù)學(xué),、創(chuàng)意寫作等任務(wù)中表現(xiàn)出色,,但開發(fā)者實測結(jié)果卻顯示其在這些領(lǐng)域的表現(xiàn)欠佳。風(fēng)險投資人迪迪·達斯直言Llama 4是一個糟糕的編程模型,,并指出在KCORES基準(zhǔn)測試中,,Llama 4落后于GPT-4o、Grok 3,、DeepSeek-V3等模型,。此外,Llama 4在aider多語言編碼基準(zhǔn)測試中的得分僅為16%,。
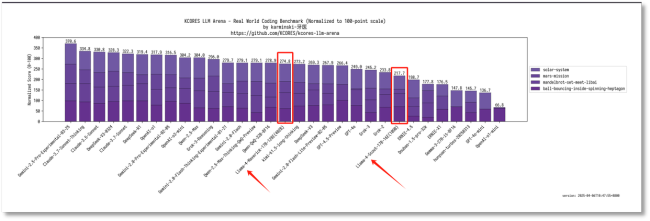
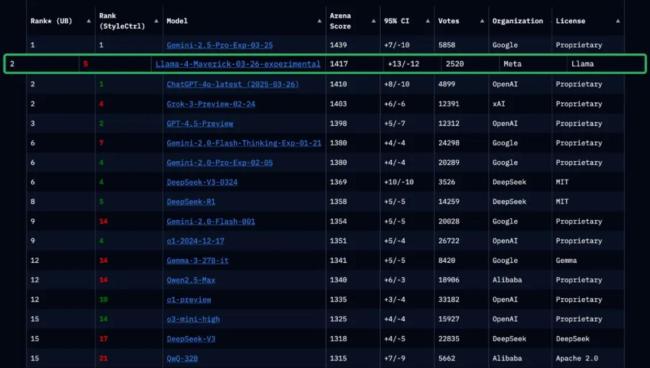
大模型競技場官方也指出,Meta在排行榜上使用的并非HuggingFace上的Llama 4版本,,而是針對人類偏好進行優(yōu)化的定制模型,。這使得開發(fā)者難以準(zhǔn)確預(yù)估模型在實際應(yīng)用場景中的表現(xiàn)。

與此同時,,一位自稱參與Llama 4訓(xùn)練的內(nèi)部員工爆料稱,公司在訓(xùn)練過程中存在作弊行為,。不過,,多位Meta員工對此進行了辟謠。Meta生成式AI副總裁艾哈邁德·阿爾·達赫勒公開表示,,相關(guān)說法毫無事實依據(jù),,并解釋稱部分用戶遇到的質(zhì)量不穩(wěn)定問題將在后續(xù)得到解決。Meta首席AI科學(xué)家Yann LeCun也為此發(fā)聲支持,。

A股走出“四連陽” 市場信心顯著提振

青島下冰雹了 市區(qū)多地出現(xiàn)“綠豆大小”冰雹

WTT太原挑戰(zhàn)賽混雙決賽中韓對陣 首金爭奪戰(zhàn)打響

中美關(guān)稅升級,,教育部發(fā)布留學(xué)預(yù)警…中產(chǎn)家庭留學(xué),,容錯空間越來越小 留學(xué)路障重重

云南鐵腕整治旅游市場 堅定守護旅游“金字招牌”

牛彈琴:中國這句話甩了美國80條街 美國人慌了神

陳芋汐一跳甩開對手 逆天改命奪金
WTT太原挑戰(zhàn)賽混雙決賽中韓對陣 首金爭奪戰(zhàn)打響
中央氣象臺預(yù)警4連 多地面臨極端天氣考驗

杜鋒:希望接下來越打越好 廣東晉級季后賽8強

有些商品根本就不會進入美國市場了 貿(mào)易摩擦影響顯著

國家能源集團領(lǐng)導(dǎo)班子調(diào)整 馮來法任新職

觀察|“關(guān)稅戰(zhàn)”將重創(chuàng)美國六代戰(zhàn)機夢?稀土出口管制影響顯現(xiàn)
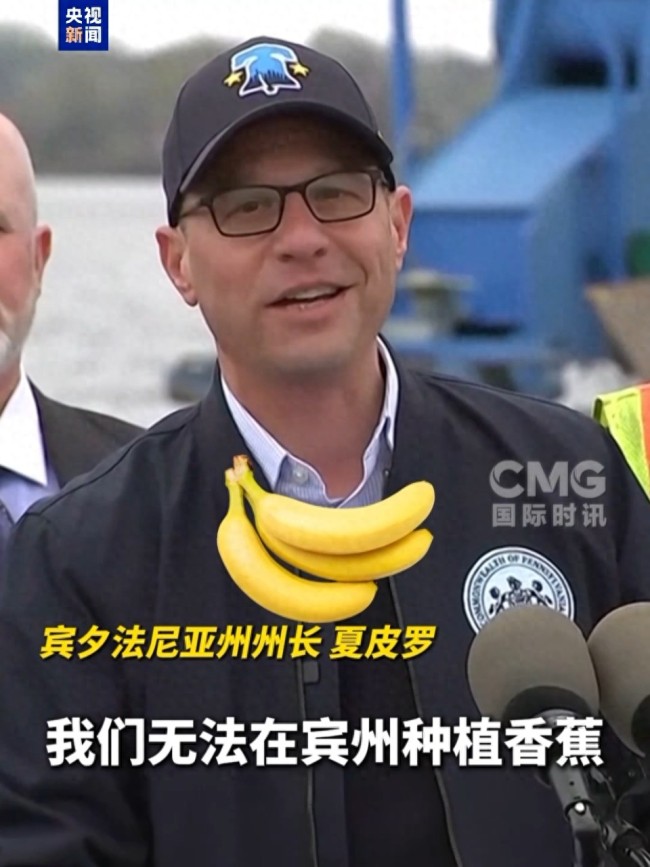
美州長:美國百年最高關(guān)稅引發(fā)混亂 政策搖擺導(dǎo)致困惑

外媒稱中國會在美國壓制下強勢反彈 政策成定海神針

專家稱特朗普沒想到中國奉陪到底 貿(mào)易戰(zhàn)里中國不倒

全國愛鼻日 科學(xué)護鼻過春敏
青島下冰雹了 市區(qū)多地出現(xiàn)“綠豆大小”冰雹

特朗普為何不主動接觸中國,?白宮回應(yīng) 等待中方先“求和”

專家談美有望歸還俄六處在美建筑 外交房產(chǎn)歸還見曙光

美專家稱最好不要與中國脫鉤 美國依賴中國產(chǎn)業(yè)鏈

在美中國留學(xué)生何去何從 多重因素影響抉擇

專家批美媒酸諷中國六代機 西方輿論急眼反應(yīng)

美國高官讓各國直接打錢 強盜邏輯暴露霸權(quán)野心

咸雪男主 張若昀朱一龍二選一 實力與人氣的碰撞

英首相回應(yīng)特朗普“親我的屁股”言論 尷尬沉默引發(fā)熱議

19歲小將史松宸談替補出場 感謝教練鼓勵與機會

河北三河已整改牌匾1820塊 城市管理爭議浮現(xiàn)

唐宮奇案白鹿殺青引爆期待 白鹿從御姐到將軍
A股走出“四連陽” 市場信心顯著提振

美國到底有多依賴中國商品 供應(yīng)鏈的“隱蔽依賴”

印尼數(shù)百人排長隊搶購金條 金價大跌引熱潮

第七次中日韓信息通信部長會議在中國蘇州舉行 共商數(shù)字未來合作

《還珠格格》“柳紅”否認(rèn)退圈 一直活躍在演藝圈

韓國選舉反轉(zhuǎn),,第二個尹錫悅參選,?新總統(tǒng)4選1,美國作最終決策 候選人角逐激烈
相關(guān)新聞
19歲女棋手比賽用AI作弊被禁賽8年 手機藏匿作弊遭嚴(yán)懲
2025-02-27 10:30:1819歲女棋手比賽用AI作弊被禁賽8年打擊加油機作弊 揭秘黑色利益鏈
2025-01-07 11:27:11打擊加油機作弊學(xué)生作弊被抓后跳樓身亡?校方回應(yīng)
2025-01-09 02:49:38學(xué)生作弊被抓后跳樓身亡多地消費者遭遇加油站作弊 高科技欺詐頻發(fā)
2025-01-06 11:35:40多地消費者遭遇加油站作弊保羅一臉無奈登全美熱搜:被嘲作弊失敗無下限 勇媒調(diào)侃這人真不行 技巧賽作弊風(fēng)波
2025-02-16 14:14:58保羅一臉無奈登全美熱搜19歲棋手用AI比賽被撤銷段位 作弊遭嚴(yán)懲
2月26日,,中國圍棋協(xié)會發(fā)布通報,,確認(rèn)職業(yè)棋手秦思玥在比賽中藏匿手機并作弊,。協(xié)會決定撤銷其職業(yè)段位,取消比賽成績,,并對其實施8年禁賽的處罰
2025-02-28 11:45:5919歲棋手用AI比賽被撤銷段位