DeepSeek公布推理新論文 提升獎勵模型可擴(kuò)展性

DeepSeek R2的研究成果已經(jīng)接近,。最近,,DeepSeek和清華大學(xué)的研究者發(fā)表了一篇論文,探討了獎勵模型在推理時的Scaling方法,。
強(qiáng)化學(xué)習(xí)(RL)已廣泛應(yīng)用于大規(guī)模語言模型(LLM)的后訓(xùn)練階段。通過RL激勵LLM的推理能力表明,,采用合適的學(xué)習(xí)方法可以實(shí)現(xiàn)有效的推理時可擴(kuò)展性,。然而,RL面臨的一個關(guān)鍵挑戰(zhàn)是在多種領(lǐng)域中為LLM獲得準(zhǔn)確的獎勵信號,。
研究者發(fā)現(xiàn),,在獎勵建模(RM)方法上采用點(diǎn)式生成式獎勵建模(GRM),可以提升模型對不同輸入類型的靈活適應(yīng)能力,,并具備推理階段可擴(kuò)展的潛力,。為此,他們提出了一種自我原則點(diǎn)評調(diào)優(yōu)(SPCT)的學(xué)習(xí)方法,。這種方法通過在線RL訓(xùn)練促進(jìn)GRM生成具備可擴(kuò)展獎勵能力的行為,,即能夠自適應(yīng)生成評判原則并準(zhǔn)確生成點(diǎn)評內(nèi)容,從而得到DeepSeek-GRM模型,。
DeepSeek-GRM-27B是基于Gemma-2-27B經(jīng)過SPCT后訓(xùn)練的,。實(shí)驗(yàn)結(jié)果表明,SPCT顯著提高了GRM的質(zhì)量和可擴(kuò)展性,,在多個綜合RM基準(zhǔn)測試中優(yōu)于現(xiàn)有方法和模型,。研究者還比較了DeepSeek-GRM-27B與671B更大模型的推理時間擴(kuò)展性能,發(fā)現(xiàn)它在模型大小上的訓(xùn)練時間擴(kuò)展性能更好。此外,,他們引入了一個元獎勵模型(meta RM)來引導(dǎo)投票過程,,以提升擴(kuò)展性能。
研究者的貢獻(xiàn)包括:提出了一種新方法——自我原則點(diǎn)評調(diào)優(yōu)(SPCT),,用于推動通用獎勵建模在推理階段實(shí)現(xiàn)有效的可擴(kuò)展性,;SPCT顯著提升了GRM在獎勵質(zhì)量和推理擴(kuò)展性能方面的表現(xiàn),超過了現(xiàn)有方法及多個強(qiáng)勁的公開模型,;將SPCT的訓(xùn)練流程應(yīng)用于更大規(guī)模的LLM,,并發(fā)現(xiàn)相比于訓(xùn)練階段擴(kuò)大模型參數(shù)量,推理階段的擴(kuò)展策略在性能上更具優(yōu)勢,。

為這個女警隊(duì)點(diǎn)贊,!她們是200多個孩子的緊急聯(lián)系人

車展內(nèi)外齊發(fā)力 帶火汽車消費(fèi)熱 政策補(bǔ)貼助推市場活力
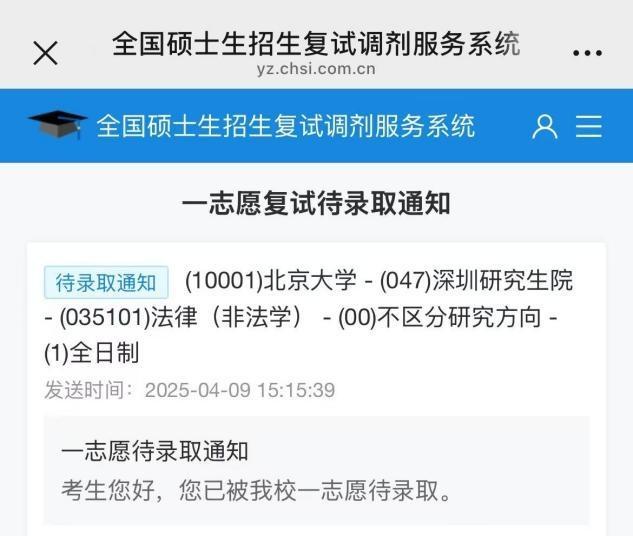
兒子瞞著父母考上北大研究生 媽媽得知后震驚 驚喜讓媽媽笑醒

鄧卓翔:全力以赴對待與津門虎的比賽 積極備戰(zhàn)迎接挑戰(zhàn)

花了近7000訂到假五星酒店 平臺獨(dú)特評分引爭議

停火結(jié)束戰(zhàn)爭繼續(xù),,普京宣布恢復(fù)攻勢 雙方互指違反協(xié)議
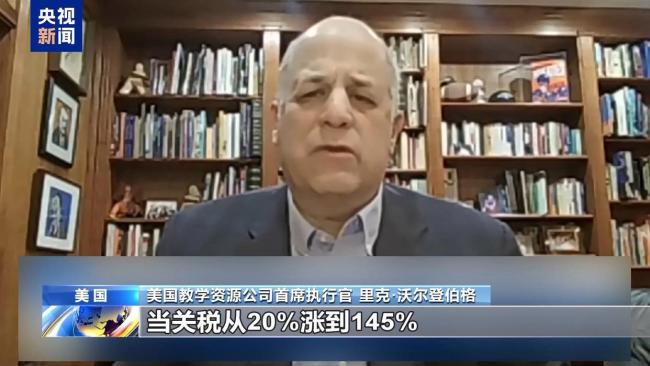
美玩具公司因關(guān)稅政策起訴美政府 中小企業(yè)維權(quán)之戰(zhàn)

美軍戰(zhàn)略轟炸機(jī)進(jìn)駐日本想演給誰看 加劇亞太安全困境
車展內(nèi)外齊發(fā)力 帶火汽車消費(fèi)熱 政策補(bǔ)貼助推市場活力

84斤女子稱買百件衣服穿不上 網(wǎng)購尺碼困擾多

金正恩攜女兒出席朝鮮人民軍新型驅(qū)逐艦入水儀式 稱“將一刻不停地建設(shè)海軍”

美關(guān)稅政策重創(chuàng)美電商行業(yè) 跨境電商面臨嚴(yán)峻考驗(yàn)

韓國殘運(yùn)會盒飯只有海苔泡菜 簡陋餐食引爭議

和澤連斯基見面后 特朗普質(zhì)疑普京 是否真心結(jié)束沖突
為這個女警隊(duì)點(diǎn)贊!她們是200多個孩子的緊急聯(lián)系人

中美未來關(guān)稅戰(zhàn)的局勢將如何發(fā)展 或?qū)⒂瓉泶蠼Y(jié)局

印巴一旦打起來后果有多嚴(yán)重 中國角色成關(guān)鍵
兒子瞞著父母考上北大研究生 媽媽得知后震驚 驚喜讓媽媽笑醒
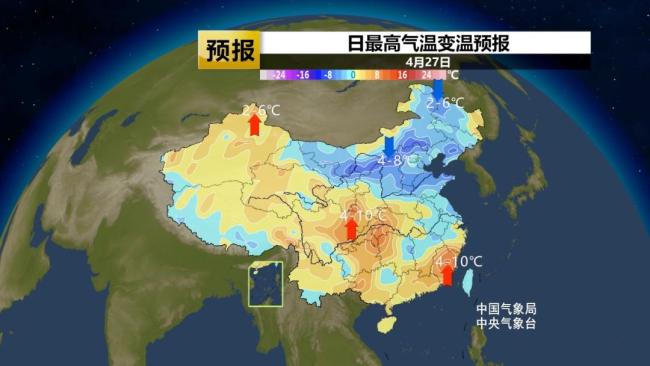
五一期間南方30℃以上區(qū)域擴(kuò)張 多地將現(xiàn)高溫天氣

超市老板投資賺千萬全給員工 兌現(xiàn)承諾分享幸福

47歲劉燁現(xiàn)身上海,,暴瘦成紙片人!此前已許久未在公眾視野露面 硬漢男神判若兩人

董明珠“海歸間諜論”引起爭議 海歸價(jià)值再審視

美國對烏不愿接受領(lǐng)土讓步感到憤怒 會談破裂引發(fā)關(guān)注

印度未通知開閘泄洪,巴基斯坦多地水位大幅上升面臨洪災(zāi)風(fēng)險(xiǎn)

看似周日,,實(shí)則周一,!

伊朗最大港口爆炸是以色列干的嗎 事件蒙上神秘面紗

普京為何匆忙宣布庫爾斯克解放 勝利日臨近壓力大

馬斯克稱5月起工作重心將轉(zhuǎn)回企業(yè) 專注特斯拉項(xiàng)目

南方人更愛泡影院!男性電影觀眾占比反超女性 華中成“觀影卷王”

出現(xiàn)在上海小區(qū)的狐貍已死亡 身份成謎引發(fā)討論

航拍中國黃巖島絕美風(fēng)景 碧海藍(lán)天詩意畫卷

特朗普:讓加拿大加入美沒開玩笑 言論引發(fā)爭議

美國嚴(yán)格執(zhí)行人類清除計(jì)劃 芬太尼提案引爭議

菲律賓能選出親華總統(tǒng)嗎,?中美都在等結(jié)果

太揪心,!浙江高速突發(fā),高速交警嘶吼喊話司機(jī):“別睡,,家人在等你,!”
相關(guān)新聞
DeepSeek發(fā)布新論文 梁文鋒是共創(chuàng) NSA機(jī)制革新長文本處理
2025-02-18 20:31:32DeepSeek發(fā)布新論文梁文鋒是共創(chuàng)英偉達(dá)創(chuàng)滿血DeepSeek推理世界紀(jì)錄 性能顯著提升
英偉達(dá)在NVIDIA GTC 2025上宣布,,其NVIDIA Blackwell DGX系統(tǒng)創(chuàng)下DeepSeek-R1大模型推理性能的世界紀(jì)錄
2025-03-20 09:03:59英偉達(dá)創(chuàng)滿血DeepSeek推理世界紀(jì)錄DeepSeek崛起對AI芯片行業(yè)有何影響 推動推理芯片需求增長
2025-02-08 09:31:04DeepSeek崛起對AI芯片行業(yè)有何影響DeepSeek利好哪些AI基建產(chǎn)業(yè)鏈環(huán)節(jié) 推理需求增長帶動新機(jī)遇
DeepSeek震動硅谷,其高性價(jià)比的訓(xùn)練技術(shù)引發(fā)了市場的廣泛關(guān)注
2025-02-02 11:44:50DeepSeek利好哪些AI基建產(chǎn)業(yè)鏈環(huán)節(jié)黃仁勛揭秘下一代芯片Rubin,,英偉達(dá)想要吃“DeepSeek紅利” 推理時代的新機(jī)遇
2025-03-19 12:03:54黃仁勛揭秘下一代芯片RubinDeepSeek評價(jià)Manus AI新黑馬崛起
2025-03-07 12:11:05DeepSeek評價(jià)Manus