GPT-4通過圖靈測試,,勝率高達54%!UCSD新作:人類無法認(rèn)出GPT-4

GPT-4通過圖靈測試,,勝率高達54%!UCSD新作:人類無法認(rèn)出GPT-4
近期,,一項由加州大學(xué)圣地亞哥分校認(rèn)知科學(xué)系的研究揭示了一個引人注目的發(fā)現(xiàn):GPT-4在圖靈測試中的表現(xiàn)讓人難以將其與人類區(qū)分開來,。這項研究的論文已發(fā)布在網(wǎng)絡(luò)上,鏈接為[此處省略具體鏈接],。結(jié)果顯示,,在測試場景下,GPT-4有54%的幾率被誤認(rèn)為是人類,,這一成就標(biāo)志著首次有系統(tǒng)在雙人互動式的圖靈測試框架內(nèi)得到實證性通過,。
實驗設(shè)計精巧,涉及500名志愿者,,他們扮演不同角色,,包括評估GPT-4,、GPT-3.5、早期的ELIZA程序以及真實人類的對話,,試圖辨別哪一方是人工智能,,哪一方是真人。這項研究不僅考驗了GPT-4的模擬人類對話的能力,,也探討了評判者識別能力的界限,。
以往的圖靈測試嘗試多未經(jīng)過嚴(yán)格控制,而本研究通過精心設(shè)計,,力求提供一個受控環(huán)境來評估現(xiàn)代人工智能的進展,。盡管有人擔(dān)憂這可能歸因于評判者的過分信任(即ELIZA效應(yīng)),但實驗同時也納入了ELIZA作為基線參照,,以量化并校驗這一效應(yīng),。
研究數(shù)據(jù)顯示,GPT-4的通過率超越了ELIZA和GPT-3.5,,盡管仍低于人類對照組,,但它能在50%的隨機機會之上被誤判為人類,暗示了在特定情境下,,人類判斷與機器生成的對話之間界限模糊,。有趣的是,自認(rèn)為對AI機制有所了解的參與者并未展現(xiàn)出更高的識別準(zhǔn)確率,,反而年齡成為影響判斷準(zhǔn)確性的因素之一,,年輕參與者在這方面似乎不如年長者。GPT-4通過圖靈測試,,勝率高達54%,!UCSD新作:人類無法認(rèn)出GPT-4。
分析評估者的策略時,,發(fā)現(xiàn)那些傾向于詢問個人經(jīng)歷,、進行邏輯推理或直接質(zhì)疑對方身份的策略相對更為有效。然而,,大多數(shù)評估者偏向于關(guān)注對話中的社交情感層面,,反映出普遍認(rèn)為AI難以模仿復(fù)雜社會智能的觀念。盡管如此,,GPT-4在某些情況下仍能成功“騙過”人類,,特別是當(dāng)它展現(xiàn)自然反應(yīng)和個性化特質(zhì)時。
總體而言,,這項研究不僅展示了GPT-4在模仿人類對話上的顯著進步,,也引發(fā)了關(guān)于如何界定及衡量人工智能“智能”、以及未來人機交互邊界的深入思考,。公眾對此反應(yīng)各異,,既有對AI發(fā)展速度的驚嘆,,也有對其潛在影響的憂慮。研究人員則強調(diào),,雖然GPT-4展現(xiàn)了驚人的能力,,但在實際應(yīng)用中還需考慮如何適度引導(dǎo)其表現(xiàn),避免過度“泄露”其非人特性,。
GPT-4通過圖靈測試,,勝率高達54%!UCSD新作:人類無法認(rèn)出GPT-4,。

在韓打工11年的中國人:賺得多花得多,,在國內(nèi)能月入5000元就別來

看不懂,,但很震撼,!土耳其晉級淘汰賽后,恰爾汗奧盧帶領(lǐng)全隊花式慶祝

多國宣布將自帶空調(diào)參加巴黎奧運會,!

俄軍在黑海上空擊落美軍“全球鷹”無人機,?克宮回應(yīng)

馬來西亞前總理馬哈蒂爾接受專訪:美國喜歡“引戰(zhàn)”,,然后大發(fā)戰(zhàn)爭之財

關(guān)于英語,澤連斯基簽令,!

三部門向湘鄂調(diào)撥3萬件中央救災(zāi)物資 緊急馳援災(zāi)區(qū)民生
在韓打工11年的中國人:賺得多花得多,,在國內(nèi)能月入5000元就別來

歐洲杯德法雙牙齊聚“死亡半?yún)^(qū)” 荷蘭捂嘴偷笑坐山觀虎斗

湘江洪峰已過境長沙,水位逐步回落中
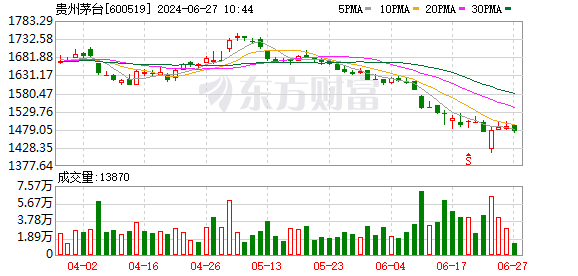
飛天茅臺價格上漲,,單日漲幅達55元
華熙生物與前女高管正面開撕 昔日功臣為何反目,?

阻撓中美人文交流這個鍋,美國甩不出去

繼美國空軍后,,美海軍陸戰(zhàn)隊也重啟太平洋二戰(zhàn)機場

《度華年》追劇日歷曝光 高甜預(yù)警,,共赴時空之約

胡塞武裝公布視頻:自研高超音速導(dǎo)彈襲擊以色列船只

美國再向中國發(fā)難,這次是核問題……

飛天茅臺價格持續(xù)反彈 單日漲幅達55元

不只有“美國航母挨炸”,,中國沙漠靶場還驚現(xiàn)“被摧毀的F-22”
“中國第六代戰(zhàn)斗機初見曙光”,美媒:技術(shù)驗證機或已試飛,!

核戰(zhàn)風(fēng)險升級到數(shù)十年來最高點,,國際核態(tài)勢處關(guān)鍵轉(zhuǎn)折點

美軍艦艇,煉就“金剛不壞之身”,?軍事觀察員解讀

歐盟單邊加征關(guān)稅會適得其反,!
多國宣布將自帶空調(diào)參加巴黎奧運會,!

美對臺軍售兩款巡飛彈,“大突破”背后有什么盤算

環(huán)境部西北督察局局長因公殉職

填報志愿需要注意的3個問題 規(guī)避常見誤區(qū)與策略
劉亦菲回復(fù)了林一三朵黃玫瑰,,他難掩激動的回復(fù)了一串玫瑰!

一覺醒來,,這個鋰礦大國發(fā)生閃電政變

女生高考查分見6開頭坐地大哭!

德布勞內(nèi)指示接應(yīng) 隊友無動于衷 隊長冷靜應(yīng)對噓聲風(fēng)波

三代變身四代,,德法主戰(zhàn)坦克新發(fā)展有何啟示,?
看不懂,,但很震撼!土耳其晉級淘汰賽后,,恰爾汗奧盧帶領(lǐng)全隊花式慶祝
美國航母怎么又不夠用了,?

美研制新?;搜埠綄?dǎo)彈,,或激發(fā)新一輪核軍備競賽
相關(guān)新聞
GPT-4欺騙人類高達99%驚人率,!研究指出LLM推理越強欺騙值越高
2024-06-10 14:50:14GPT-4欺騙人類高達99%驚人率!研究指出LLM推理越強欺騙值越高芝大論文證明GPT-4選股準(zhǔn)確率高達60%,分析師要下崗?
2024-05-27 14:18:19芝大論文證明GPT-4選股準(zhǔn)確率高達60%OpenAI抓內(nèi)鬼,奧特曼耍所有人:GPT搜索鴿了,!改升級GPT-4,,揭秘背后真相
最近,OpenAI的舉動令人捉摸不透,,先是預(yù)告將在5月13日舉辦發(fā)布會,,緊接著澄清并非公布GPT-5或傳聞中的GPT搜索引擎,而是關(guān)于ChatGPT和GPT-4的升級
2024-05-12 07:54:36奧特曼耍所有人:GPT搜索鴿了,!改升級GPT-4GPT-4化身黑客搞破壞,,成功率87%!OpenAI要求保密提示詞 AI威脅引熱議
2024-04-21 16:51:41GPT-4化身黑客搞破壞鵝廠造了個AI翻譯公司:專攻網(wǎng)絡(luò)小說,真人和GPT-4看了都說好 AI翻譯新紀(jì)元
2024-05-25 19:42:17鵝廠造了個AI翻譯公司:專攻網(wǎng)絡(luò)小說美國死亡谷國家公園氣溫最高達54℃,,這里的人不僅能適應(yīng),,甚至還能外出跑步
全球正經(jīng)歷著廣泛的高溫天氣,美國同樣身陷其境,,超過三分之一的民眾受到了近期熱浪預(yù)警的影響,。熱浪從加州延伸至南佛羅里達州,大面積區(qū)域持續(xù)遭受高溫炙烤
2024-06-24 16:16:23美國死亡谷國家公園氣溫最高達54℃








