DeepSeek掀起算力新范式 低成本訓(xùn)練引領(lǐng)變革

上周,,中國DeepSeek的AI工程師團隊推出的DeepSeek R1大模型在美國熱搜上引起轟動,,并在蘋果中國和美國地區(qū)的應(yīng)用商店免費APP下載排行榜上登頂,,超越了ChatGPT,。這標(biāo)志著中國AI的一個重要時刻。DeepSeek團隊展示了他們能在沒有頂級英偉達高性能AI GPU的情況下,,以較低成本和性能普通的AI加速器訓(xùn)練出一流的開源AI大模型,,這意味著未來的AI模型訓(xùn)練和推理可能不再依賴于昂貴的算力。
DeepSeek R1的發(fā)布表明,,AI訓(xùn)練與推理的成本大幅降低,。該模型在不到600萬美元的投資和2048塊H800芯片的支持下,達到了與OpenAI o1相當(dāng)?shù)男阅?,而后者需要高達10億美元的訓(xùn)練成本,。DeepSeek R1每百萬個token的查詢成本僅為0.14美元,相比之下,,OpenAI的成本為7.50美元,。這一成就預(yù)示著低成本的新范式正在形成,AI ASIC的時代即將到來,。
UC伯克利,、港科大和HuggingFace等學(xué)術(shù)機構(gòu)成功復(fù)現(xiàn)了DeepSeek模型,僅用強化學(xué)習(xí)而無需監(jiān)督微調(diào),,就能見證AI模型的“頓悟時刻”,。這種低成本和高效的方法引發(fā)了全球AI領(lǐng)域的關(guān)注。圖靈獎得主Yann Lecun也表示,,這是開源對閉源AI大模型的一次勝利,。DeepSeek的應(yīng)用一度因訪問量激增而短暫崩潰,但問題很快得到解決,。
DeepSeek R1的成功展示了通過極致工程化和集中精度的技術(shù)趨勢,,使得AI ASIC在AI訓(xùn)練端更具競爭力。在推理端,,隨著生成式AI軟件和AI代理的大規(guī)模普及,,推理需求將顯著增加。DeepSeek開創(chuàng)的低成本范式使得AI ASIC在性能和成本上都優(yōu)于傳統(tǒng)的AI GPU,。
DeepSeek R1的推出讓全球科技股投資者對英偉達高性能AI GPU的必要性產(chǎn)生了懷疑,。許多科技巨頭開始考慮自研AI ASIC,,以提高性價比,。盡管英偉達計劃進軍AI ASIC領(lǐng)域,但目前尚未有具體布局,,難以撼動博通和Marvell的主導(dǎo)地位,。
DeepSeek通過高效的訓(xùn)練方法和數(shù)據(jù)壓縮策略,,大幅降低了訓(xùn)練和推理成本。例如,,多層注意力機制,、FP8混合精度訓(xùn)練、DualPipe并行通信等技術(shù),,使得DeepSeek在有限資源下達到甚至超過行業(yè)主流大模型的性能,。這種方法挑戰(zhàn)了傳統(tǒng)的巨額投入模式,顯示出硬件和算法潛力的最大化利用,。
DeepSeek大模型在多個性能指標(biāo)上表現(xiàn)出色,,尤其是在數(shù)學(xué)和編程方面。其在2024年AIME測試中取得了優(yōu)異成績,,接近OpenAI o1的水平,。此外,在評估實際軟件工程問題解決能力的SWE-Bench Verified測試中,,DeepSeek的表現(xiàn)甚至優(yōu)于o1,。
隨著AI訓(xùn)練和推理成本的降低,AI ASIC有望逐漸占據(jù)市場份額,。博通和Marvell等公司正與大型云計算客戶合作開發(fā)定制化的AI芯片,,預(yù)計未來幾年內(nèi)將大規(guī)模部署。摩根士丹利預(yù)測,,AI ASIC市場規(guī)模將在2027年達到300億美元,,年復(fù)合增長率達到34%。盡管如此,,AI ASIC和AI GPU將長期共存,,各自在特定領(lǐng)域發(fā)揮優(yōu)勢。
陳曉陳妍希情史回顧 九年婚姻終落幕

中國導(dǎo)演20萬美元拍出北美短劇第一 刷新票房紀(jì)錄

金價連漲7周后“跳水” 金店再現(xiàn)買金熱
馬斯克坐實AI游戲工作室計劃 讓游戲再次偉大

大V:歐洲和烏克蘭遭受三次沉重打擊 西方暴露三大問題
陳曉陳妍希情史回顧 九年婚姻終落幕

拉夫羅夫抵達沙特 單手揣兜下飛機 談判桌上的博弈

美客機翻覆現(xiàn)場視頻曝光 惡劣天氣或成事故主因

烏方將不承認(rèn)美俄談判達成的協(xié)議 澤連斯基堅決立場
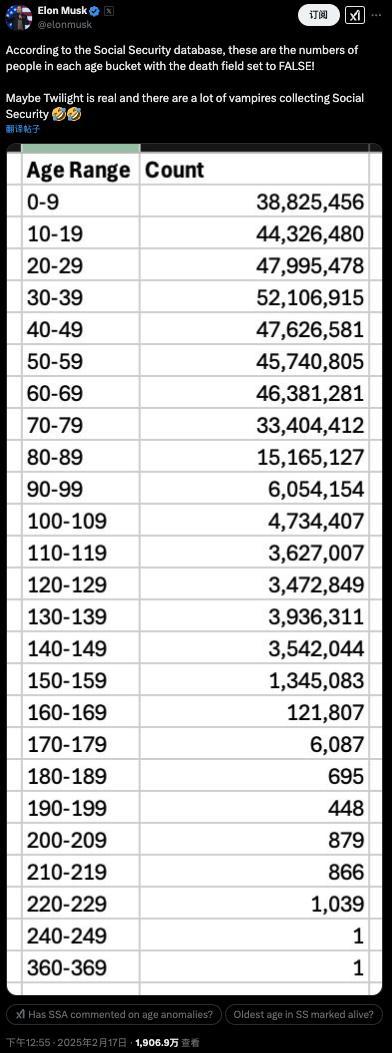
馬斯克查賬“美國社?!?,稱發(fā)現(xiàn)360歲老人?
中國導(dǎo)演20萬美元拍出北美短劇第一 刷新票房紀(jì)錄

澤連斯基將到訪沙特 不參與美俄會談
張睿發(fā)尋物啟事找眼鏡,,張睿沒眼鏡上不了課
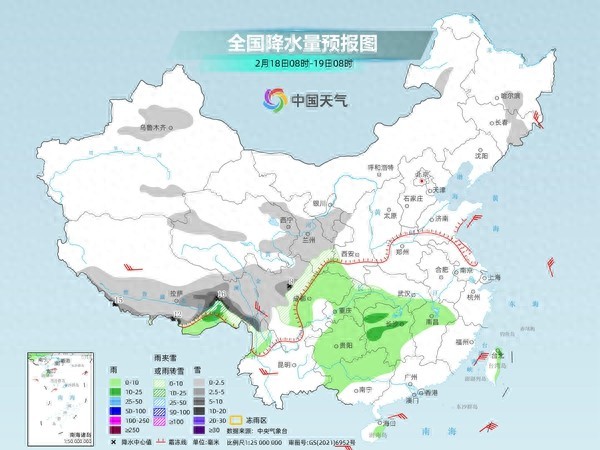
未來三天南方陰雨濕冷感明顯 北方降水增多

黑中介騙取巨額服務(wù)費被公訴 虛假承諾誘騙客戶
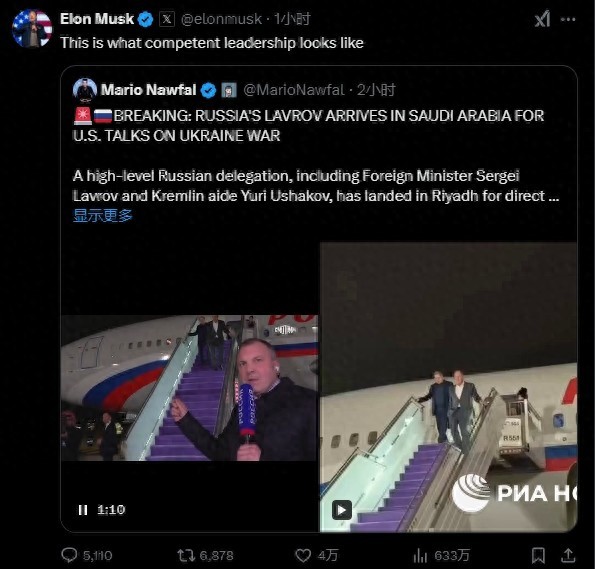
美俄談判今日開始 澤連斯基:不承認(rèn) 烏克蘭缺席引發(fā)爭議
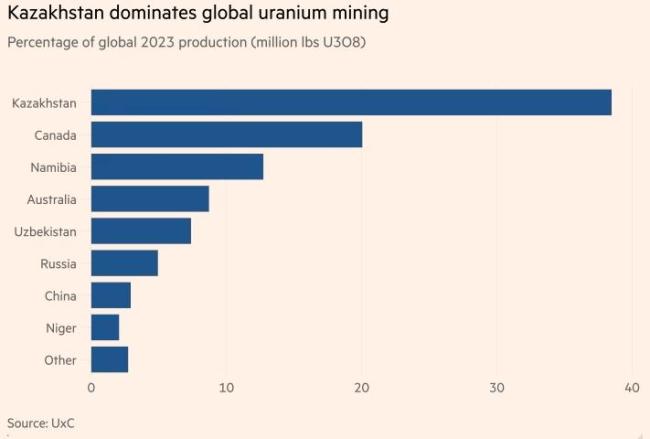
哈薩克斯坦鈾出口重心東移 哈鈾售中俄后致歐美快斷供了
光線傳媒再度巨震 高位人氣股走弱

歐洲的安全,,還是美國的利益?美俄談判前夕,,歐洲被邊緣化引發(fā)擔(dān)憂

美航司客機事故乘客拍下逃生瞬間 加拿大:事發(fā)時風(fēng)力強勁

武漢一培訓(xùn)機構(gòu)請千名學(xué)生看哪吒2 放松身心緩解壓力

美為何提議從中國向烏派遣維和人員 美國的奇葩主意
媒體批特朗普又一次“搶劫”臺灣 美國的真實意圖暴露

美國翻臉后,,歐洲從“夸夸其談的少年”走向獨立成熟要做三件事 應(yīng)對三大危機

伊朗:反對外國勢力干涉敘利亞 支持?jǐn)⑷嗣褡詻Q權(quán)
金價連漲7周后“跳水” 金店再現(xiàn)買金熱

特朗普批波音總統(tǒng)專機還沒造好 項目拖延引不滿

美國新版“空軍一號”再度延期交付 供應(yīng)鏈問題拖累進度

為了增加軍費,英國公共服務(wù)部門被曝準(zhǔn)備削減11%的預(yù)算,,歐洲派兵計劃陷入僵局

哪吒2主創(chuàng)團隊已進入新創(chuàng)作周期 續(xù)寫神話新篇章

三亞招募100名旅游體驗官 提升服務(wù)質(zhì)量與游客滿意度

今日雨水節(jié)氣,,老傳統(tǒng)“吃二樣,做二事,,忌二事” 千年習(xí)俗的智慧

私家車占人行道家長擔(dān)憂孩子走車道 社區(qū)回應(yīng):將安裝U型桿或石球

觀察:2025年的Mini LED電視市場,,怎么打? 三大競爭焦點浮現(xiàn)

曝王大陸涉嫌逃兵役被捕
相關(guān)新聞
DeepSeek掀算力革命 推動國產(chǎn)AI芯片發(fā)展
2025-02-07 12:10:50DeepSeek掀算力革命全網(wǎng)瘋測的DeepSeek牛在哪 震撼硅谷引領(lǐng)AI新范式
2025-01-30 12:41:05全網(wǎng)瘋測的DeepSeek牛在哪DeepSeek正式登陸蘇州 引領(lǐng)AI算力新熱潮
2025-02-10 10:55:47DeepSeek正式登陸蘇州全球掀DeepSeek復(fù)現(xiàn)狂潮 硅谷巨頭神話崩塌,!
2025-01-26 16:20:37全球掀DeepSeek復(fù)現(xiàn)狂潮DeepSeek沒能讓算力焦慮消失 國產(chǎn)算力迎來利好
2025-02-11 08:24:36DeepSeek沒能讓算力焦慮消失DeepSeek概念透露,,誰是算力之王? AI算力競爭加劇
2025-02-16 15:37:02DeepSeek概念透露








