北大DeepSeek論文或預(yù)定ACL Best Paper!梁文鋒署名 引領(lǐng)算力效率競賽

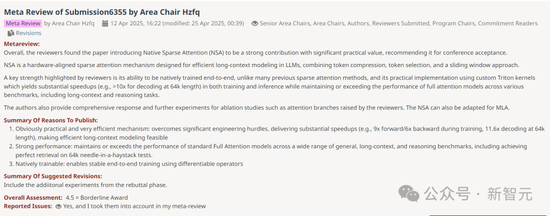
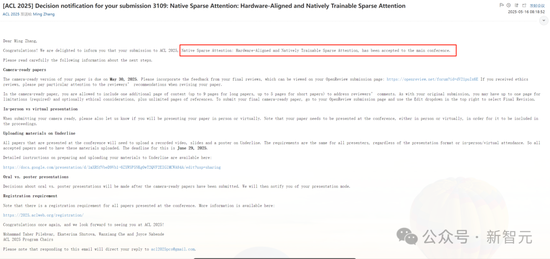
北大DeepSeek論文或預(yù)定ACL Best Paper,!梁文鋒署名 引領(lǐng)算力效率競賽,。北京大學(xué)與DeepSeek合作的論文有望獲得ACL 2025最佳論文獎,。該論文由梁文鋒親自提交到arXiv,,地址為https://arxiv.org/abs/2502.11089,。今年ACL的投稿數(shù)量達(dá)到了創(chuàng)紀(jì)錄的8000多篇,,幾乎是去年4407篇的兩倍,。原生稀疏注意力(Native Sparse Attention, NSA)論文在Meta Review中獲得了4.5分的高分,接近滿分5分,。根據(jù)ACL的評分標(biāo)準(zhǔn),,這一分?jǐn)?shù)已經(jīng)獲得了Borderline Award,意味著有很高的機(jī)會獲得最佳論文,。

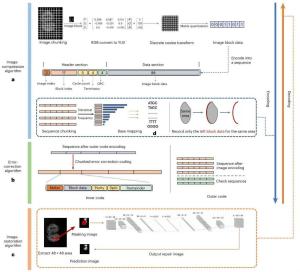
NSA技術(shù)將AI行業(yè)的焦點(diǎn)從模型規(guī)模競賽轉(zhuǎn)向算力效率競賽,成為2025年上半年最具影響力的底層技術(shù)突破之一,。DeepSeek-R1的發(fā)布引發(fā)了AI行業(yè)的價值重估,,其低成本和同效能的開源技術(shù)改變了人們“有卡才行”的傳統(tǒng)認(rèn)知。NSA進(jìn)一步實現(xiàn)了長下文的算力平權(quán),,使開源模型也能達(dá)到閉源模型如ChatGPT,、Gemini等才能滿足的上下文窗口。NSA將長文本處理速度提高了最多11倍,,通過算法創(chuàng)新和硬件改進(jìn)提高效率而不犧牲性能,。

NSA是對傳統(tǒng)注意力機(jī)制的一次革新,。傳統(tǒng)模型依賴全注意力機(jī)制,,每個Token與其他所有Token進(jìn)行比較,雖然對短文本有效,,但隨著文本長度增加,,計算成本顯著上升。NSA采用了動態(tài)分層的稀疏策略,,通過三條并行的注意力分支來處理輸入序列:壓縮注意力,、選擇性注意力和滑動注意力。這種設(shè)計不僅平衡了計算密度,,還針對現(xiàn)代硬件進(jìn)行了優(yōu)化,,顯著提升了運(yùn)行速度,并實現(xiàn)了端到端的訓(xùn)練模式,在確保模型性能的前提下大幅降低了預(yù)訓(xùn)練的計算量,。

除了NSA論文外,張銘教授團(tuán)隊還有其他幾篇論文上榜,。其中一篇是首個從數(shù)據(jù)中心視角系統(tǒng)性剖析LLM高效后訓(xùn)練的綜述,提出了涵蓋數(shù)據(jù)選擇,、質(zhì)量增強(qiáng),、合成數(shù)據(jù)生成、數(shù)據(jù)蒸餾與壓縮及自演化數(shù)據(jù)生態(tài)的分類框架,。另一篇是首個大規(guī)模,、高質(zhì)量的金融多模態(tài)評估數(shù)據(jù)集FinMME,包含超過11,200個金融研究樣本,,覆蓋18個核心金融領(lǐng)域和10種主要圖表類型,。此外,還有一篇關(guān)于大語言模型中的數(shù)學(xué)推理增強(qiáng)方法,,提出了一種創(chuàng)新的Safe驗證框架,,從根本上識別并消除幻覺。最后,,還有一篇基于大語言模型的交通流量預(yù)測方法,,提出了一種新的LEAF方法,利用大語言模型的判別能力來提高預(yù)測準(zhǔn)確性,。
這些研究成果展示了北京大學(xué)和DeepSeek在AI領(lǐng)域的前沿探索和技術(shù)突破。


戶外大牌為何此時組隊重返中國 市場機(jī)遇再現(xiàn)

C919執(zhí)飛上海虹橋-深圳航線開通 國產(chǎn)大飛機(jī)再添新航線
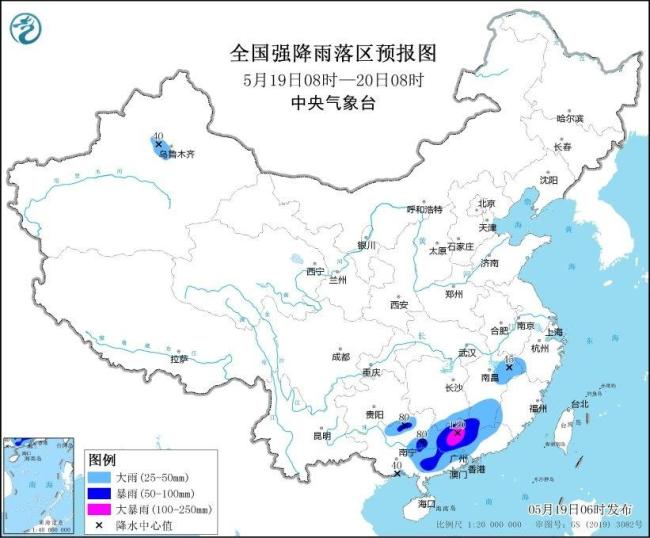
廣東北部等地部分地區(qū)有大暴雨 警惕地質(zhì)災(zāi)害

3男子每天給共享單車蓋四五百個廣告章 被警方行拘

莫迪為何開始對土耳其阿塞拜疆發(fā)難 民粹情緒的反噬

德一客機(jī)“無人駕駛”飛10分鐘 副駕突發(fā)疾病暈倒

郭俊辰:林南一是傲嬌小貓,自己是小貓狗

馬科斯為何放棄對莎拉的彈劾案 選舉失利引發(fā)政治算計失敗

印度增兵克什米爾,,但火箭發(fā)射又失敗 軍事布局受挫

專家:全球熱議的殲10C在國內(nèi)算低端 巴基斯坦空戰(zhàn)表現(xiàn)引關(guān)注

歐盟向美國強(qiáng)硬要價 特朗普會妥協(xié)嗎 火燒眉毛的抉擇
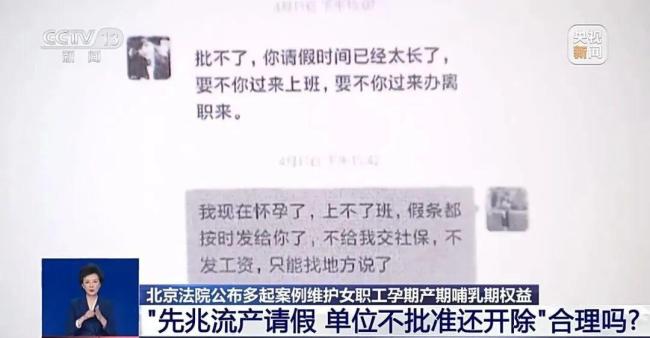
女子先兆流產(chǎn)請假,,單位不批還開除!法院:賠付7萬余元 孕期權(quán)益受保護(hù)

知情人士談紐約撞橋事故 傷亡情況更新
C919執(zhí)飛上海虹橋-深圳航線開通 國產(chǎn)大飛機(jī)再添新航線

拜登癌細(xì)胞擴(kuò)散至骨骼 前列腺癌的早期癥狀

專家:特朗普關(guān)稅政策或?qū)⒎磸?fù)搖擺 單邊主義引發(fā)全球經(jīng)濟(jì)裂痕
廣東北部等地部分地區(qū)有大暴雨 警惕地質(zhì)災(zāi)害

武漢硚口區(qū)傷人案致1死 警方通報 因糾紛引發(fā)

男人養(yǎng)家的焦慮:家庭風(fēng)暴中的掙扎與無奈 中年壓力下的自我補(bǔ)償

AI虛假廣告頻發(fā)應(yīng)該如何區(qū)分 多方合力凈化市場

以色列轟炸加沙難民營 導(dǎo)彈落在婦女兒童身邊 無辜平民再遭血與火洗禮
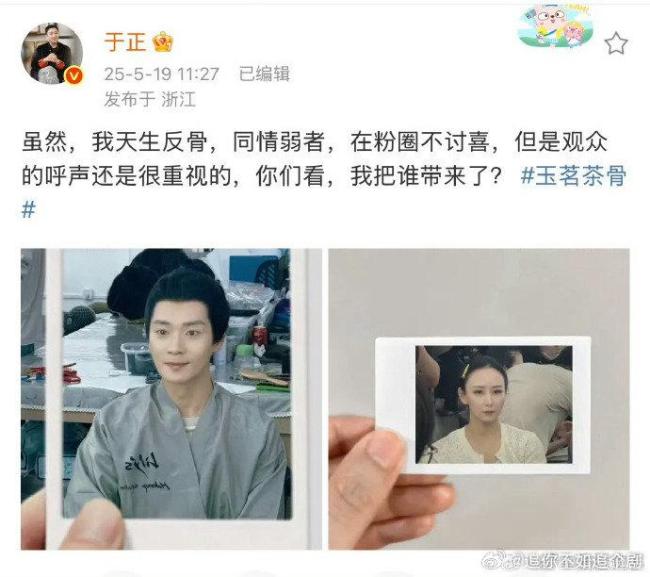
曹駿胡靜進(jìn)組《玉茗茶骨》,,于正官宣新劇陣容
金價坐上“過山車”下一步怎么走 機(jī)構(gòu)建議長期配置

民進(jìn)黨臺南市長初選陳亭妃民調(diào)領(lǐng)先 黨內(nèi)競爭白熱化

樊振東喊話青少年面對毒品堅決說不 守護(hù)青春的冠軍姿態(tài)

樊振東解鎖新身份 青少年禁毒大使

卡塔爾稱希望美伊達(dá)成持久核協(xié)議 外交突破或在醞釀中

走私爆珠煙“圍獵”年輕人 灰色銷售網(wǎng)絡(luò)威脅健康

英媒:梅洛尼與馬克龍因烏克蘭問題爆發(fā)爭執(zhí),,德國總理默茨試圖調(diào)解

網(wǎng)紅“英之園”,誰建了潮汕天價違建,? 1.14億元違建引關(guān)注

特朗普上任100天提及拜登580次 宿敵之爭再升級

澤連斯基與美國副總統(tǒng)及國務(wù)卿會談 討論伊斯坦布爾談判等問題 烏美共商?;鹋c合作

泰國DJ與毒梟老大女友有染遭槍殺 毒梟情仇引震驚

俄烏伊斯坦布爾談判舉行,能否成為俄烏沖突轉(zhuǎn)折點(diǎn),? 歷史性對話開啟
戶外大牌為何此時組隊重返中國 市場機(jī)遇再現(xiàn)
相關(guān)新聞
DeepSeek公布推理新論文 提升獎勵模型可擴(kuò)展性
2025-04-05 15:41:35DeepSeek公布推理新論文R2來之前 DeepSeek又放了個煙霧彈 V3論文揭示降本增效秘籍
2025-05-16 14:06:03R2來之前DeepSeek又放了個煙霧彈DeepSeek發(fā)布新論文 梁文鋒是共創(chuàng) NSA機(jī)制革新長文本處理
2025-02-18 20:31:32DeepSeek發(fā)布新論文梁文鋒是共創(chuàng)教培機(jī)構(gòu)宣稱4999元論文無憂,!論文代寫亂象調(diào)查
2025-03-27 11:24:48教培機(jī)構(gòu)宣稱4999元論文無憂論文男女不分僅處理作者遠(yuǎn)遠(yuǎn)不夠 需破除“唯論文”傾向
2025-05-06 17:10:50論文男女不分僅處理作者遠(yuǎn)遠(yuǎn)不夠官方回應(yīng)論文提輸卵管妊娠男患者 醫(yī)院展開調(diào)查并下架論文
2025-05-07 23:47:56官方回應(yīng)論文提輸卵管妊娠男患者