調(diào)查英偉達(dá)是中國GPU自主化一步險棋(3)

摩爾線程:瞄準(zhǔn)AI和圖形計算的先鋒者
摩爾線程是國內(nèi)為數(shù)不多專注于AI和圖形計算領(lǐng)域的全功能GPU企業(yè),,其自研的MUSA(摩爾線程統(tǒng)一系統(tǒng)架構(gòu))讓人眼前一亮,。針對渲染、視頻編解碼、AI等場景,,摩爾線程逐步完善產(chǎn)品布局,成為國內(nèi)AI和圖形計算的重要補(bǔ)充。
國產(chǎn)GPU與英偉達(dá)的性能較量,差距還有多遠(yuǎn),?
雖然國產(chǎn)GPU設(shè)計能力在近年來取得了顯著突破,但與英偉達(dá)這樣的國際巨頭相比,,依然存在差距,。英偉達(dá)的H100、A100系列GPU,,目前仍是全球AI計算領(lǐng)域的*產(chǎn)品,。
國產(chǎn)GPU與英偉達(dá)的差距,體現(xiàn)在多個方面,,例如:英偉達(dá)H100基于5nm Hopper架構(gòu),支持HBM3內(nèi)存,,單卡算力超過1000TFLOPS,,而國產(chǎn)GPU在多項(xiàng)參數(shù)上仍遜色于英偉達(dá);在能耗比和散熱設(shè)計等方面,,國產(chǎn)GPU與英偉達(dá)的產(chǎn)品仍有一定距離,。
另一方面,國產(chǎn)GPU在推理任務(wù)和邊緣計算場景中,,已經(jīng)表現(xiàn)出接近甚至媲美英偉達(dá)的能力,。例如寒武紀(jì)的MLU系列和壁仞的BR100,在推理性能上可以替代部分英偉達(dá)的中高端產(chǎn)品,。此外,,由于美國對華出口管控政策的限制,中國能夠獲得的英偉達(dá)芯片往往是“閹割版”,如A800(A100的降級版),。在這種情況下,,國產(chǎn)GPU的性能差距進(jìn)一步縮小。
性能差距縮小,,信心正在建立,。
盡管與英偉達(dá)的*產(chǎn)品相比,國產(chǎn)GPU在算力和能耗比上仍存在顯著差距,,但這一差距已經(jīng)不再“無法逾越”,。尤其是在推理、邊緣計算和部分垂直場景中,,國產(chǎn)GPU的表現(xiàn)已經(jīng)達(dá)到“可用”的水平,。
更重要的是,國產(chǎn)GPU在自主設(shè)計上的突破,,為未來的進(jìn)一步追趕奠定了堅實(shí)基礎(chǔ),。隨著技術(shù)迭代和市場應(yīng)用的加速,中國GPU設(shè)計能力有望逐步從“追趕”走向“部分超越”,。
02中國半導(dǎo)體制造,,能否支撐高性能GPU生產(chǎn)?

新興市場貨幣遭遇不同程度拋售潮 新一輪貶值潮來襲
燒傷媽媽皮膚康復(fù)狀態(tài)良好,,跟丈夫感謝了所有幫助他們的人

李稻葵解讀公積金異地互通 順應(yīng)人口流動大趨勢

珍愛網(wǎng)被罰170萬重罰還當(dāng)重管 治理需出重拳

韓國9名家人遇難的小狗已被收養(yǎng) 苦等主人引關(guān)注
燒傷媽媽皮膚康復(fù)狀態(tài)良好,,跟丈夫感謝了所有幫助他們的人

韓墜毀客機(jī)兩個黑匣子處理進(jìn)展 事故已致124人死亡

渝湘復(fù)線高速預(yù)計2025年內(nèi)全線通車 部分路段已開放通行

韓國務(wù)安機(jī)場扣押搜查!又叫曬辣椒機(jī)場,? 新航線首航悲劇引發(fā)調(diào)查

專家:美以低估了胡塞武裝的實(shí)力 警告無效凸顯韌性

火箭擒獨(dú)行俠 申京格林圍剿歐文 火箭五人上雙鎖定勝局

韓國空難是天災(zāi)還是人禍 悲劇引發(fā)深思

突發(fā),!韓國執(zhí)政黨總部遭遇炸彈威脅 警方緊急搜查未發(fā)現(xiàn)爆炸物
韓國空難一個錯誤連著一個錯誤 多因素釀成慘劇

小S曬了全家福 姐妹團(tuán)聚歡樂多

俄對基輔中心發(fā)動罕見空襲 瞄準(zhǔn)烏總統(tǒng)府區(qū)域
新興市場貨幣遭遇不同程度拋售潮 新一輪貶值潮來襲

男子跨年夜對近9萬氣球噴射加特林 煙花惹禍被捕
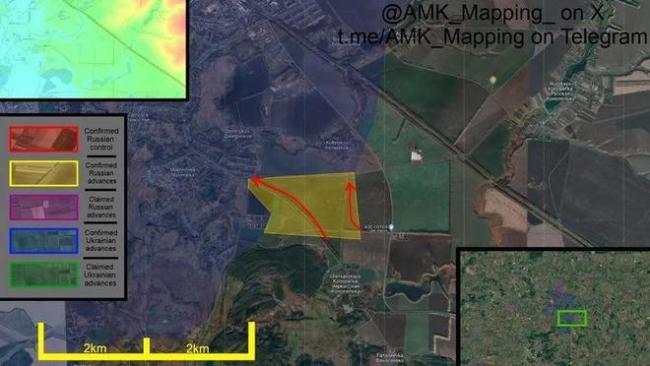
新年第一天,俄軍紅軍城鉗形攻勢雛形初現(xiàn),,烏軍逃離庫拉霍夫發(fā)電廠,!
鹿晗高瀚宇眉釘大片 新年第一炸

專家說很多翻譯碩士水平比不上AI 人工智能沖擊下的職業(yè)挑戰(zhàn)

恭喜國乒!孫穎莎教練走馬上任,,亮相國乒新崗位后,,劉國梁期待!

律師談超市因員工盜竊虧損200萬倒閉 員工集體監(jiān)守自盜

韓國民眾獻(xiàn)花哀悼墜機(jī)遇難者 白菊寄哀思

馬斯克,、扎克伯格,、黃仁勛等科技大佬領(lǐng)銜 全球500富豪身家合計破10萬億美元

霉霉登上央視2024世界新聞年鑒 回顧一年熱點(diǎn)事件

朝鮮新型戰(zhàn)艦疑似曝光 加強(qiáng)軍事現(xiàn)代化進(jìn)程
馬斯克“改名”引爆潑天富貴 神秘交易員兩天狂賺上千萬 幣圈掀起投機(jī)熱潮

韓代總統(tǒng)崔相穆同一天做了兩件事 政壇風(fēng)波再起

特朗普“突襲”,新興市場貨幣貶值潮來襲,!這國匯率跌至歷史新低,!

滑翔傘墜落女大學(xué)生及駕駛員身亡!

春運(yùn)頭兩日北京始發(fā)熱門車次迅速售罄 熱門時段一票難求

媒體:中國軍用5G可連接萬個機(jī)器人 改變現(xiàn)代戰(zhàn)爭模式

衡陽一滑翔傘墜落 游客和教練身亡 兩人遺體已被運(yùn)走
李稻葵解讀公積金異地互通 順應(yīng)人口流動大趨勢
相關(guān)新聞
涉嫌違反中國反壟斷法,英偉達(dá)被立案調(diào)查
2024-12-10 10:47:26涉嫌違反反壟斷法英偉達(dá)被立案調(diào)查英偉達(dá)的“GPU狂熱”才剛開始 全面AI熱潮蓄勢待發(fā)
2024-10-10 14:56:50英偉達(dá)的“GPU狂熱”才剛開始英偉達(dá)市值一夜大漲7540億元 GPU需求持續(xù)強(qiáng)勁
2024-08-13 13:59:06英偉達(dá)市值一夜大漲7540億元花旗分析師發(fā)布報告力挺英偉達(dá) GPU仍將主導(dǎo)市場
2024-12-18 20:59:58花旗分析師發(fā)布報告力挺英偉達(dá)律師稱英偉達(dá)中國業(yè)務(wù)暫不受限 反壟斷調(diào)查進(jìn)行中
2024-12-10 18:23:27律師稱英偉達(dá)中國業(yè)務(wù)暫不受限英偉達(dá)被立案調(diào)查 涉嫌違反反壟斷法
2024-12-09 19:40:30英偉達(dá)被立案調(diào)查








