學(xué)者談AI“窮盡”知識時人怎么辦 數(shù)據(jù)瓶頸引發(fā)新思考

學(xué)者談AI窮盡知識時人怎么辦,!互聯(lián)網(wǎng)是人類知識的汪洋大海,,但并非無窮無盡。人工智能研究人員幾乎將其耗盡,。過去十年來,,人工智能的進步主要通過擴大神經(jīng)網(wǎng)絡(luò)和增加訓(xùn)練數(shù)據(jù)實現(xiàn)。這種擴展使大語言模型在復(fù)刻會話語言和發(fā)展推理等能力方面取得了顯著成果,。然而,,一些專家認(rèn)為我們已接近擴展的極限,部分原因是計算所需的能源不斷膨脹,,同時也因為用于訓(xùn)練模型的傳統(tǒng)數(shù)據(jù)集正在枯竭,。
今年,一項研究預(yù)測到2028年左右,,用于訓(xùn)練人工智能模型的數(shù)據(jù)將達到公共在線文本的估計總存量,。這意味著人工智能可能在四年內(nèi)耗盡訓(xùn)練數(shù)據(jù)。同時,,數(shù)據(jù)所有者如報紙出版商開始限制其內(nèi)容的使用方式,,進一步收緊了數(shù)據(jù)使用權(quán)。麻省理工學(xué)院的研究員Shayne Longpre表示,,這導(dǎo)致了“數(shù)據(jù)公共資源”規(guī)模的危機,。
盡管專家們認(rèn)為這些限制可能會減緩人工智能系統(tǒng)的快速發(fā)展,但開發(fā)者們正在尋找解決辦法,。例如,,OpenAI和Anthropic等公司已經(jīng)公開承認(rèn)這一問題,并計劃生成新數(shù)據(jù)和尋找非常規(guī)數(shù)據(jù)源,。OpenAI的一位發(fā)言人表示,,他們使用多種來源的數(shù)據(jù),,包括公開數(shù)據(jù)、合作伙伴提供的非公開數(shù)據(jù),、合成數(shù)據(jù)生成和來自人工智能訓(xùn)練者的數(shù)據(jù),。
數(shù)據(jù)緊縮可能會促使人們從大型通用語言模型轉(zhuǎn)向更小、更專業(yè)的模型,。過去十年中,,語言模型的發(fā)展顯示了對數(shù)據(jù)的巨大需求。據(jù)估計,,自2020年以來,,用于訓(xùn)練語言模型的token數(shù)量增長了100倍,從數(shù)千億增加到了數(shù)萬億,。盡管互聯(lián)網(wǎng)上的文本總量巨大,,但高質(zhì)量的內(nèi)容相對較少,且增長速度緩慢,。
與此同時,,內(nèi)容提供商正越來越多地阻止網(wǎng)絡(luò)爬蟲或人工智能公司獲取其數(shù)據(jù)用于訓(xùn)練。研究表明,,在三個主要凈化數(shù)據(jù)集中,,限制爬蟲訪問的token數(shù)量從2023年的不到3%上升到2024年的20%-33%。目前有幾起訴訟正在進行中,,試圖為人工智能訓(xùn)練中使用的數(shù)據(jù)提供商贏得賠償,。如果法院支持內(nèi)容提供者應(yīng)獲得經(jīng)濟補償?shù)挠^點,那么人工智能開發(fā)者和研究人員將更難獲得所需數(shù)據(jù),。

雙色球第2024151期:中出一等獎14注,,籌集公益金1.54億元 獎池累計22.63億

油價今晚調(diào)整!要漲,!要漲,!新年首次上調(diào)來臨
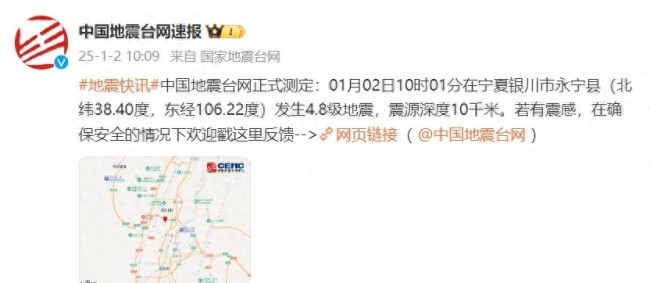
寧夏銀川市永寧縣發(fā)生4.8級地震 震源深度10千米

新年首日以軍仍在襲擊加沙地帶多地
雙色球第2024151期:中出一等獎14注,籌集公益金1.54億元 獎池累計22.63億

媒體人:中日一出好戲即將上演 關(guān)系回暖信號明顯

美國六代機項目緣何不斷延宕

東部戰(zhàn)區(qū)新年MV用了繁體字
油價今晚調(diào)整,!要漲,!要漲!新年首次上調(diào)來臨

長髯翁冬泳40余年曾1個月救起28人 嘉陵江邊的守護者

也門某部落向美以兩國展示武力

專家:普京要的不僅是俄烏?;?/a>

美國監(jiān)管部門提出自動駕駛車輛自愿性監(jiān)督計劃 推動透明度與責(zé)任開發(fā)

烏停止俄氣過境 斯總理表態(tài) 歐盟利益受損

美汽車撞人事件或有4人參與爆炸裝置 多人涉案疑受極端組織影響
第四代住宅,徹底卷飛了 市場熱銷引發(fā)關(guān)注

紐約地鐵進站瞬間乘客被推下鐵軌:監(jiān)控拍下驚悚全程,,受害者幸存

持優(yōu)待證可免費乘坐烏魯木齊地鐵 退役軍人出行更便捷

央視最帥主持人突發(fā)疾病離世,,妻子全程守靈,12歲兒子現(xiàn)場送別,,600多人到場 一代人的回憶消逝

美國多個地標(biāo)跨年遭雷擊

以色列移民人數(shù)翻倍

2025年第一天解放軍對臺攤牌,,民眾黨態(tài)度變了!

徐以若于正紛紛回應(yīng) 于正喊話趙露思:我怎么你了,?
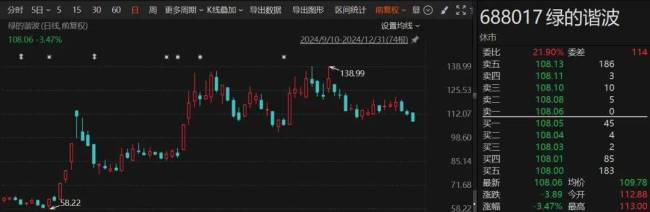
80歲老人豪擲5000萬元,,參與百元股定增 高齡投資者再現(xiàn)A股
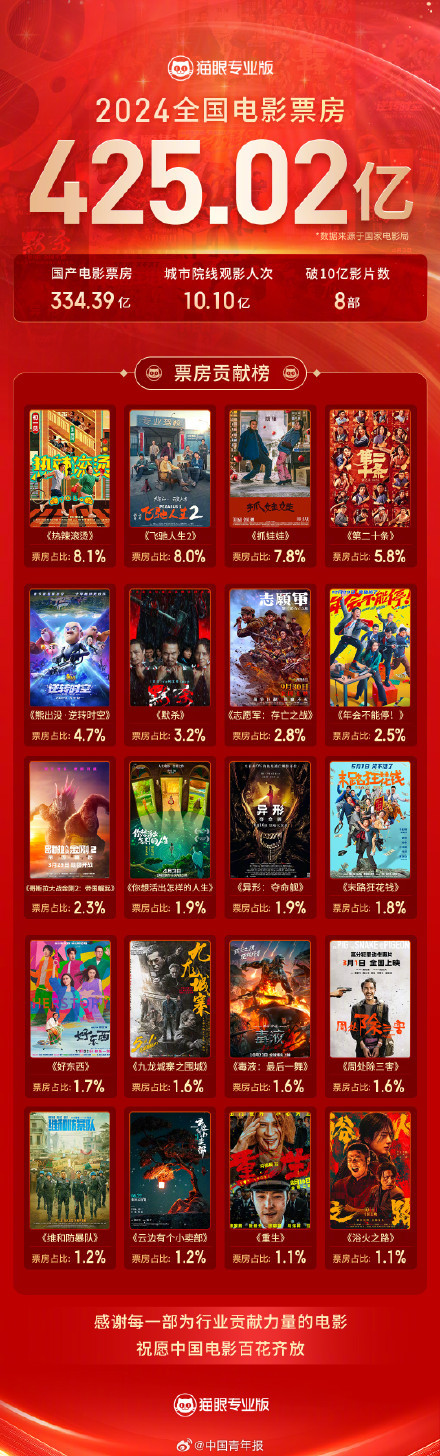
2024年我國電影總票房達425.02億元 國產(chǎn)片占比近八成

著名相聲演員張金銘去世 曲藝界痛失大師

上百名游泳愛好者相約西湖冬泳 寒冬中的熱情挑戰(zhàn)

馬斯克改昵稱帶動一模因幣暴漲超3000% 神秘名字引發(fā)猜想

Angelababy沙漠神女,祈愿新歲盛景,,情寄天地,,心向暖陽

羽絨服漲價背后:薅波司登“羊毛”的黃牛們,賺翻了,? 高價策略引發(fā)爭議

創(chuàng)業(yè)板指跌逾1% 港股高鑫零售跌幅擴大至35% 市場情緒低迷

網(wǎng)友說周三放假很科學(xué) 幸福感大幅提升
寧夏銀川市永寧縣發(fā)生4.8級地震 震源深度10千米
特朗普馬斯克一起跨年 美好時光在前方
樊振東發(fā)文迎接2025年:誰說污泥滿身的不算英雄
相關(guān)新聞
學(xué)者談美國的“選舉人團”
2024-06-28 15:00:55學(xué)者談美國的“選舉人團”臺灣學(xué)者談黑悟空風(fēng)靡全球:驕傲,!
2024-08-23 12:13:11臺灣學(xué)者談黑悟空風(fēng)靡全球:驕傲學(xué)者黨成孝談《哈耶克論哈耶克》
2024-06-25 15:11:58學(xué)者黨成孝談《哈耶克論哈耶克》格魯吉亞學(xué)者談中國免簽 促進文化交流之旅
12月5日,全球化智庫(CCG)主辦,、當(dāng)代中國與世界研究院支持的2024年“國際青年領(lǐng)袖對話”年度論壇在北京舉行
2024-12-06 17:36:55格魯吉亞學(xué)者談中國免簽學(xué)者:中國AI專利量超美國,,領(lǐng)跑全球創(chuàng)新競賽
2024-07-07 08:20:55學(xué)者:中國AI專利量超美國甄子丹談AI對電影的影響 機遇與挑戰(zhàn)并存
2024-12-30 08:03:47甄子丹談AI對電影的影響