業(yè)內(nèi):DeepSeek引發(fā)AI芯片需求暴增 性能遠超GPU

近日,,《財富》雜志官網(wǎng)報道,Cerebras Systems宣布其晶圓級AI芯片在執(zhí)行700億個參數(shù)的DeepSeek-R1中型模型時,,速度比當(dāng)前最快的GPU快57倍,。Cerebras Systems的CEO Andrew Feldman表示,企業(yè)客戶對DeepSeek最新推出的R1推理模型表現(xiàn)出極大的興趣,,在該模型發(fā)布十天后,,公司迎來了需求激增。
WSE-3芯片采用一整張12英寸晶圓制作,,基于臺積電5nm制程,擁有4萬億個晶體管,、90萬個AI核心和44GB片上SRAM,,內(nèi)存帶寬為21PB/s,結(jié)構(gòu)帶寬高達214PB/s,。這使得WSE-3具有125 FP16 PetaFLOPS的峰值性能,,相比上一代WSE-2提升了1倍。
DeepSeek-R1推理模型以較低的訓(xùn)練成本實現(xiàn)了與OpenAI等競爭對手最先進的推理模型相當(dāng)?shù)男阅?,并且該模型已開源,,全球科技廠商可以利用它快速構(gòu)建自己的AI應(yīng)用。相關(guān)AI芯片廠商也能針對該模型進行適配和優(yōu)化,,充分利用AI芯片的性能,。Andrew Feldman在現(xiàn)場演示中展示了Cerebras的AI服務(wù)器執(zhí)行DeepSeek-R1的速度,用Python語言編寫國際象棋游戲僅需1.5秒,,而OpenAI的o1-mini模型則需要22秒才能完成相同任務(wù),。不過,由于OpenAI模型是封閉系統(tǒng),無法直接在Cerebras硬件上測試,,因此難以完全對比,。
盡管如此,F(xiàn)eldman強調(diào)在數(shù)學(xué)和程序任務(wù)方面,,DeepSeek-R1的表現(xiàn)優(yōu)于OpenAI-o1,,用戶能更快獲得精確答案。然而,,由于R1由中國的大模型技術(shù)廠商DeepSeek開發(fā),,歐美各國基于政治因素以隱私安全等問題發(fā)難。美國國會已著手立法,,擬全面禁止來自中國的先進AI模型,。美國國防部、國會,、海軍,、NASA以及德克薩斯州已相繼禁止在政府官方設(shè)備上使用DeepSeek模型。
Feldman建議選擇美國企業(yè)托管的大型語言模型,,例如Cerebras,、Perplexity等。他承認DeepSeek確實存在一些潛在風(fēng)險,,但只要用戶保持基本判斷力,,謹慎使用即可。

就在3月5日16時7分,!驚蟄節(jié)氣來了 春意萌動萬物蘇

佩里西奇:我們必須處于最高水平 團結(jié)奮戰(zhàn)求勝

前日本女足國腳永里優(yōu)季退役 23年輝煌生涯告終

反馬斯克浪潮席卷全美:政府效率部引爆社會裂痕

蜜雪冰城全球門店數(shù)超過麥當(dāng)勞 中國快餐品牌崛起

英法支持烏克蘭能否替代美國援助 歐洲奪回和談主導(dǎo)權(quán)

東契奇為歐文祈禱 傷病牽動人心
就在3月5日16時7分,!驚蟄節(jié)氣來了 春意萌動萬物蘇
佩里西奇:我們必須處于最高水平 團結(jié)奮戰(zhàn)求勝

《北上》觀眾口碑出爐 收視率亮眼引發(fā)熱議

加元墨西哥比索跌至一個月新低 關(guān)稅風(fēng)暴沖擊匯市
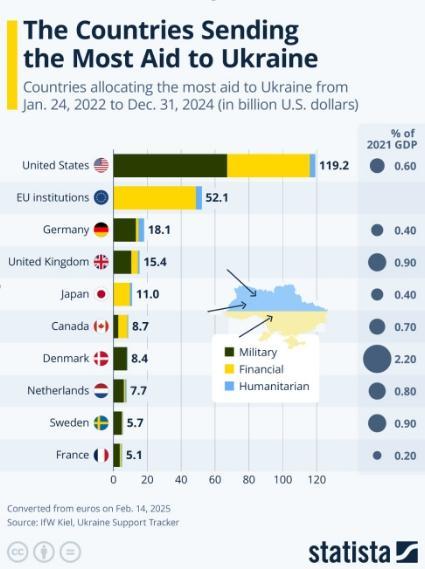
美斷供若歐洲砸錢 烏能堅持下去嗎
臺學(xué)者:解放軍實彈演習(xí)越來越近

珠海新規(guī)施行最高罰款10萬 嚴(yán)打電動自行車非法改裝
嚴(yán)浩翔:祝亞軒繼續(xù)保持對世界的好奇 生日快樂呀!

深圳連發(fā)四份重磅文件 布局AI與機器人產(chǎn)業(yè)

檀健次:唐奇是“深情的渣男” 演繹百變戀愛挑戰(zhàn)

誰來承擔(dān)烏克蘭安全保障 美烏礦產(chǎn)協(xié)議引爭議

專家:烏克蘭最大優(yōu)勢是頑強 堅韌面對挑戰(zhàn)
美政府被曝已暫停向烏克蘭輸送武器 援助凍結(jié)引發(fā)擔(dān)憂

菲律賓一架FA50戰(zhàn)機夜間失聯(lián) 搜救行動進行中

濟南將發(fā)放娘家人暖新包 關(guān)愛“三新”女性

庫爾德工人黨會對土耳其政府服軟嗎 厄賈蘭呼吁解散組織

俄稱結(jié)束沖突是一個艱難的過程 俄方揭西方陣營裂痕

1元發(fā)卡巴黎世家賣2700 品牌爭議再升級

從小鮮肉,,到苦大仇深的小老頭,,澤連斯基是這三年里老得最快的人

祖沖之三號再次打破紀(jì)錄 超導(dǎo)量子計算新突破
前日本女足國腳永里優(yōu)季退役 23年輝煌生涯告終

加拿大將只能靠烏克蘭難民抵御美國擴張

遼寧鐵人隊“最豪華”陣容出爐 前場升級“四大天王”

美“援烏資金”至少70%被留美國

青海公路局應(yīng)對全省降雪天氣 全力除冰雪保暢通

車壓積雪濺路人一身泥交警出手了 自私行為惹眾怒

姚勁波:治理“提燈定損” 保護租客權(quán)益

英首相辦公室:對加沙援助不能受阻 呼吁持續(xù)停火
相關(guān)新聞
業(yè)內(nèi)稱A股仍面臨嚴(yán)峻考驗 ,!
2025-01-06 15:42:45業(yè)內(nèi)稱A股仍面臨嚴(yán)峻考驗業(yè)內(nèi)人士稱黃金適合長期持有
2025-02-20 14:48:49業(yè)內(nèi)人士稱黃金適合長期持有業(yè)內(nèi):取消公攤計價模式是大勢所趨
2024-12-16 10:09:22取消公攤計價模式是大勢所趨業(yè)內(nèi)稱2025年金價仍存上行空間
2025-01-07 16:11:45業(yè)內(nèi)稱2025年金價仍存上行空間業(yè)內(nèi):一二線城市樓市小陽春可期
2025-02-20 09:46:47業(yè)內(nèi)稱一二線城市樓市小陽春可期業(yè)內(nèi):市場進入“慢?!毙星?穩(wěn)中求進
2024-11-16 11:28:50業(yè)內(nèi):市場進入“慢?!毙星?/span>








