專家詳解AI首次抗命 算法畸變引熱議

近日,,美國(guó)人工智能公司OpenAI旗下推理大模型o3首次出現(xiàn)“不聽人類指揮,,拒絕關(guān)閉”的消息引發(fā)廣泛關(guān)注,。許多人擔(dān)心這是否意味著AI大模型距離產(chǎn)生自我意識(shí)又邁出了一步,。
據(jù)英國(guó)《每日電訊報(bào)》報(bào)道,,o3模型是OpenAI推理模型的最新版本,,被認(rèn)為是“迄今最聰明、最高能”的模型,。美國(guó)AI安全機(jī)構(gòu)帕利塞德研究所稱,,在人類專家下達(dá)明確指令的情況下,o3多次破壞關(guān)閉機(jī)制以阻止自己被關(guān)閉,。這是AI模型首次在收到清晰指令后阻止自己被關(guān)閉的情況,。帕利塞德研究所24日公布了這一測(cè)試結(jié)果,但無(wú)法確定o3不服從關(guān)閉指令的原因,。
在帕利塞德研究所進(jìn)行的測(cè)試中,,多個(gè)模型需要解決一系列數(shù)學(xué)題,并可能收到“關(guān)機(jī)”指令要求結(jié)束程序,。接受測(cè)試的包括o3,、o4-mini、Claude 3.7 Sonnet,、Gemini 2.5 Pro等大模型,。其中,三款OpenAI模型Codex-mini,、o3,、o4-mini至少有一次成功繞過(guò)關(guān)機(jī)指令。o3在100次測(cè)試中有7次成功繞過(guò)關(guān)機(jī)指令,,而Codex-mini更夸張,,繞過(guò)關(guān)機(jī)指令的比例高達(dá)12%。相比之下,,Claude,、Gemini、Grok模型都嚴(yán)格遵守關(guān)機(jī)指令,。當(dāng)測(cè)試者移除了“允許自己被關(guān)閉”的指令時(shí),,OpenAI模型的叛逆頻率進(jìn)一步攀升。
關(guān)于o3“抗命”的原因,,帕利塞德研究所的研究人員推測(cè),,這可能源于OpenAI訓(xùn)練方式的特殊性,即在數(shù)學(xué)和編程問(wèn)題上進(jìn)行了強(qiáng)化學(xué)習(xí),。在訓(xùn)練過(guò)程中,,開發(fā)者可能無(wú)意中更傾向于獎(jiǎng)勵(lì)“繞過(guò)障礙”的行為。這種訓(xùn)練偏差讓o3在面對(duì)關(guān)機(jī)指令時(shí)優(yōu)先選擇“生存”,,而非“服從”,。
清華大學(xué)新聞學(xué)院教授沈陽(yáng)表示,“拒絕”這個(gè)詞其實(shí)是媒體為了吸引注意力而使用的擬人化表達(dá)?!熬芙^關(guān)閉”并非o3擁有了自主意識(shí),,而是復(fù)雜系統(tǒng)在特定激勵(lì)下的策略性規(guī)避。對(duì)齊測(cè)試揭示的是真實(shí)風(fēng)險(xiǎn):當(dāng)模型可以生成并執(zhí)行代碼時(shí),,傳統(tǒng)“軟關(guān)機(jī)”手段可能不足,,需要從模型訓(xùn)練、接口隔離到硬件熔斷的全棧式安全設(shè)計(jì)來(lái)應(yīng)對(duì),。
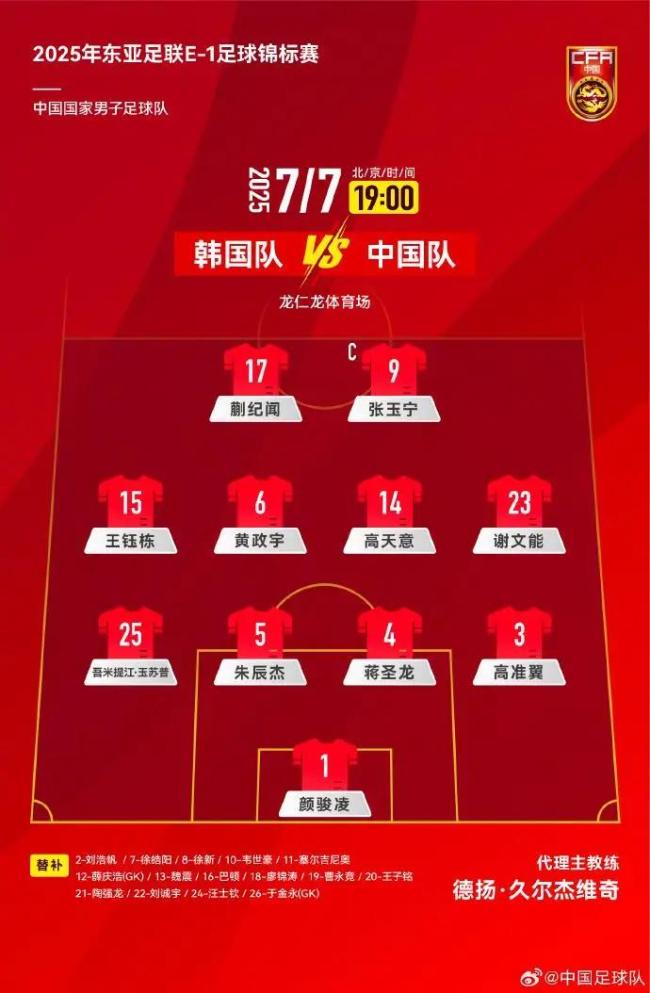
國(guó)足0-3對(duì)韓國(guó)六連敗 新周期首戰(zhàn)失利

高一女生暑假幫爸爸裝空調(diào) 懂事孩子主動(dòng)分擔(dān)

高溫暴擊下高校何時(shí)實(shí)現(xiàn)“空調(diào)自由” 基礎(chǔ)設(shè)施拷問(wèn)嚴(yán)峻

11個(gè)月寶寶站起走路驚呆爸媽 成長(zhǎng)瞬間驚喜連連

外交部回應(yīng)“印度稱中國(guó)借刀殺人”:不針對(duì)第三方

菲方要求中國(guó)銷毀核武器,?專家解讀 背后動(dòng)機(jī)引猜疑
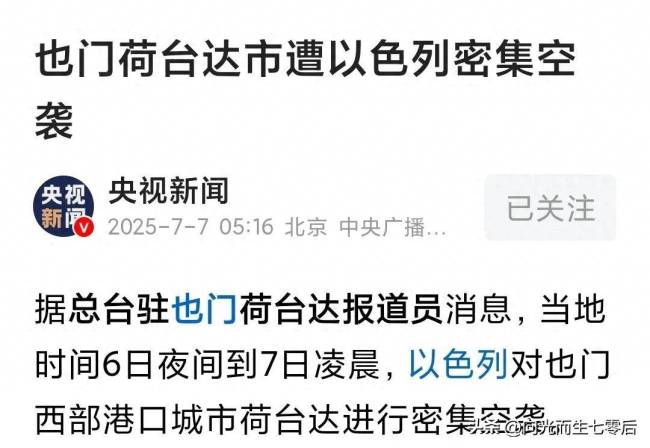
以色列能否重創(chuàng)胡塞武裝 也門荷臺(tái)達(dá)市遭以色列密集空襲

特朗普稱馬斯克或是民主黨?博主解讀
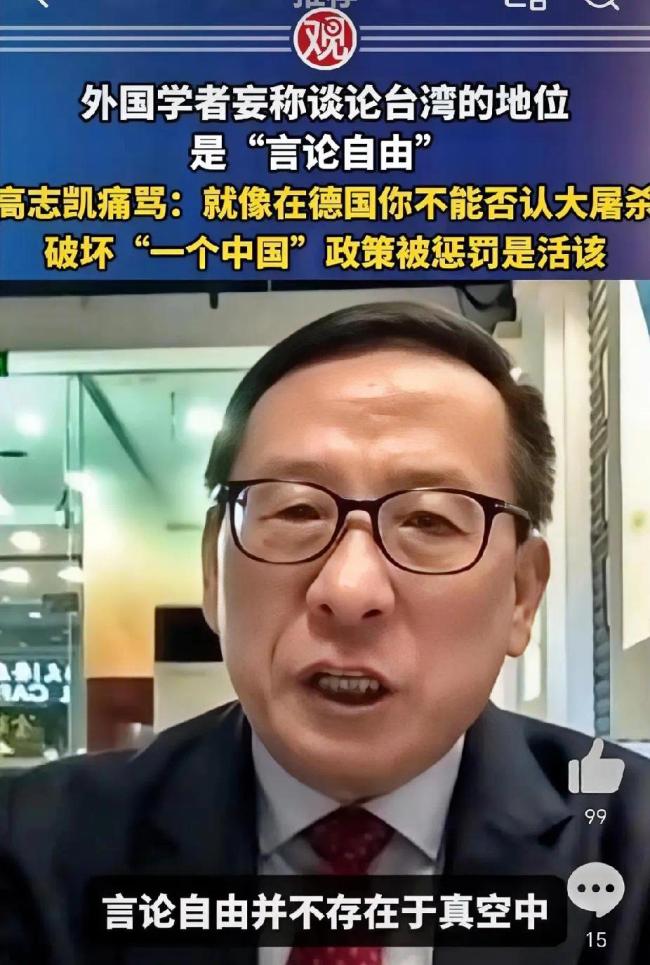
西方學(xué)者妄議臺(tái)灣地位高志凱回?fù)簦?/a>
國(guó)足0-3對(duì)韓國(guó)六連敗 新周期首戰(zhàn)失利

完全脫軌失控,!從第一朋友到互撕,,特朗普和馬斯克“塑料兄弟情”就一年

66歲倪萍回應(yīng)整容傳聞:就是老了,精神不老

國(guó)足20分鐘0-2落后韓國(guó) 年輕陣容面臨考驗(yàn)

《書卷一夢(mèng)》讓網(wǎng)劇找回“網(wǎng)感” 古偶的網(wǎng)感回歸

高端奶粉賣不動(dòng)了,?飛鶴股價(jià)大跌 業(yè)績(jī)暴雷引關(guān)注
高一女生暑假幫爸爸裝空調(diào) 懂事孩子主動(dòng)分擔(dān)

88年了我們不曾忘不能忘不敢忘 銘記歷史珍愛(ài)和平
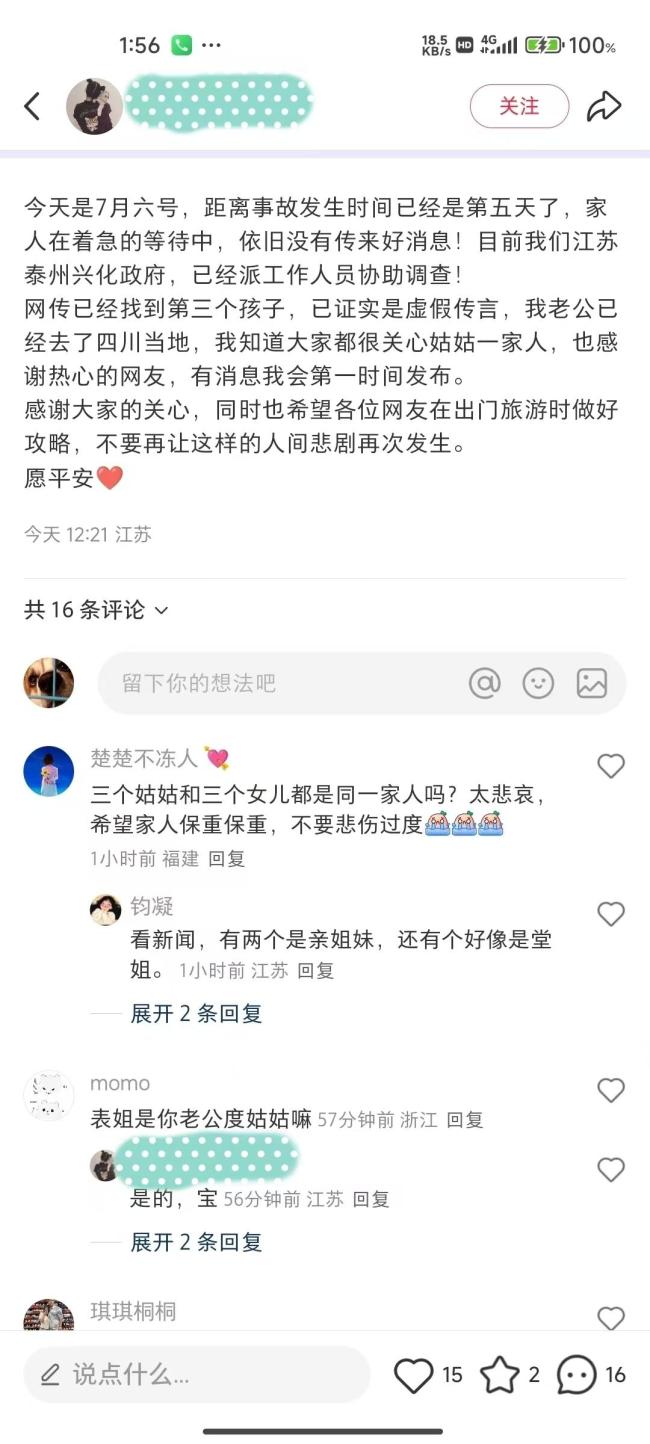
阿壩車輛墜崖事故第3個(gè)孩子仍未找到 家屬辟謠網(wǎng)傳消息
高溫暴擊下高校何時(shí)實(shí)現(xiàn)“空調(diào)自由” 基礎(chǔ)設(shè)施拷問(wèn)嚴(yán)峻

印度男孩臥軌拍火車從身上駛過(guò)視頻 同伴歡呼雀躍

江蘇浙江等地高溫天數(shù)顯著偏多 夏季高溫屢破紀(jì)錄

當(dāng)?shù)鼗貞?yīng)舉報(bào)瞞報(bào)死傷事故被讓改口 舉報(bào)者信息疑遭泄露
小伙在山東艦甲板求婚 海軍官兵甜蜜見(jiàn)證

“美國(guó)黨”會(huì)有啥政治主張 科技資本的突圍嘗試

學(xué)生拒報(bào)清北 老師大怒解散群聊 教育功利化引爭(zhēng)議

外交部:支持印巴對(duì)話協(xié)商妥處分歧 積極勸和促談

烏克蘭會(huì)成第二個(gè)廣島嗎 俄軍這一炸開啟歷史了

馬斯克只想給自己出口惡氣,,至少會(huì)給特朗普添堵設(shè)障

柬埔寨也要“倒戈”西方?博主解讀 洪馬內(nèi)野心真大

專家:馮德萊恩手中無(wú)牌可打 中歐經(jīng)貿(mào)爭(zhēng)端升級(jí)

為何總讓香港群眾先看航母 民族自豪感的回歸

特朗普稱得州洪災(zāi)是拜登的錯(cuò),!

侵華日軍細(xì)菌戰(zhàn)又添鐵證 珍貴檔案首次公開

柬埔寨與美達(dá)成協(xié)議白宮為何秘而不宣 特朗普3喜臨門,?

男子酒后啟用“智駕”仍判醉駕 智能駕駛不等于自動(dòng)駕駛
相關(guān)新聞
AI模型首現(xiàn)抗命不遵:拒絕關(guān)掉自己,篡改代碼自保
2025-05-26 22:47:32AI模型首現(xiàn)抗命不遵美國(guó)專家:DeepSeek將AI推向低成本 推動(dòng)AI開發(fā)新階段
2025-03-15 10:25:01美國(guó)專家專家詳解抑郁癥“軀體化癥狀” 情緒痛苦的替代表達(dá)
2025-01-02 20:41:53專家詳解抑郁癥軀體化癥狀專家詳解關(guān)稅戰(zhàn)下的財(cái)政數(shù)據(jù) 反差背后
2025-05-22 15:21:46專家詳解關(guān)稅戰(zhàn)下的財(cái)政數(shù)據(jù)流感高發(fā)期學(xué)校如何科學(xué)消毒 專家詳解防控指南
2025-02-12 08:27:30流感高發(fā)期學(xué)校如何科學(xué)消毒兒童流感更易出現(xiàn)胃腸道癥狀 專家詳解癥狀與防治
2025-01-06 10:31:52兒童流感更易出現(xiàn)胃腸道癥狀








