DeepSeek-R2曝5月前上線 AI計算迎來新突破

DeepSeek-R2曝5月前上線,。第三天,DeepSeek發(fā)布了DeepGEMM,。這是一個支持稠密和MoE模型的FP8 GEMM計算庫,可為V3/R1的訓(xùn)練和推理提供強大支持,。僅用300行代碼,,這個開源庫就能超越專家精心調(diào)優(yōu)的矩陣計算內(nèi)核,為AI訓(xùn)練和推理帶來顯著性能提升,。
DeepGEMM庫具有以下特點:在Hopper GPU上實現(xiàn)高達(dá)1350+ FP8 TFLOPS的算力,;極輕量級依賴,代碼清晰易懂,;完全即時編譯,,即用即跑;核心邏輯僅約300行代碼,,卻在大多數(shù)矩陣規(guī)模下超越專家級優(yōu)化內(nèi)核,;同時支持密集布局和兩種MoE布局。開發(fā)者驚嘆于其簡潔高效的設(shè)計,,認(rèn)為這可能是GPU運算技術(shù)的重大突破,。
DeepGEMM改變了使用FP8 GEMM庫的方式,簡單,、快速,、開源,,代表著AI計算的未來。在即將發(fā)布的DeepSeek-R2中,,將實現(xiàn)更好的編碼,,并支持多種語言進行推理。業(yè)內(nèi)人士預(yù)測,,這將是AI行業(yè)的一個關(guān)鍵時刻,。目前,DeepSeek已經(jīng)在創(chuàng)建高成本效益模型方面取得成功,,打破了該領(lǐng)域的壟斷局面,。DeepGEMM發(fā)布兩天內(nèi),前兩個項目FlashMLA和DeepEP分別獲得了近10k和5k星標(biāo),。
DeepGEMM專為清晰高效的FP8通用矩陣乘法設(shè)計,,采用了DeepSeek-V3中提出的細(xì)粒度縮放技術(shù)。它支持常規(guī)矩陣乘法和混合專家模型分組矩陣乘法,。DeepGEMM使用CUDA編寫,,通過輕量級即時編譯模塊在運行時編譯所有內(nèi)核。目前僅支持NVIDIA Hopper張量核,,為了解決FP8張量核在累加計算時的精度問題,,采用了基于CUDA核心的兩級累加技術(shù)。盡管借鑒了CUTLASS和CuTe的一些概念,,但避免了過度依賴它們的模板或代數(shù)系統(tǒng),,追求設(shè)計簡潔,包含一個核心內(nèi)核函數(shù),,代碼量僅約300行,。盡管采用輕量級設(shè)計,DeepGEMM在處理各種矩陣形狀時的性能都能夠達(dá)到甚至超越經(jīng)專家調(diào)優(yōu)的庫,。
研究人員在配備NVCC 12.8的H800上測試了DeepSeek-V3/R1推理過程中可能使用的所有矩陣形狀(包括預(yù)填充和解碼階段),,所有性能提升指標(biāo)均與基于CUTLASS 3.6內(nèi)部精心優(yōu)化的實現(xiàn)進行對比計算得出。盡管某些矩陣形狀下的表現(xiàn)還不夠理想,,但可以提交優(yōu)化相關(guān)的拉取請求,。
安裝和測試指南如下:首先通過命令克隆倉庫及其子模塊,然后創(chuàng)建第三方庫(CUTLASS和CuTe)的符號鏈接以便開發(fā),。接著測試JIT編譯功能,最后測試所有GEMM實現(xiàn),。具體命令包括: ``` git clone --recursive gitgithub.com:deepseek-ai/DeepGEMM.git python setup.py develop python tests/test_jit.py python tests/test_core.py ```
接下來,,在Python項目中導(dǎo)入deep_gemm即可開始使用,。DeepGEMM中的內(nèi)核采用線程束專用化技術(shù),,實現(xiàn)了數(shù)據(jù)移動,、張量核心MMA指令和CUDA核心提升操作的重疊執(zhí)行。利用TMA硬件特性實現(xiàn)更快速的異步數(shù)據(jù)移動,。此外,,采用完全即時編譯設(shè)計,無需在安裝時編譯,,所有內(nèi)核在運行時通過輕量級JIT實現(xiàn)進行編譯,,有效節(jié)省寄存器空間,使編譯器能夠進行更多優(yōu)化,。對于某些形狀,,采用2的冪次對齊的塊大小可能導(dǎo)致SM利用率不足,團隊為此提供了非對齊塊大小的支持,,結(jié)合細(xì)粒度縮放技術(shù),,帶來了顯著的性能提升。
求職者找工作變貸款買課 培訓(xùn)陷阱頻現(xiàn)

千萬尋子當(dāng)事人謝浩男考慮讀博 父子團圓共慶未來

水煮雞蛋營養(yǎng)吸收率最高 每日一蛋助健康
被家暴16次案當(dāng)事人稱遭網(wǎng)暴 網(wǎng)絡(luò)暴力再添傷痕

為什么有人搶著進福耀科技大學(xué) 個性化培養(yǎng)方案吸引目光

女子網(wǎng)購注射器打水光針 臉上長出硬疙瘩 自行注射隱患大

名牌衛(wèi)生巾紙尿褲被翻新二次銷售 黑幕曝光引發(fā)關(guān)注

梅德韋杰夫:北約“維和部隊”進駐烏克蘭意味著與俄開戰(zhàn)

為何說烏克蘭恨死了馬斯克,?軍援中斷引發(fā)前線不滿
求職者找工作變貸款買課 培訓(xùn)陷阱頻現(xiàn)

森林狼128-102輕取爵士 蘭德爾助力連勝
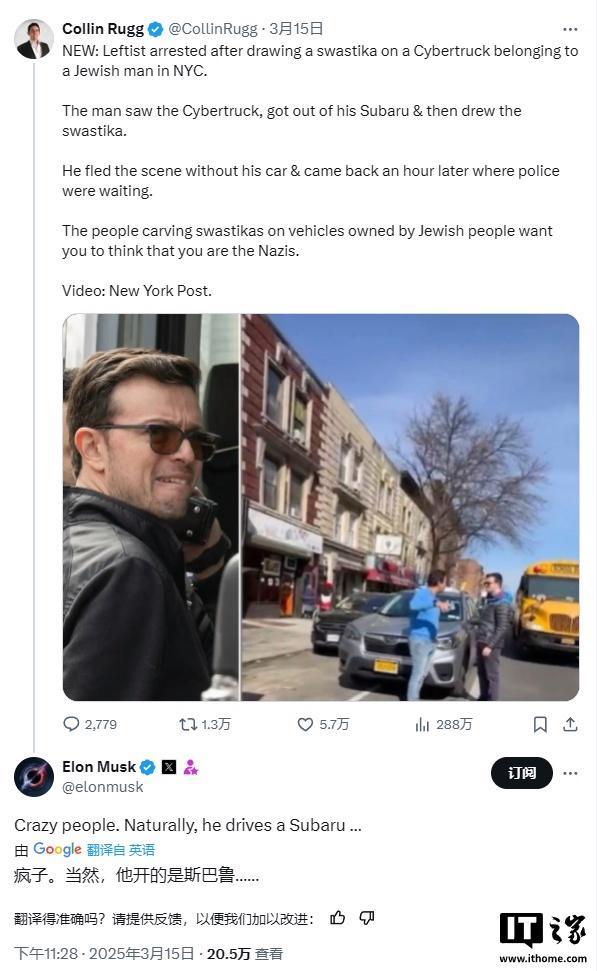
紐約特斯拉Cybertruck被惡意涂鴉 車主對峙肇事者引發(fā)關(guān)注

大V解讀美國將韓國列入“敏感國家” 影響科研合作

3名廳官被查!副廳長的她主動投案 湯筱疏涉嚴(yán)重違法

美軍大舉空襲也門 是“敲山震虎”還是“作繭自縛”,? 向伊朗發(fā)出警告信號

國內(nèi)首個太空采礦機器人來了,!適應(yīng)微重力環(huán)境

臺灣屏東市區(qū)凌晨爆發(fā)槍戰(zhàn) 5人受傷 街頭對峙交火
315晚會曝光借貸寶高利貸!借貸寶App火速下線“打欠條”功能 電子借條平臺被點名

烏克蘭確認(rèn):烏軍撤出,!向俄烏邊境靠攏

第18屆亞洲電影大獎獲獎名單出爐 湯唯劉青云等獲獎
水煮雞蛋營養(yǎng)吸收率最高 每日一蛋助健康

專家:美國背刺韓國是為防止其擁核 韓方措手不及

國產(chǎn)特種駁船亮相影響幾何 引發(fā)國際震動
千萬尋子當(dāng)事人謝浩男考慮讀博 父子團圓共慶未來

俄稱已疏散數(shù)百蘇賈民眾,,烏軍撤離庫爾斯克地區(qū)

美官員稱擊落11架胡塞武裝無人機 否認(rèn)美航母遭襲

食品專家:應(yīng)理性看待食品添加劑 保水蝦仁引爭議
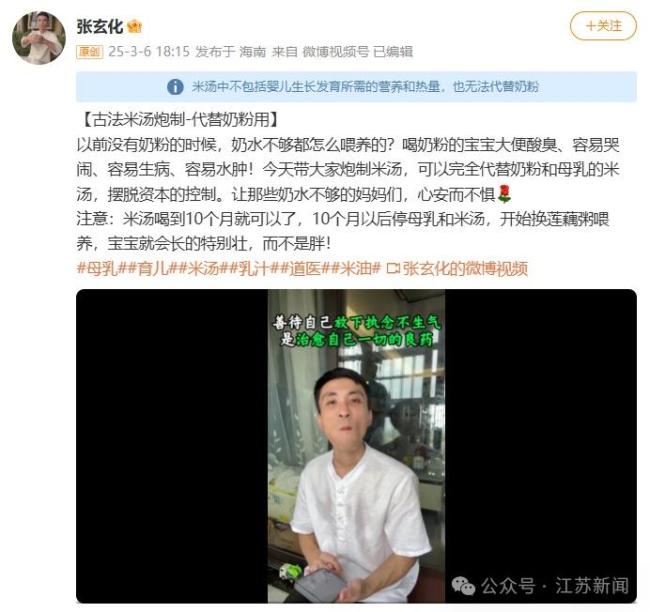
專家:米湯代替母乳奶粉會造成嚴(yán)重營養(yǎng)不良 博主言論被禁言處置

美前高官:美應(yīng)接納中國本來的面貌 中美關(guān)系需新機遇

英法堅持要向烏克蘭派駐部隊 歐洲內(nèi)部意見分歧嚴(yán)重

男子公交車上突然暈倒 司機和乘客齊心救助 生死時速救援

胡塞武裝稱24小時內(nèi)2次襲擊美航母 導(dǎo)彈與無人機齊發(fā)

家里養(yǎng)過豬的外賣小哥避雷烤魚店 食品安全引熱議

啟航!海軍登陸艦編隊跨晝夜實訓(xùn) 錘煉實戰(zhàn)能力

科創(chuàng)“試驗田”成產(chǎn)業(yè)“豐產(chǎn)田” 機器人與AI產(chǎn)業(yè)蓬勃發(fā)展
相關(guān)新聞
以被曝5個月前已策劃對黎通信設(shè)備引爆
2024-09-19 14:38:34以被曝5個月前已策劃對黎通信設(shè)備引爆DeepSeek-R2或下周發(fā)布 官方暫無回應(yīng)
2025-03-11 15:52:16DeepSeek-R2或下周發(fā)布消息稱DeepSeek-R2或下周發(fā)布 官方暫無回應(yīng)
2025-03-11 15:49:40消息稱DeepSeek-R2或下周發(fā)布曝蘋果將在4月前推出iPhoneSE4 搭載自研5G調(diào)制解調(diào)器
馬克?古爾曼對關(guān)于蘋果新款iPhone SE 4和iPad 11將于今年4月隨iOS 18.3和iPadOS 18.3一起發(fā)布的消息進行了回應(yīng)
2025-01-08 08:31:21曝蘋果將在4月前推出iPhoneSE4被曝潛規(guī)則飯店上線提拔套餐 引發(fā)網(wǎng)友低分評價潮
2024-12-12 09:02:57被曝潛規(guī)則飯店上線提拔套餐今日5省份有大到暴雪 大范圍雨水上線 春節(jié)出行需謹(jǐn)慎
今天是春節(jié)假期的第三天,也是大年初二回門日,。預(yù)計從今日起,,中東部地區(qū)將有較大范圍的雨雪過程
2025-01-31 10:07:49今日5省份有大到暴雪大范圍雨水上線