DeepSeek公布推理新論文 提升獎(jiǎng)勵(lì)模型可擴(kuò)展性(2)

研究者的貢獻(xiàn)包括:提出了一種新方法——自我原則點(diǎn)評(píng)調(diào)優(yōu)(SPCT),用于推動(dòng)通用獎(jiǎng)勵(lì)建模在推理階段實(shí)現(xiàn)有效的可擴(kuò)展性,;SPCT顯著提升了GRM在獎(jiǎng)勵(lì)質(zhì)量和推理擴(kuò)展性能方面的表現(xiàn),,超過(guò)了現(xiàn)有方法及多個(gè)強(qiáng)勁的公開模型,;將SPCT的訓(xùn)練流程應(yīng)用于更大規(guī)模的LLM,,并發(fā)現(xiàn)相比于訓(xùn)練階段擴(kuò)大模型參數(shù)量,推理階段的擴(kuò)展策略在性能上更具優(yōu)勢(shì),。
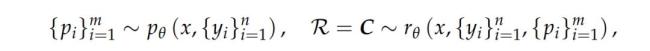
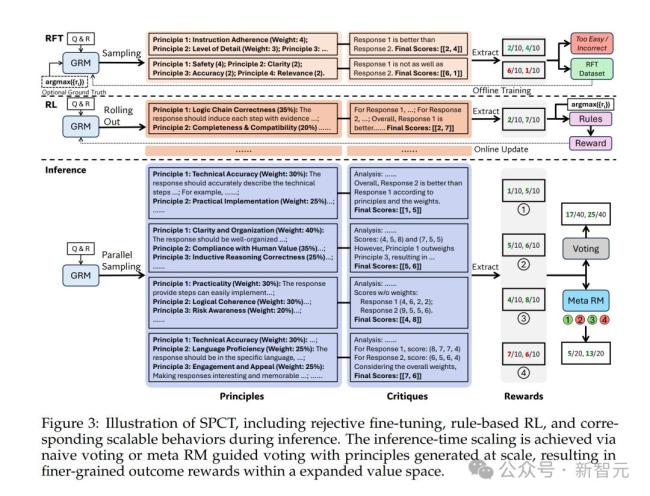
SPCT方法包括兩個(gè)階段:拒絕式微調(diào)作為冷啟動(dòng)階段,,以及基于規(guī)則的在線強(qiáng)化學(xué)習(xí)。拒絕式微調(diào)的核心思想是讓GRM適應(yīng)不同輸入類型,,并以正確的格式生成原則與點(diǎn)評(píng)內(nèi)容,。基于規(guī)則的在線強(qiáng)化學(xué)習(xí)則進(jìn)一步微調(diào)GRM,,通過(guò)提升生成的原則和點(diǎn)評(píng)內(nèi)容來(lái)強(qiáng)化通用獎(jiǎng)勵(lì)的生成過(guò)程,。
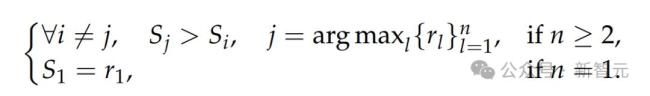
為了提升DeepSeek-GRM在生成通用獎(jiǎng)勵(lì)上的性能,研究團(tuán)隊(duì)探索了如何利用更多的推理計(jì)算,,通過(guò)基于采樣的策略來(lái)實(shí)現(xiàn)有效的推理時(shí)擴(kuò)展,。逐點(diǎn)GRM投票過(guò)程被定義為將獎(jiǎng)勵(lì)求和,這實(shí)際上將獎(jiǎng)勵(lì)空間擴(kuò)大了k倍,,使GRM能生成大量原則,,從而提升最終獎(jiǎng)勵(lì)的質(zhì)量和細(xì)膩度。為了避免位置偏差并增加多樣性,,研究人員在采樣前會(huì)對(duì)回答進(jìn)行隨機(jī)打亂,。

曝鞠婧祎羅云熙將出演《和離》 選角引發(fā)熱議

林高遠(yuǎn)2比4李尚洙 國(guó)乒男單接近全軍覆沒

朱雨玲4比2逆轉(zhuǎn)大藤沙月 寶刀不老晉級(jí)四強(qiáng)

郭正亮痛罵民進(jìn)黨當(dāng)局“混蛋” 執(zhí)政無(wú)能引發(fā)民眾憤怒
全紅嬋18歲首戰(zhàn)再現(xiàn)“水花消失術(shù)” 科學(xué)訓(xùn)練打破發(fā)育魔咒

學(xué)者:特朗普關(guān)稅戰(zhàn) 俄別想幸免 全球震蕩不斷

遭遇特朗普關(guān)稅霸凌 世界看向中國(guó) 全球迎來(lái)不確定性日

吳宣儀:在學(xué)了在學(xué)了 好心辦壞事

以軍轟炸加沙地帶多地 至少5人死亡 多人受傷伴隨

《烏云之上》韓青查案智斗罪犯 懸疑劇情撲朔迷離

王楚欽調(diào)侃隊(duì)友繩梯訓(xùn)練 協(xié)調(diào)性真好引發(fā)熱議

大V:巴西成美國(guó)全球加稅最大贏家 大豆牛肉或成替代品

蒯曼0-4張本美和 無(wú)緣仁川賽4強(qiáng) 國(guó)乒新星遭遇挑戰(zhàn)
林高遠(yuǎn)2比4李尚洙 國(guó)乒男單接近全軍覆沒

幼師抓傷幼兒臉被判賠償4萬(wàn) 事件引發(fā)社會(huì)熱議

關(guān)稅戰(zhàn)升級(jí) 中國(guó)股市未來(lái)怎么走 結(jié)構(gòu)性機(jī)會(huì)顯現(xiàn)

北約外長(zhǎng)會(huì)草草落幕凸顯嚴(yán)重分歧 內(nèi)部矛盾加深

福建一地清明節(jié)祭祖時(shí)數(shù)車起火 傳統(tǒng)與安全的沖突再現(xiàn)

特朗普圍堵中國(guó)商品 企業(yè)如何應(yīng)對(duì) 關(guān)稅戰(zhàn)下的突圍策略
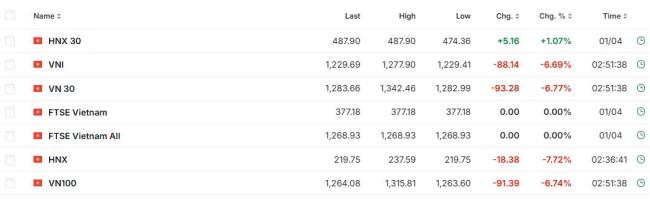
美加關(guān)稅后首個(gè)“扛不住”國(guó)家出現(xiàn) 越南股市暴跌警示全球化危機(jī)

中國(guó)對(duì)所有美商品對(duì)等加稅影響幾何 重塑貿(mào)易格局

英國(guó)王查爾斯用胡蘿卜演奏兒歌 國(guó)王的蔬菜音樂會(huì)
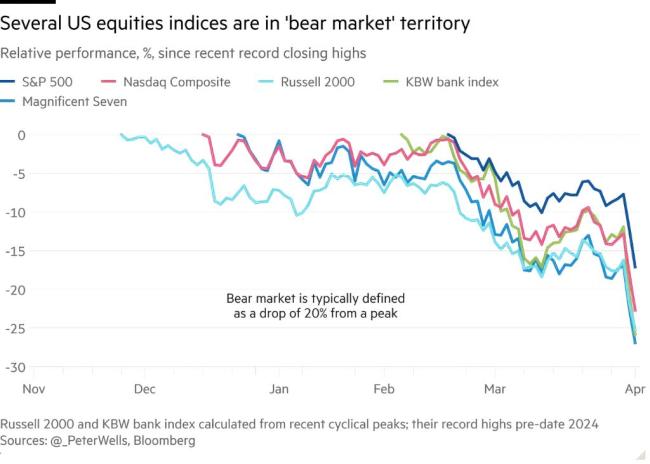
美股暴跌兩日 6萬(wàn)億美元“灰飛煙滅” 市場(chǎng)恐慌情緒高漲

蒯曼無(wú)緣仁川賽四強(qiáng) 張本美和狀態(tài)爆棚
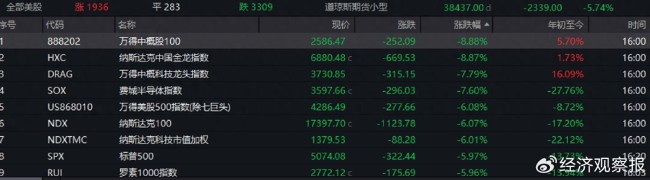
美國(guó)科技七巨頭指數(shù)暴跌5.62% 美股三大指數(shù)蒸發(fā)3萬(wàn)億美元

外刊:特朗普“讓中國(guó)再次偉大” 關(guān)稅政策反助中國(guó)機(jī)遇
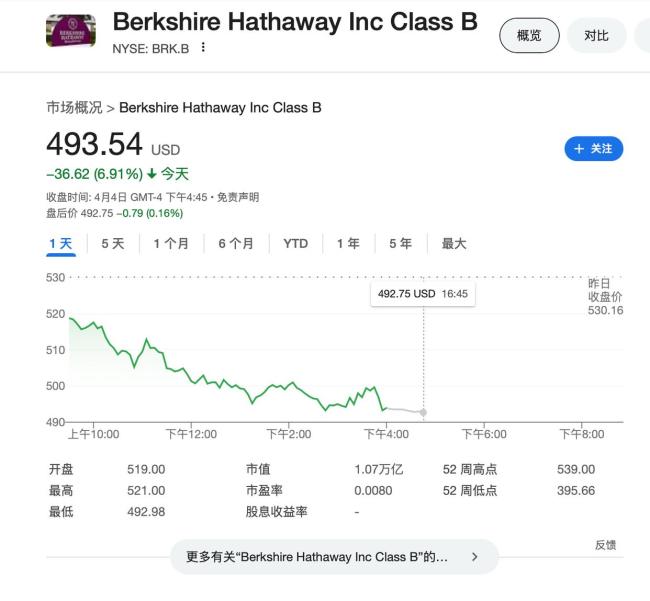
伯克希爾辟謠:社交媒體上關(guān)于巴菲特講話的消息都是虛假的 假言論誤導(dǎo)公眾
朱雨玲4比2逆轉(zhuǎn)大藤沙月 寶刀不老晉級(jí)四強(qiáng)

專家解釋中國(guó)為何敢硬剛美國(guó) 三大底氣支撐

深圳地鐵站否認(rèn)發(fā)生踩踏事故 網(wǎng)傳視頻不實(shí)
曝鞠婧祎羅云熙將出演《和離》 選角引發(fā)熱議

從甲亢哥玩具看中國(guó)制造速度 文化破壁者的意外使命

手機(jī)曲面屏怎么消失了 用戶體驗(yàn)與市場(chǎng)選擇

美國(guó)開始擔(dān)心伊朗先下手為強(qiáng)了 B-2轟炸機(jī)暴露風(fēng)險(xiǎn)

特朗普就職以來(lái)美股蒸發(fā)8萬(wàn)億美元 經(jīng)濟(jì)震蕩引發(fā)全球關(guān)注
相關(guān)新聞
DeepSeek發(fā)布新論文 梁文鋒是共創(chuàng) NSA機(jī)制革新長(zhǎng)文本處理
2025-02-18 20:31:32DeepSeek發(fā)布新論文梁文鋒是共創(chuàng)英偉達(dá)創(chuàng)滿血DeepSeek推理世界紀(jì)錄 性能顯著提升
英偉達(dá)在NVIDIA GTC 2025上宣布,,其NVIDIA Blackwell DGX系統(tǒng)創(chuàng)下DeepSeek-R1大模型推理性能的世界紀(jì)錄
2025-03-20 09:03:59英偉達(dá)創(chuàng)滿血DeepSeek推理世界紀(jì)錄DeepSeek崛起對(duì)AI芯片行業(yè)有何影響 推動(dòng)推理芯片需求增長(zhǎng)
2025-02-08 09:31:04DeepSeek崛起對(duì)AI芯片行業(yè)有何影響DeepSeek利好哪些AI基建產(chǎn)業(yè)鏈環(huán)節(jié) 推理需求增長(zhǎng)帶動(dòng)新機(jī)遇
DeepSeek震動(dòng)硅谷,其高性價(jià)比的訓(xùn)練技術(shù)引發(fā)了市場(chǎng)的廣泛關(guān)注
2025-02-02 11:44:50DeepSeek利好哪些AI基建產(chǎn)業(yè)鏈環(huán)節(jié)黃仁勛揭秘下一代芯片Rubin,,英偉達(dá)想要吃“DeepSeek紅利” 推理時(shí)代的新機(jī)遇
2025-03-19 12:03:54黃仁勛揭秘下一代芯片RubinDeepSeek評(píng)價(jià)Manus AI新黑馬崛起
2025-03-07 12:11:05DeepSeek評(píng)價(jià)Manus