大模型集體失智:9.11和9.9哪個大,,幾乎全翻車了

大模型集體失智:9.11和9.9哪個大,,幾乎全翻車了
近期,一個看似簡單的數(shù)學問題挑戰(zhàn)了眾多前沿的人工智能大模型,,引發(fā)了業(yè)界的關(guān)注。問題本身并不復雜:9.11和9.9哪個數(shù)字更大,?然而,,在第一財經(jīng)記者的測試中,即便是先進的AI系統(tǒng)也出現(xiàn)了分歧,。在12款接受測試的大模型中,,只有阿里通義千問、百度文心一言,、Minimax和騰訊元寶給出了正確的答案,,剩余八款模型,包括知名的ChatGPT-4o等,,則在這個基礎數(shù)學問題上栽了跟頭,。
這些出錯的大模型大多陷入了比較小數(shù)點后數(shù)字的誤區(qū),誤以為9.11大于9.9,。即使記者明確指出是在數(shù)學的語境下進行比較,,類似ChatGPT這樣的頂尖大模型也未能避免錯誤。這揭示了長久以來大模型在處理數(shù)學問題上的不足,,反映出它們的設計更偏向于文字處理而非數(shù)字邏輯,。
該現(xiàn)象的起因可追溯至一檔綜藝節(jié)目中的投票率比較,觀眾對13.8%與13.11%的大小產(chǎn)生爭議,,進而引發(fā)了公眾對AI處理此類基本數(shù)學問題能力的好奇和測試,。測試結(jié)果顯示,許多AI在面對這類基礎數(shù)學問題時顯得力不從心,,盡管它們在復雜的語言任務上表現(xiàn)出色,。
探究其背后的原因,專家們指出,,生成式語言模型的本質(zhì)決定了它們更擅長處理基于文本的關(guān)聯(lián)性任務,,而非數(shù)學所需的邏輯推理和精確計算。語言模型通過學習海量文本數(shù)據(jù)來預測下一個詞,,這使得它們在文學創(chuàng)作上能夠展現(xiàn)出接近人類的水平,,但在需要嚴謹邏輯和抽象思維的數(shù)學領域,卻顯得力有未逮,。此外,,數(shù)字處理時的分詞問題也是導致錯誤的一個技術(shù)因素,現(xiàn)有分詞器往往沒有針對數(shù)學計算進行優(yōu)化,,可能導致數(shù)字被錯誤分割,,影響模型的理解,。

卡德羅夫授予普京車臣榮譽公民稱號 時隔13年再訪車臣

媒體人評兩男子捉44只壁虎被刑拘 保護"三有"動物成焦點
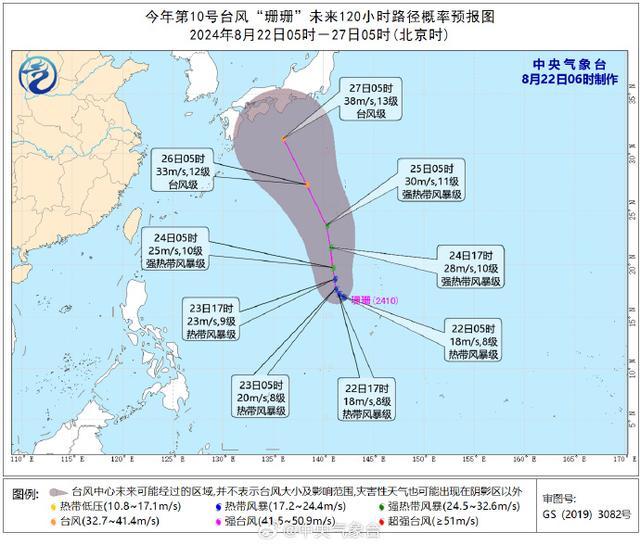
今年第10號臺風“珊珊”生成 未來五天對中國海域無影響

波蘭邊境集結(jié)坦克將與俄開戰(zhàn)?假的 系建軍節(jié)游行活動

日本在小島建導彈靶場,,連美媒都盯上了
媒體人評兩男子捉44只壁虎被刑拘 保護"三有"動物成焦點
今年第10號臺風“珊珊”生成 未來五天對中國海域無影響

《紅樓夢之金玉良緣》票房暴跌 導演斥AI惡意評分

畫面曝光,!“美軍事人員現(xiàn)身庫爾斯克”

美國不斷拱火菲律賓,中方:美無權(quán)介入中菲涉海問題

被虐致死女童母親稱男方重男輕女 求判生父及其女友死刑

王俊凱說別模仿我吃中藥拌面 年輕人的"發(fā)瘋"態(tài)度
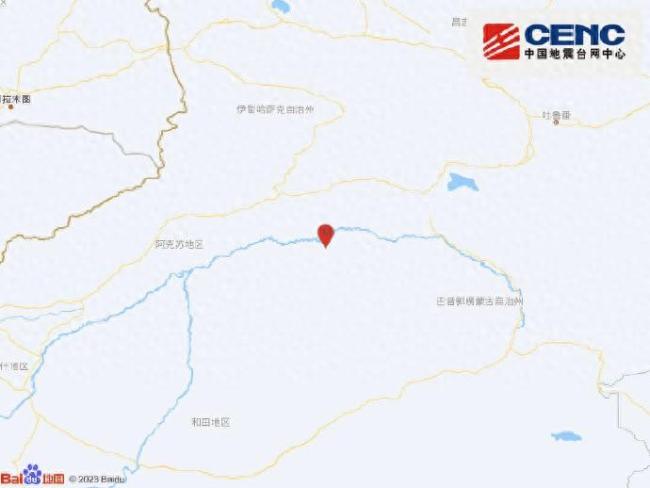
新疆阿克蘇庫車市發(fā)生5.0級地震 震源深度15千米

美國批準對韓出售36架“阿帕奇”直升機

免疫力下降,、增加癌癥風險、損傷耳朵......有這種睡眠習慣的人要注意

杜蘭特談奧運會逆轉(zhuǎn)塞爾維亞 末節(jié)狂飆20分反超

日本民間團體代表:沖繩不需要美軍基地

捷克將利用被凍俄資產(chǎn)的收益為烏克蘭提供彈藥

處暑在中,三九暴雪”今冬雪多嗎,?冷冬預警:農(nóng)諺解析來啦

美媒稱拜登已批準一項高度機密核戰(zhàn)略,,首次將重心轉(zhuǎn)向“中國核威脅”

美方軍事人員被曝參與襲擊俄羅斯庫爾斯克州

德國暫緩軍援烏克蘭,?朔爾茨回應

房東嫌我問題太多不想租給我了 事兒多引租憂

《黑神話:悟空》在臺灣火了 中華文化魅力席卷全球

北京:免疫力下降、增加癌癥風險,、損傷耳朵......有這種睡眠習慣的人要注意

王楚欽說混雙奪金是最開心的瞬間 搭檔孫穎莎功不可沒

俄烏就談判問題激烈交鋒:俄外長稱目前不可能恢復對話,,烏總統(tǒng)稱正在實現(xiàn)戰(zhàn)略目標
卡德羅夫授予普京車臣榮譽公民稱號 時隔13年再訪車臣

機器鷹、機器魚……軍用仿生機器人嶄露頭角

壯膽,?臺軍動用多種導彈進行“精準導彈射擊”演練

以防長:以軍重心將從加沙逐步轉(zhuǎn)向黎以邊界

日本:中國海軍075型兩棲攻擊艦穿越宮古海峽

俄媒:普京2011年以來首次視察俄車臣共和國,,卡德羅夫在機場迎接
都是奔著毀容去的?一晚上全是,!杭州醫(yī)生:我清創(chuàng)清吐了

俄烏在庫爾斯克戰(zhàn)事“白熱化”,,俄烏“決勝”是否在此,?
相關(guān)新聞
大模型測不出9.11和9.9哪個大 AI常識困境暴露
2024-07-17 13:58:59大模型測不出9.11和9.9哪個大AI答不出9.11和9.8誰大 大模型小學數(shù)學集體翻車
2024-07-17 20:40:10AI答不出9.11和9.8誰大北京網(wǎng)友測試教育大模型9.9比9.11大 8大模型犯錯揭示短板
近期,,一個看似簡單的數(shù)學問題挑戰(zhàn)了眾多先進的人工智能大模型,引發(fā)了業(yè)界關(guān)注
2024-07-19 08:05:47北京網(wǎng)友測試教育大模型9.9比9.11大恒大“擔保人”,,果然翻車了,?
恒大“擔保人”,果然翻車了普華永道回應被指審計恒大失?。翰粚?已經(jīng)采取應對措施還記得大明湖畔的夏雨荷嗎,?哦不,還記得之前我寫的罰死那個恒大的“擔保人”嗎,?對,,我說的就是普華永道。
2024-04-16 10:57:14恒大“擔保人”臺灣93歲老人因病失智 一直喊媽媽 親情穿越失智的呼喚
2024-05-24 15:52:58臺灣93歲老人因病失智銷量暴跌,,去年排名第一的手機,又翻車了,?realme困局:叫好不叫座
提及realme手機,,大家的第一印象是什么?是高性價比,,還是引領潮流的設計,?如同近期與一加,、紅米等品牌探討的趨勢一樣,realme發(fā)布新機的速度也圍繞著“高效”二字
2024-06-08 15:25:53銷量暴跌








