R2來之前 DeepSeek又放了個(gè)煙霧彈 V3論文揭示降本增效秘籍

5月前后,DeepSeek動(dòng)作頻繁,,盡管沒有推出大家期待的R2,,但一系列前期活動(dòng)已經(jīng)為R2做了充分鋪墊。5月14日,,一篇關(guān)于DeepSeek V3的論文揭示了梁文峰如何實(shí)現(xiàn)“極致降本”,。這篇論文讓業(yè)界得以了解這家以技術(shù)立身的公司其技術(shù)實(shí)力達(dá)到了何種水平。
與之前發(fā)布的V3技術(shù)報(bào)告不同,這篇論文詳細(xì)闡述了DeepSeek在硬件資源有限的情況下,,通過精妙的“軟硬一體”協(xié)同設(shè)計(jì),,將成本效益優(yōu)化到極致。在AI大模型這條燒錢的賽道上,,算力至關(guān)重要,,但也可能是壓垮駱駝的最后一根稻草。DeepSeek V3論文的核心在于解決一個(gè)行業(yè)痛點(diǎn):如何讓大模型不再是少數(shù)巨頭的專屬游戲,?
論文中,,DeepSeek分享了其“降本增效”的幾大秘籍,展示了對(duì)現(xiàn)有硬件潛能的極致利用,,并預(yù)示著未來DeepSeek系列模型在性能與效率上的野心,。首先,他們通過給模型的“記憶系統(tǒng)”瘦身來降低顯存占用,。具體來說,,使用“多頭隱注意力機(jī)制”(MLA)將冗長的信息濃縮成精華,從而大幅減少顯存需求,。這意味著即使處理越來越長的上下文,,模型也能更加從容不迫,這對(duì)于解鎖更多復(fù)雜應(yīng)用場(chǎng)景至關(guān)重要,。
其次,,DeepSeek V3沿用并優(yōu)化了“混合專家模型”(MoE)架構(gòu)。這一架構(gòu)類似于將一個(gè)龐大的項(xiàng)目分解給一群各有所長的專家,,遇到具體問題時(shí),,系統(tǒng)會(huì)自動(dòng)激活最相關(guān)的幾位專家協(xié)同作戰(zhàn)。這樣一來,,不僅運(yùn)算效率提升,,還能控制模型的有效規(guī)模,避免不必要的資源浪費(fèi),。
此外,,DeepSeek大膽采用低精度數(shù)字格式FP8進(jìn)行訓(xùn)練。這種低精度格式在對(duì)精度要求不高的環(huán)節(jié)可以“粗略”計(jì)算,,直接效果是計(jì)算量和內(nèi)存占用大幅下降,,訓(xùn)練速度更快且更省電。關(guān)鍵在于,,這種“偷懶”并不會(huì)明顯犧牲模型的最終性能,。
最后,DeepSeek V3采用了“多平面網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)”,,優(yōu)化了GPU集群內(nèi)部的數(shù)據(jù)傳輸路徑,,減少了擁堵和瓶頸,,確保信息流轉(zhuǎn)順暢。
可以說,,DeepSeek V3的最新論文展示了一種技術(shù)自信,。它表明即便沒有頂級(jí)硬件配置,通過極致的工程優(yōu)化和算法創(chuàng)新,,依然可以打造出具備行業(yè)領(lǐng)先潛力的大模型,。這為那些在算力焦慮中掙扎的追趕者們提供了一條更具可行性的攀登路徑。
實(shí)際上,,4月30日,,DeepSeek還發(fā)布了另一款產(chǎn)品DeepSeek Prover V2,參數(shù)達(dá)到671B,,遠(yuǎn)超上一次發(fā)布的V2模型的7B,。行業(yè)觀察者普遍認(rèn)為,這是AI在輔助科學(xué)發(fā)現(xiàn),,特別是數(shù)學(xué)領(lǐng)域邁出的重要一步,。
近期DeepSeek的一系列動(dòng)作,在當(dāng)前AI大模型產(chǎn)業(yè)背景下顯得尤為引人注目,。一方面,頭部廠商在模型參數(shù),、多模態(tài)能力,、應(yīng)用生態(tài)上全面競(jìng)爭,技術(shù)迭代迅速,,資本熱情高漲,。另一方面,,算力成本攀升,、商業(yè)化路徑尚不清晰以及“智能涌現(xiàn)”后的價(jià)值創(chuàng)造等問題仍懸而未決。
在這種背景下,,DeepSeek V3論文強(qiáng)調(diào)的“成本效益”和“軟硬件協(xié)同”,,以及Prover V2在特定高壁壘領(lǐng)域的深耕,,傳遞出一種不同的信號(hào):在追求更大,、更強(qiáng)的同時(shí),對(duì)效率的極致追求和對(duì)特定價(jià)值場(chǎng)景的深度挖掘可能成為AI下半場(chǎng)競(jìng)爭的關(guān)鍵變量,。
當(dāng)市場(chǎng)開始從對(duì)技術(shù)本身的狂熱轉(zhuǎn)向?qū)?shí)際應(yīng)用價(jià)值的考量時(shí),,那些能夠更聰明地利用現(xiàn)有資源、更精準(zhǔn)地切入真實(shí)需求,、更深入地理解并解決復(fù)雜問題的玩家,,或許才能在喧囂過后笑到最后。DeepSeek的這些“前菜”無疑吊足了市場(chǎng)的胃口,人們期待的不僅僅是一個(gè)性能更強(qiáng)的R2模型,,更是一個(gè)能夠?yàn)樾袠I(yè)帶來新思路,、新變量的DeepSeek。

氣象部門解釋北京冰雹多發(fā)成因 “上冷下熱”對(duì)流所致

北京動(dòng)物園回應(yīng)小鸚鵡被欺負(fù)到禿頂:系親鳥育雛,,已離世 網(wǎng)友心疼關(guān)注

從銷冠到被破產(chǎn)哪吒汽車還有機(jī)會(huì)嗎 銷量下滑財(cái)務(wù)危機(jī)

美政府有人不滿:又想拉黑中企,還要不要跟中國談了? 影響貿(mào)易協(xié)議努力

巴總理講話時(shí)身旁可見新型卡車炮 中巴關(guān)系獲高度評(píng)價(jià)

愛沙尼亞為何在國際水域攔截油輪 北約支援下的未遂扣船事件

澤連斯基指責(zé)普京1小時(shí) 和平前景蒙陰云
從銷冠到被破產(chǎn)哪吒汽車還有機(jī)會(huì)嗎 銷量下滑財(cái)務(wù)危機(jī)

美國一女警被奪槍找掩護(hù)哀求“別開槍” 奪槍男子被另一警察擊斃

挺身而出,,為你點(diǎn)贊,!老人被撞倒在地 路過的消防員伸援手

英媒:英德兩國加強(qiáng)防務(wù)合作 聯(lián)合研發(fā)遠(yuǎn)程武器

騙子開體檢中心專騙老人 涉案資金超2億元

扎哈羅娃大笑回懟澤連斯基“小丑” 俄烏談判未啟口水戰(zhàn)先燃

娃哈哈變得面目全非令人唏噓 宗馥莉改革引發(fā)爭議
巴媒發(fā)布印巴空戰(zhàn)內(nèi)幕有何意味 殲-10CE一戰(zhàn)封神

印尼審查陣風(fēng)訂單釋放何信號(hào) 引發(fā)重新評(píng)估

如何有效緩解日常焦慮 專家支招應(yīng)對(duì)方法

兩大中概科技巨頭,暴漲暴跌互現(xiàn),!阿里網(wǎng)易表現(xiàn)分化
北京動(dòng)物園回應(yīng)小鸚鵡被欺負(fù)到禿頂:系親鳥育雛,已離世 網(wǎng)友心疼關(guān)注
全家進(jìn)醫(yī)院,!只因這道常見菜……
大V:普京不與澤連斯基面談?dòng)?原因 體制與個(gè)人因素交織
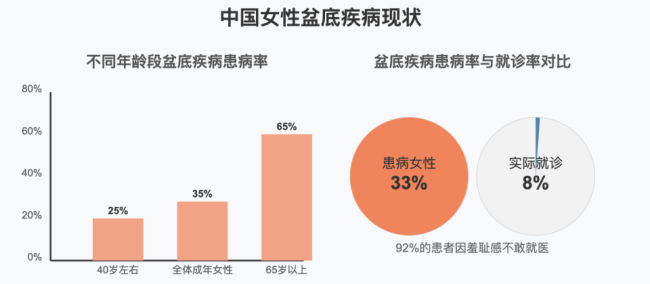
30%的女性受漏尿困擾,卻極少有人就醫(yī),,盆底疾病為何如此隱秘,?

39歲女子賣17年輪胎后回村烤面包 顧客排隊(duì)成常態(tài)

訪問卡塔爾期間 特朗普再次吹噓“六代機(jī)” 還要把F-35升級(jí)為雙引擎 言論引發(fā)廣泛關(guān)注

端午節(jié)放假不調(diào)休 購票日歷出爐

00后學(xué)霸民警接警后秒變“家教” 網(wǎng)友:能跨省執(zhí)法不?

俄“中央”集群司令莫爾德維切夫或成新一任俄陸軍總司令 接替薩柳科夫

特朗普稱不對(duì)普京缺席談判失望 局勢(shì)需直接對(duì)話解決
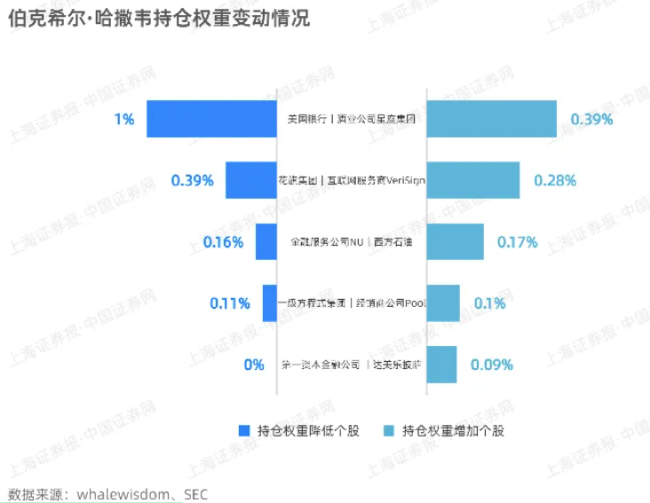
一圖看懂巴菲特持倉變化 權(quán)威數(shù)據(jù)解析,!
雷軍內(nèi)部演講回應(yīng)質(zhì)疑 直面問題承擔(dān)責(zé)任

胡塞武裝差點(diǎn)擊落F-35,,背后科技揭秘 美軍高科技遇游擊戰(zhàn)

巴基斯坦為何在印巴輿論戰(zhàn)中占上風(fēng) 軍事與外交雙勝利

卡塔爾投資局CEO:計(jì)劃未來十年在美國投資5000億美元,聚焦高科技領(lǐng)域
氣象部門解釋北京冰雹多發(fā)成因 “上冷下熱”對(duì)流所致

女裝店主稱網(wǎng)購翻車因?yàn)槭鄢鍪羌儇洠耗L厣砩系膬r(jià)值799,,賣給你的是399
相關(guān)新聞
DeepSeek官方辟謠R2發(fā)布 假消息被澄清
2025-03-12 07:51:52DeepSeek官方辟謠R2發(fā)布外界熱議DeepSeek低調(diào)“上新” V4與R2猜想再起
中國人工智能初創(chuàng)公司深度求索(DeepSeek)24日深夜低調(diào)上線了DeepSeek-V3的新版本DeepSeek-V3-0324,,參數(shù)量為6850億
2025-03-26 14:15:56外界熱議DeepSeek低調(diào)上新DeepSeek:R2發(fā)布為假消息 官方辟謠澄清
2025-03-12 08:13:48DeepSeekDeepSeek官方:R2發(fā)布為假消息 正式辟謠澄清
2025-03-11 20:00:34DeepSeek官方消息人士稱DeepSeek正加速推出R2模型 計(jì)劃提前曝光
觀點(diǎn)網(wǎng)訊:2月25日,,據(jù)路透援引消息人士稱,,DeepSeek正在加速推出其R2人工智能模型,其最初計(jì)劃在五月推出,,但目前正在努力盡快推出
2025-02-26 08:43:51消息人士稱DeepSeek正加速推出R2模型AI密度最高的城市,,又放了個(gè)大招 從娃娃抓起的教育變革
2025-03-19 13:13:11AI密度最高的城市