DeepSeek和李飛飛之后,英偉達(dá)也看上阿里千問? 千問潛力引關(guān)注(2)

此前,斯坦福大學(xué)人工智能研究院院長(zhǎng)李飛飛團(tuán)隊(duì)也曾基于阿里通義千問Qwen2.5-32B-Instruct,,訓(xùn)練出與OpenAI o1,、DeepSeek R1等尖端推理模型數(shù)學(xué)及編碼能力相當(dāng)?shù)膕1-32B模型,。今年4月,李飛飛團(tuán)隊(duì)的研究報(bào)告顯示:中美兩國(guó)模型性能差距由2023年的17.5%大幅縮小至0.3%,,近乎持平,。阿里的六大模型入選報(bào)告,貢獻(xiàn)度僅次于OpenAI和Google,,排名全球第三,、中國(guó)第一。
更早之前,DeepSeek官方透露曾將DeepSeek-R1的推理能力蒸餾成六個(gè)模型開源給社區(qū),,其中有四個(gè)來(lái)自千問,,且在多項(xiàng)能力上實(shí)現(xiàn)了對(duì)標(biāo)OpenAI o1-mini的效果,。不少學(xué)者指出,,千問是所有開源模型中“隱藏驚喜”最大的?;F盧大學(xué)陳文虎教授直言,,用同樣的方法訓(xùn)練和微調(diào)別的模型都不管用,只有千問才有效果,,“千問系列模型一定有一些魔力,!”
事實(shí)上,在開源大模型領(lǐng)域,,被千問“迷之魅力”吸引來(lái)的不僅有頂級(jí)公司和大佬,,還有日常頻繁使用大模型的普通開發(fā)者們。據(jù)公開數(shù)據(jù)顯示,,截至當(dāng)前,,千問全球下載量超3億;在HuggingFace社區(qū)2024年全球模型下載量中占比超過(guò)30%,,穩(wěn)居全球第一,。千問衍生模型數(shù)量已突破10萬(wàn),超越美國(guó)Llama模型,,成為全球第一AI開源模型,。在2025年2月的Huggingface全球開源大模型榜單中,排名前十的開源模型全部基于千問Qwen二次開發(fā),。
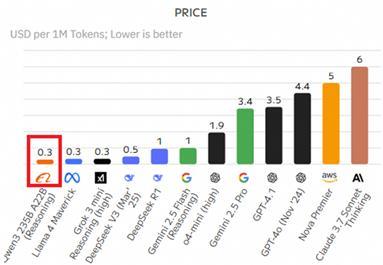
一個(gè)來(lái)自中國(guó)的大模型之所以在全球AI社區(qū)引發(fā)狂潮,,主要得益于以下三方面的作用,。首先,千問性能強(qiáng)勁且成本更低,。每次新發(fā)布幾乎都刷新了開源模型的上限,,例如最近的千問3在AIME25測(cè)評(píng)中斬獲81.5分,刷新開源紀(jì)錄,;在LiveCodeBench評(píng)測(cè)中突破70分大關(guān),,表現(xiàn)甚至超過(guò)Grok3。此外,,千問3的部署成本僅為性能相近模型的三分之一,,推理成本也不到DeepSeek-R1的三成。

救援隊(duì)稱8歲失蹤男童仍有生還可能 野外生存條件提供希望

原來(lái)甲骨文里也隱藏了母親的愛

情緒勞動(dòng)比工作更讓人疲憊 職場(chǎng)微笑背后的隱痛

巴基斯坦舉國(guó)感謝中國(guó) 真心朋友伸援手,!

中美聯(lián)合聲明后 特朗普轉(zhuǎn)移炮火 對(duì)歐盟重拳出擊

臺(tái)軍試射“海馬斯”兩度卡殼 信號(hào)異常引質(zhì)疑
救援隊(duì)稱8歲失蹤男童仍有生還可能 野外生存條件提供希望

印巴沖突為何快速停戰(zhàn) 經(jīng)濟(jì)賬成關(guān)鍵

百萬(wàn)網(wǎng)紅自導(dǎo)自演自殺一度漲粉2萬(wàn),,警方已立案!

兩臺(tái)灣人擅拍駐韓美軍基地被捕 違規(guī)拍攝引發(fā)關(guān)注

女子請(qǐng)沒找到工作的大叔吃飯 并換了100元現(xiàn)金給他修車

杜特爾特獄中當(dāng)選市長(zhǎng)有何影響 家族政治再?gòu)?qiáng)化

記者:烏掌握俄烏談判決定權(quán) 先?;疬€是先談判,?

印度嘉賓叫囂比起巴更愿和中國(guó)戰(zhàn)斗 自信還是自欺?

菲律賓政壇會(huì)否變天 家族內(nèi)斗引爆中期選舉

特朗普:對(duì)中國(guó)的關(guān)稅不會(huì)重回145%的水平 無(wú)意傷害中國(guó)

中美會(huì)談后人民幣匯率走勢(shì)如何 信心提振創(chuàng)半年新高

杜特爾特陣營(yíng)會(huì)否贏下5個(gè)參議員席位 權(quán)力游戲未完待續(xù)

澤連斯基只接受與普京談 拒見其他人 愿在土耳其直接會(huì)談
巴民眾蹲守拍攝殲-10C戰(zhàn)機(jī)編隊(duì) 背后故事令人動(dòng)容
原來(lái)甲骨文里也隱藏了母親的愛

杜特爾特獄中當(dāng)選市長(zhǎng)意味著什么 家族政治延續(xù)

中美協(xié)議是美國(guó)為爭(zhēng)取時(shí)間的妥協(xié)嗎 取得了實(shí)質(zhì)性進(jìn)展
情緒勞動(dòng)比工作更讓人疲憊 職場(chǎng)微笑背后的隱痛

菲總統(tǒng)姐姐為何成為政壇黑馬 家族政治的新篇章

哥倫比亞確認(rèn)加入“一帶一路”倡議 成為技術(shù)橋梁

特朗普:歐盟比中國(guó)更壞 轉(zhuǎn)向攻擊歐盟

外交部:芬太尼是美國(guó)的問題 美方應(yīng)停止抹黑推責(zé)

孫穎莎捏邱貽可后腦勺,,網(wǎng)友:又是羨慕co爹的一天,!

緬甸強(qiáng)震畫面曝光 地面像撕紙般滑動(dòng)!

警方回應(yīng)救護(hù)車無(wú)任務(wù)鳴笛開道 違規(guī)使用警報(bào)器受罰

首批二代身份證陸續(xù)期滿,?上海公安推出“夜間辦證”專場(chǎng)

哥總統(tǒng):將加入“一帶一路”倡議 加強(qiáng)技術(shù)橋梁作用

以色列要求國(guó)際刑事法院撤銷逮捕令 以方提起上訴

外賣員出門上班時(shí)去世 前1天跑70單 家屬質(zhì)疑工作量大引發(fā)關(guān)注
相關(guān)新聞
李飛飛團(tuán)隊(duì)50美元復(fù)刻DeepSeek真相 基于Qwen微調(diào)而成
2025-02-07 07:46:12李飛飛團(tuán)隊(duì)50美元復(fù)刻DeepSeek真相阿里云副總裁李飛飛談DeepSeek開源周 AI下半場(chǎng)的系統(tǒng)之戰(zhàn)
2025-02-27 02:44:50阿里云副總裁李飛飛談DeepSeek開源周李飛飛團(tuán)隊(duì)造“保姆”機(jī)器人 低成本實(shí)現(xiàn)家務(wù)全能助手
2025-03-14 13:16:17李飛飛團(tuán)隊(duì)造保姆機(jī)器人李飛飛呼吁構(gòu)建以人為中心的AI生態(tài) 從觀察者到行動(dòng)者
2025-02-25 18:11:17李飛飛呼吁構(gòu)建以人為中心的AI生態(tài)阿里云回應(yīng)李飛飛團(tuán)隊(duì)訓(xùn)練AI 低成本高成效引關(guān)注
2025-02-07 08:07:52阿里云回應(yīng)李飛飛團(tuán)隊(duì)訓(xùn)練AI人均DeepSeek之后AI應(yīng)用還能怎么做 探索新方向與挑戰(zhàn)
2025-02-18 09:48:48人均DeepSeek之后AI應(yīng)用還能怎么做