DeepSeek婉拒所有采訪專注研發(fā) 引發(fā)OpenAI緊急應(yīng)對(4)

DeepSeek的多Token預(yù)測技術(shù)和混合專家模型架構(gòu)顯著提高了訓(xùn)練和推理效率。這些創(chuàng)新引起了西方實驗室的關(guān)注,。RL在R1中的應(yīng)用也起到了重要作用,,使其在格式化和安全性方面表現(xiàn)出色。通過合成數(shù)據(jù)集微調(diào),,R1的推理能力得以自然涌現(xiàn),。
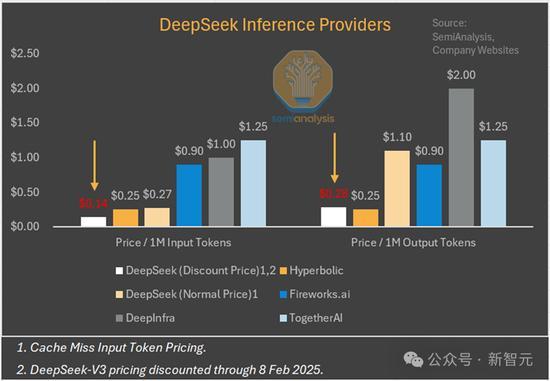
MLA技術(shù)顯著降低了DeepSeek模型的推理成本,減少了每次查詢所需的KV緩存量,,從而降低運(yùn)營成本,。由于H20芯片的高內(nèi)存帶寬和容量,DeepSeek在推理工作負(fù)載方面獲得了更多效率提升,。
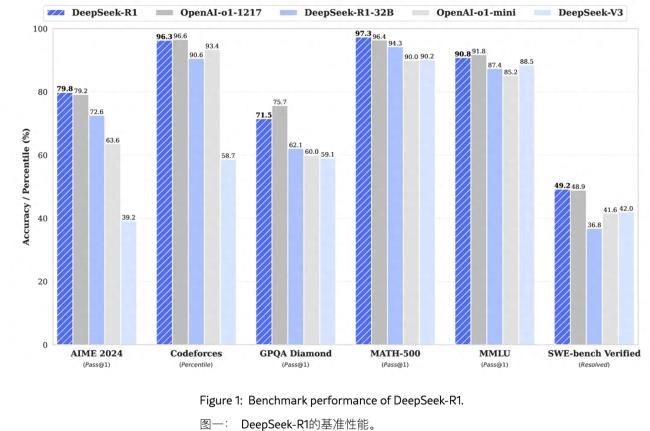
R1并未真正動搖o1的技術(shù)優(yōu)勢,,而是以更低的成本實現(xiàn)了相似的性能。這種現(xiàn)象符合市場邏輯,,類似于半導(dǎo)體制造業(yè)的發(fā)展模式,。率先突破新能力層次的公司將獲得顯著的價格溢價,而追趕者只能獲得適度利潤,。DeepSeek通過零利潤率策略打破了OpenAI的高利潤率格局,,但這是否可持續(xù)仍存疑。未來,,計算資源的集中度將變得更加重要,。
(責(zé)任編輯:盧其龍 CN070)
關(guān)閉

今日正月初八,建議中老年人:4件大事記得做,,新年順利平安
今日正月初八,建議中老年人,4件大事記得做2025-02-05 15:07:37

今年你有開工紅包嗎 金融圈開工福利大揭秘
今年你有開工紅包嗎2025-02-05 15:07:06

東契奇持湖人77號球衣亮相 三方交易震動聯(lián)盟
東契奇持湖人77號球衣亮相2025-02-05 15:05:45

《哪吒2》土撥鼠配音是導(dǎo)演餃子 幕后故事揭秘
哪吒2土撥鼠配音是導(dǎo)演餃子2025-02-05 14:55:31

黃金價格屢創(chuàng)新高 全球避險情緒助推
黃金價格屢創(chuàng)新高2025-02-05 13:50:11
今年你有開工紅包嗎 金融圈開工福利大揭秘
今年你有開工紅包嗎2025-02-05 15:07:06

特朗普稱加沙是地獄 提議美國接管引發(fā)爭議
特朗普稱加沙是地獄2025-02-05 13:32:10

街道辦撬鎖進(jìn)店開燈,?當(dāng)?shù)鼗貞?yīng) 正處理不當(dāng)行為
街道辦撬鎖進(jìn)店開燈,當(dāng)?shù)鼗貞?yīng)2025-02-05 14:59:52

湖人大勝快船 布朗尼3分1助 詹姆斯26+8+9引領(lǐng)勝利
湖人大勝快船布朗尼3分1助2025-02-05 15:05:11

美國逼迫中國讓步?解放軍用行動說話 堅決反制美軍挑釁
美國逼迫中國讓步,解放軍用行動說話2025-02-05 13:32:48

女影迷情緒失控,,對導(dǎo)演“貼臉開大” 影片口碑兩極分化引發(fā)熱議
女影迷情緒失控,對導(dǎo)演貼臉開大2025-02-05 14:51:27
拍下偽劣電纜者需當(dāng)場剝皮取銅 回收金屬避免浪費(fèi)
拍下偽劣電纜者需當(dāng)場剝皮取銅2025-02-05 15:00:03
東契奇持湖人77號球衣亮相 三方交易震動聯(lián)盟
東契奇持湖人77號球衣亮相2025-02-05 15:05:45

China Travel持續(xù)火爆 春節(jié)吸引全球游客
ChinaTravel持續(xù)火爆2025-02-05 13:47:59

美防長將于4月訪問巴拿馬 背景復(fù)雜引發(fā)關(guān)注
美防長將于4月訪問巴拿馬2025-02-05 13:37:34

絕不會手軟,!我國出重手反制打疼美國 五連擊令特朗普改口
絕不會手軟,我國出重手反制打疼美國2025-02-05 13:49:52

商戶閉店被執(zhí)法人員撬鎖開燈 強(qiáng)制亮化引爭議
商戶閉店被執(zhí)法人員撬鎖開燈2025-02-05 14:53:25
今日正月初八,建議中老年人:4件大事記得做,,新年順利平安
今日正月初八,建議中老年人,4件大事記得做2025-02-05 15:07:37

特朗普為以總理 “貼心”推椅子被群嘲 ,,網(wǎng)友調(diào)侃:一眼看出誰是“老板”
特朗普為以總理 “貼心”推椅子被群嘲2025-02-05 13:45:19

內(nèi)塔尼亞胡攜兒子會見馬斯克并合影,白宮合影引發(fā)熱議
內(nèi)塔尼亞胡攜兒子會見馬斯克并合影2025-02-05 14:41:24
關(guān)于DeepSeek需要知道的8件事 國產(chǎn)AI新星崛起
關(guān)于DeepSeek需要知道的8件事2025-02-05 13:43:46

舅舅大片沒拍成 外甥威脅要紅包
舅舅,舅舅大片2025-02-05 14:57:54

鹿晗高瀚宇兄弟大片 “V中文版”新年第一炸,!
鹿晗高瀚宇 2025-02-05 15:03:21
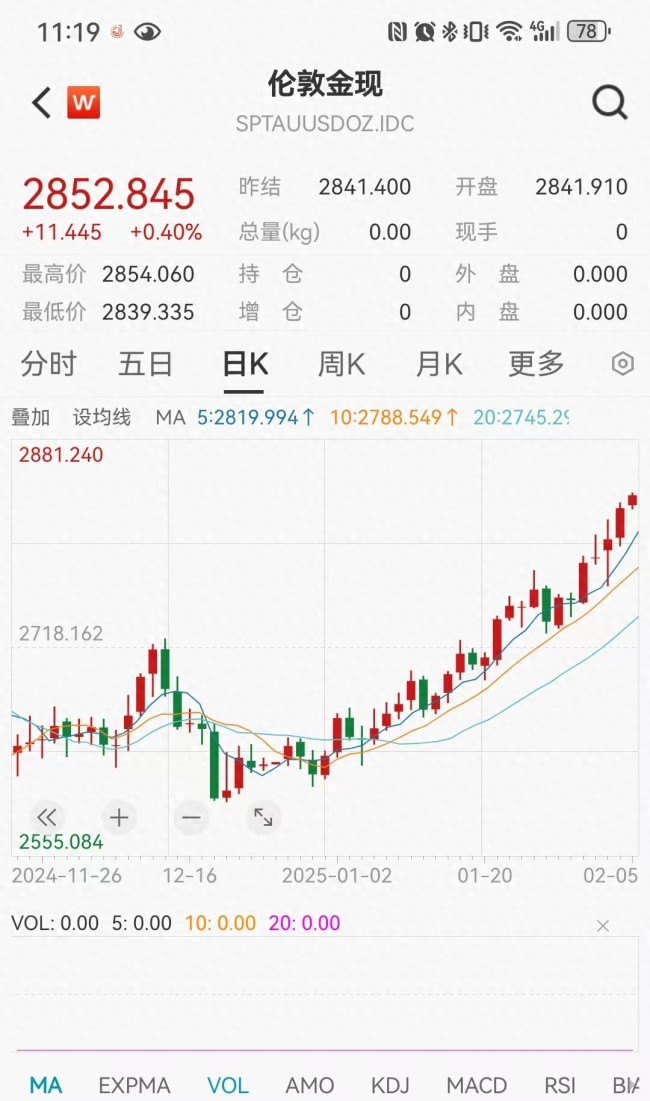
黃金價格狂飆再現(xiàn) 避險情緒推高金價
黃金價格狂飆再現(xiàn)2025-02-05 15:01:43
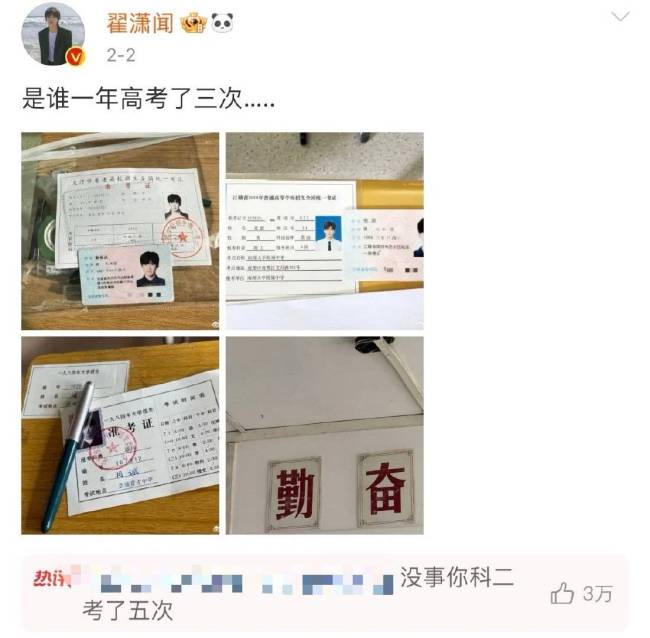
翟瀟聞高考三次科二考五次
翟瀟聞,翟瀟聞高考三次,科二考五次2025-02-05 14:49:46
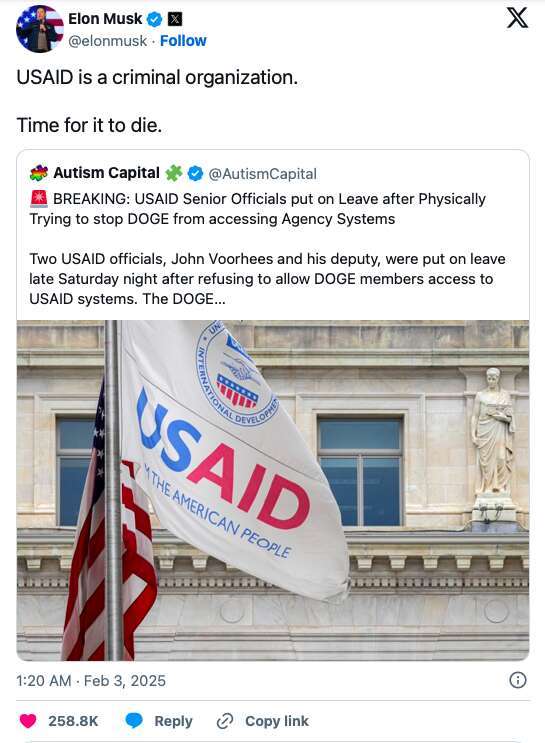
美媒關(guān)注美國國際開發(fā)署被關(guān)閉 馬斯克稱其為犯罪組織
美媒關(guān)注美國國際開發(fā)署被關(guān)閉2025-02-05 14:55:58

特朗普下令設(shè)立美國主權(quán)基金,,但資金從何而來還不明確
特朗普下令設(shè)立美國主權(quán)基金,但資金從何而來還不明確2025-02-05 13:47:32

美國洛杉磯山火狂燒近一個月 終于完全受控制 歷史性災(zāi)難告一段落
美國洛杉磯山火狂燒近一個月終于完全受控制2025-02-05 13:45:40

特朗普100天結(jié)束俄烏沖突計劃可行嗎 美俄討論引發(fā)關(guān)注
特朗普100天結(jié)束俄烏沖突計劃可行嗎2025-02-05 13:43:24

成都春節(jié)共接待游客近2000萬人次 文旅市場熱度不減
成都春節(jié)共接待游客近2000萬人次2025-02-05 14:47:30

專家:菲方圖謀勢必?zé)o法得逞
專家:菲方圖謀勢必?zé)o法得逞2025-02-05 14:43:07

特朗普為以總理 “貼心”推椅子被群嘲 諾獎夢再引爭議
特朗普為以總理貼心推椅子被群嘲2025-02-05 14:23:06

中資一夜撤離,,5000億項目擱淺,!馬科斯急求助美國 南海局勢驟然升溫
中資一夜撤離,5000億項目擱淺,馬科斯急求助美國2025-02-05 13:30:33
特朗普簽署行政令 責(zé)成美財政部、商務(wù)部創(chuàng)立主權(quán)財富基金 兌現(xiàn)競選構(gòu)想
特朗普簽署行政令責(zé)成美財政部,商務(wù)部創(chuàng)立主權(quán)財富基金2025-02-05 13:32:26

日本北海道一個市降雪1.2米 創(chuàng)歷史新高引發(fā)多地停課交通中斷
日本北海道一個市降雪1,2米2025-02-05 15:00:42
相關(guān)新聞
王大雷慘敗后婉拒采訪 心態(tài)崩潰拒絕發(fā)聲
2024-09-09 09:18:05王大雷慘敗后婉拒采訪OpenAI CEO:沒起訴DeepSeek的打算 繼續(xù)專注產(chǎn)品創(chuàng)新
2025-02-05 09:22:44沒起訴DeepSeek的打算李行亮團(tuán)隊稱不方便回應(yīng) 婉拒媒體采訪
2024-12-03 08:16:05李行亮團(tuán)隊稱不方便回應(yīng)李行亮團(tuán)隊稱現(xiàn)在不方便回應(yīng) 婉拒媒體采訪
2024-12-03 09:48:01李行亮團(tuán)隊稱現(xiàn)在不方便回應(yīng)王楚欽賽后采訪說:拋除雜念了,,專注比賽找回狀態(tài)
2024-11-24 19:43:03王楚欽賽后采訪說:拋除雜念了DeepSeek向360及所有中國科技公司發(fā)出倡議?系假消息 虛假倡議書流傳
1月30日,,有消息稱面臨美科技霸凌,,DeepSeek向360及所有中國科技公司發(fā)出倡議,攜手強(qiáng)化技術(shù)合作,。相關(guān)人土對新浪科技稱,此倡議書為假
2025-02-01 09:03:53系假消息








