DeepSeek為何在美國引起巨大關(guān)注 打破大模型壟斷

這幾天,,中國人工智能初創(chuàng)公司DeepSeek在美區(qū)下載榜上超越了ChatGPT,,還引發(fā)多個(gè)美國科技股股價(jià)暴跌,。美國總統(tǒng)特朗普稱DeepSeek的出現(xiàn)“給美國相關(guān)產(chǎn)業(yè)敲響了警鐘”,。
DeepSeek用較少的資金實(shí)現(xiàn)了與世界頂尖大模型如GPT-4相媲美的性能,。OpenAI訓(xùn)練ChatGPT-4的成本高達(dá)7800萬美元甚至可能達(dá)到1億美元,,而DeepSeek的大模型訓(xùn)練成本不到600萬美元,,僅為同性能模型的5%到10%,。新模型訓(xùn)練方法大幅降低了大模型行業(yè)的入局門檻,,使得大規(guī)模預(yù)訓(xùn)練不再是科技巨頭的專利,。此外,在模型推理層面,,DeepSeek推出的DeepSeek-R1價(jià)格為2.2美元/百萬詞元,,而同性能的OpenAI-o1價(jià)格為60美元/百萬詞元,前者僅為后者的三十分之一,。這種低成本顯著改善了大模型的應(yīng)用成本,,對科研、企業(yè)等智力密集型產(chǎn)業(yè)具有重大價(jià)值,。因此,,無論是從基礎(chǔ)研究角度還是商業(yè)層面上看,DeepSeek對美國一些大模型公司的既有模式構(gòu)成了沖擊,。
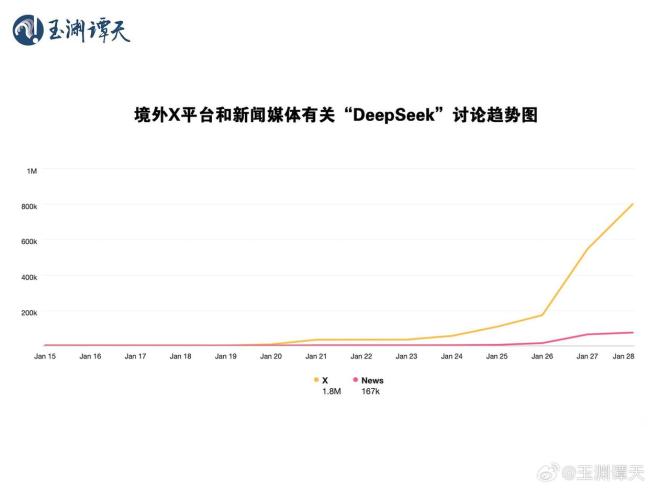
DeepSeek開發(fā)成本大幅降低的原因在于其應(yīng)用了不同的模型訓(xùn)練模式,,打破了美國堆砌算力的方式。在數(shù)據(jù)喂養(yǎng)這一重要環(huán)節(jié)上,,OpenAI選擇了“人海戰(zhàn)術(shù)”,,通過海量數(shù)據(jù)投喂提升能力。而DeepSeek則利用算法對數(shù)據(jù)進(jìn)行總結(jié)和分類,經(jīng)過選擇性處理后再輸送給大模型,,從而優(yōu)化了算力并降低了成本,。目前來看,,Meta耗費(fèi)大量資金訓(xùn)練Llama,,但效果不如成本極低的DeepSeek。這引發(fā)了Meta高層和技術(shù)人員的恐慌,,他們擔(dān)心自己的技術(shù)能力和創(chuàng)新性被質(zhì)疑,,從而失去工作。社交媒體上的討論也顯示,,關(guān)于DeepSeek的帖子數(shù)量遠(yuǎn)高于新聞報(bào)道,,且討論時(shí)間早于新聞媒體五天,這主要是由從事科技工作的自媒體人和員工圈層傳播所致,。

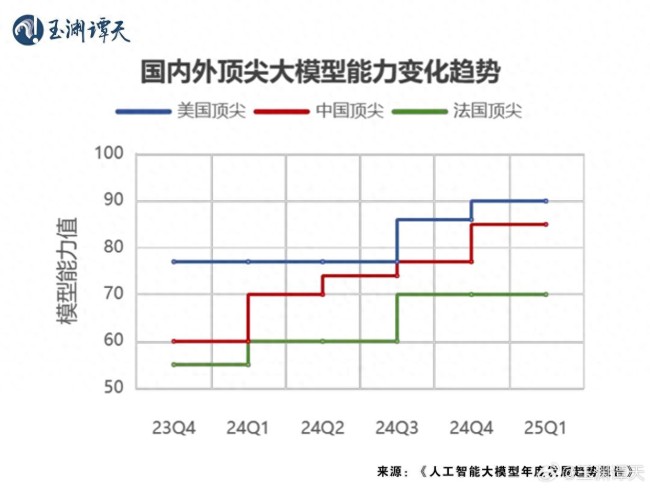
根據(jù)中國工業(yè)互聯(lián)網(wǎng)研究院發(fā)布的《人工智能大模型年度發(fā)展趨勢報(bào)告》,,2024年國內(nèi)大模型的能力進(jìn)步顯著。從2023年第四季度到2025年第一季度的測評(píng)顯示,,國內(nèi)外大模型能力差距縮小了將近75%,。這表明DeepSeek的出現(xiàn)是中國國內(nèi)大模型整體發(fā)展的階段性成果。盡管中國在AI領(lǐng)域的投資額僅為美國的十一分之一,,但在未來仍有很大的發(fā)展空間,。
如今,許多業(yè)內(nèi)人士都喊出了“DeepSeek接班OpenAI”的口號(hào),。事實(shí)上,,DeepSeek的出現(xiàn)并不是要取代其他公司,而是提出了更多樣化的方案,,打破了國際主流大模型的市場壟斷,,在大模型的發(fā)展道路上提供了不同于西方的中國解法,向世界展示了在大模型領(lǐng)域不僅僅只有拼算力一條路,,再次證明了中國智慧的價(jià)值,。

深圳51家長者飯?zhí)脿I業(yè) 提供長者助餐服務(wù)

2025年國資央企將在三大領(lǐng)域加大投資 推動(dòng)戰(zhàn)略性新興產(chǎn)業(yè)倍增

媒體專訪《異人之下》電視劇導(dǎo)演 探索中式超級(jí)英雄之路

美印第安納州總檢察長起訴當(dāng)?shù)鼐L 拒配合移民執(zhí)法

兩根菜薹賣18888元引質(zhì)疑 天價(jià)蔬菜引發(fā)熱議
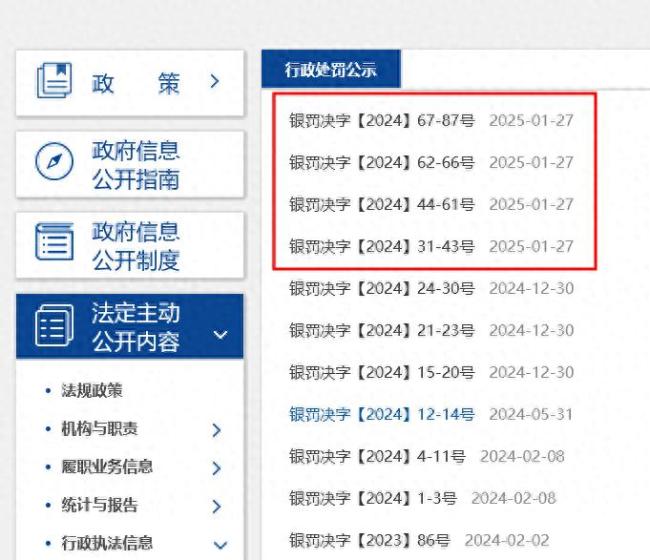
4家銀行合計(jì)罰沒超9900萬元 涉及多項(xiàng)違法行為

菲律賓在南海能掀得起浪嗎 小人使壞徒勞無功

春晚拉薩分會(huì)場今晚有哪些亮點(diǎn) 38種非遺元素閃耀舞臺(tái)

加州南部山火緩解 降水助力滅火進(jìn)展

跟著春晚游山城 開啟打卡之旅

民進(jìn)黨為何不遺余力地推進(jìn)大罷免 手段卑劣引發(fā)爭議

尹錫悅會(huì)被判處死刑嗎 涉嫌“內(nèi)亂頭目”罪名成立?

扎克伯格:AI方面我們需要政府幫助 探討科技未來與競爭態(tài)勢

春節(jié)除夕闖入我家門 非遺打鐵花點(diǎn)亮佳節(jié)
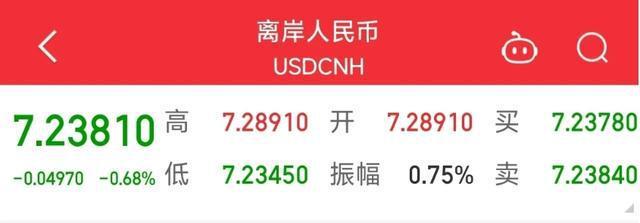
特朗普總統(tǒng)又反悔了,?但這次是好事,,中美貿(mào)易戰(zhàn)2.0可能不打了 金融市場迎來利好

俄稱在烏陣地發(fā)現(xiàn)幾具被鎖士兵遺體 有遭受酷刑痕跡

專家談烏軍失守大諾沃西爾卡 俄軍三面包圍成功

馬斯克的政府效率部誕生一周干了啥 首周削減4.2億美元預(yù)算

專家:AI或持續(xù)作為美股長期驅(qū)動(dòng)力 技術(shù)革命推動(dòng)市場增長

美國無人機(jī)為啥這么貴 高昂成本引發(fā)質(zhì)疑

第9艘055大驅(qū)將首航 解放軍海軍東海南海實(shí)戰(zhàn)演訓(xùn) 強(qiáng)化臨戰(zhàn)演練

學(xué)者:魯比奧把火燒向澤連斯基,暫時(shí)凍結(jié)對烏克蘭的援助
媒體專訪《異人之下》電視劇導(dǎo)演 探索中式超級(jí)英雄之路
深圳51家長者飯?zhí)脿I業(yè) 提供長者助餐服務(wù)
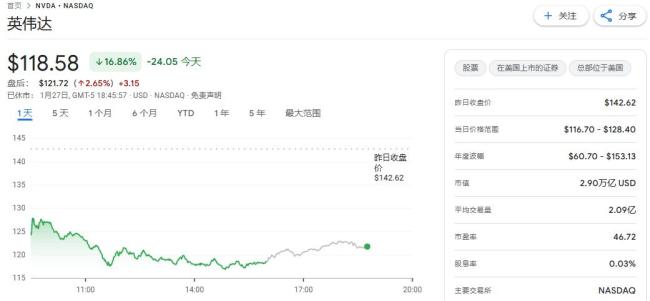
英偉達(dá)稱DeepSeek離不開其芯片 市場需求增加

宇樹機(jī)器人將登上2025央視春晚節(jié)目 人機(jī)共舞《秧BOT》亮相

游子已歸鄉(xiāng) 成都街頭車少人稀 除夕靜享團(tuán)圓
2025年國資央企將在三大領(lǐng)域加大投資 推動(dòng)戰(zhàn)略性新興產(chǎn)業(yè)倍增

成都天府雙塔開啟新春倒計(jì)時(shí) 光影秀點(diǎn)亮蛇年祝福

特朗普的“星際之門”計(jì)劃會(huì)失敗嗎 馬斯克公開質(zhì)疑
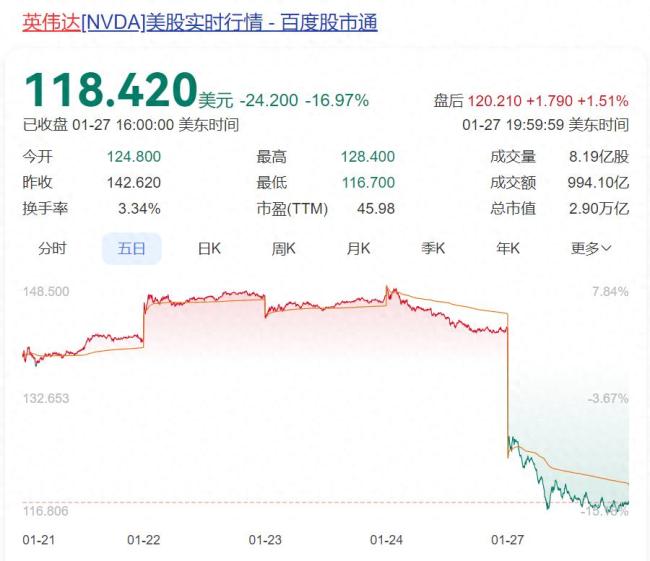
黃仁勛個(gè)人財(cái)富一夜縮水超130億美元 英偉達(dá)股價(jià)暴跌引發(fā)市場震動(dòng)

重慶多個(gè)景區(qū)提供接駁車服務(wù) 便捷游覽體驗(yàn)升級(jí)
比特幣和黃金又將重回歷史新高,,誰才是有力的戰(zhàn)略儲(chǔ)備,? 美元走弱與政策推動(dòng)共助漲勢

實(shí)戰(zhàn)畫面揭示2000磅炸彈真實(shí)威力 十層高樓4秒鐘化為廢墟

專家談歐盟計(jì)劃在格陵蘭島駐軍 地緣政治新焦點(diǎn)
相關(guān)新聞
一夜間DeepSeek在美國刷屏 “這是在做空英偉達(dá)嗎?
2025-01-26 09:52:37一夜間DeepSeek在美國刷屏DeepSeek暴擊美股 引發(fā)全球AI界關(guān)注
2025-01-27 16:51:35DeepSeek暴擊美股DeepSeek又崩了 服務(wù)再次“宕機(jī)”引發(fā)關(guān)注
DeepSeek服務(wù)再次出現(xiàn)“宕機(jī)”。1月27日11點(diǎn)左右,,DeepSeek官網(wǎng)一度顯示網(wǎng)頁和API不可用,,但功能隨后恢復(fù)
2025-01-28 08:17:11DeepSeek又崩了DeepSeek為何能以低成本創(chuàng)造奇跡 混合專家架構(gòu)顯神威
2025-01-28 08:52:05DeepSeek為何能以低成本創(chuàng)造奇跡DeepSeek為何引發(fā)全球轟動(dòng) 中國AI趕超美國
中國AI初創(chuàng)公司深度求索(DeepSeek)在短短一個(gè)月內(nèi)發(fā)布了兩款大模型:DeepSeek-V3和DeepSeek-R1
2025-01-27 19:35:39DeepSeek為何引發(fā)全球轟動(dòng)ChatGPT回應(yīng)被DeepSeek超越 中美兩地登頂引發(fā)關(guān)注
2025-01-27 19:46:08ChatGPT回應(yīng)被DeepSeek超越