揭秘DeepSeek內(nèi)幕,為什么強化學(xué)習(xí)是下一個 Scaling Law,? 創(chuàng)新引領(lǐng)算力革命(2)

實證結(jié)果表明,,DeepSeek MoE 2B的性能與GShard 2.9B相當(dāng),而后者專家參數(shù)量和計算量均為前者的1.5倍,。擴展至16B參數(shù)規(guī)模時,,DeepSeek MoE的性能與LLaMA2 7B相當(dāng),而計算量僅需后者的約40%,。在145B參數(shù)規(guī)模的初步實驗中,,DeepSeek MoE較GShard展現(xiàn)出顯著優(yōu)勢,性能媲美DeepSeek 67B,,而計算量僅需后者的28.5%,。
采用FP8精度訓(xùn)練,節(jié)省計算單元占用,,進(jìn)而節(jié)省算力資源,。低數(shù)據(jù)精度訓(xùn)練是降低訓(xùn)練成本的較有前景的方向之一。通常的大模型訓(xùn)練會采用BF16或FP32/TF32精度作為數(shù)據(jù)計算和存儲的格式,,相比之下,,F(xiàn)P8占用的數(shù)據(jù)位寬僅為FP32的1/4,F(xiàn)P16的1/2,,可以有力地提升計算速度,,降低對存儲的消耗。DeepSeek團(tuán)隊在訓(xùn)練DeepSeek-V3時,,采用的是混合精度框架,,大部分密集計算操作都以FP8格式進(jìn)行,而少數(shù)關(guān)鍵操作則策略性地保留其原始數(shù)據(jù)格式,,以平衡訓(xùn)練效率和數(shù)值穩(wěn)定性,。
采用MTP方法,多token預(yù)測提高模型訓(xùn)練效率,。Meta發(fā)布的論文《Better & Faster Large Language Models via Multi-token Prediction》提出了讓大模型一次性預(yù)測多個token,,并依據(jù)多個token計算損失的方法。在訓(xùn)練中使用MTP技術(shù)主要會通過增加給定數(shù)據(jù)量下獲得的訓(xùn)練信號密度和改變傳統(tǒng)模型的計算模式來降低模型的訓(xùn)練成本。
后訓(xùn)練階段引入GRPO算法,,拋棄MCTS等傳統(tǒng)方法,,優(yōu)化算力開銷。DeepSeek團(tuán)隊首次提出了GRPO的概念并將其應(yīng)用于強化學(xué)習(xí)過程中,,指出應(yīng)用了GRPO技術(shù)的強化學(xué)習(xí)對于強化LLMs的數(shù)學(xué)推理能力非常有效,。在訓(xùn)練R1-Zero的過程中,DeepSeek團(tuán)隊完全依賴于應(yīng)用了GRPO技術(shù)的強化學(xué)習(xí),。
硬件工程化創(chuàng)新方面,隨著大模型不斷發(fā)展,,全球各團(tuán)隊面臨模型參數(shù)越來越大,、數(shù)據(jù)量越來越多的問題。單臺計算設(shè)備難以獨自滿足大模型的要求,,使用多臺設(shè)備同時運算的“分布式并行”策略成為主流選擇,。DeepSeek團(tuán)隊在硬件工程優(yōu)化中使用了PTX代碼,顯著提升了CUDA程序的可移植性,,便于優(yōu)化和精確控制硬件調(diào)度,。

廣東“最強春招會”提供5萬個職位 吸引12萬學(xué)生報名

中國航空工業(yè)集團(tuán)原董事長譚瑞松被捕 涉嫌貪污受賄案進(jìn)展

每天多睡1小時3年體重會輕24斤

張康樂香港街頭氛圍感大片,網(wǎng)友:好優(yōu)越的一張臉

美國男子被熱飲燙傷控訴星巴克獲賠3.6億 天價賠償引發(fā)爭議

美空襲也門為以打促談向伊朗施壓 警告信號升級

存款變保險,?記者臥底:保險銷售冒充銀行職員,,建行外泄儲戶信息 銀行與險企合謀設(shè)局

副教授權(quán)威期刊論文全文抄襲?西安交通大學(xué):屬實 學(xué)校已解除聘用關(guān)系

NASA稱被困太空宇航員最早19日回地球 結(jié)束超9個月滯留

白宮發(fā)特朗普“觀戰(zhàn)”照片 網(wǎng)民批評 和平承諾遭質(zhì)疑
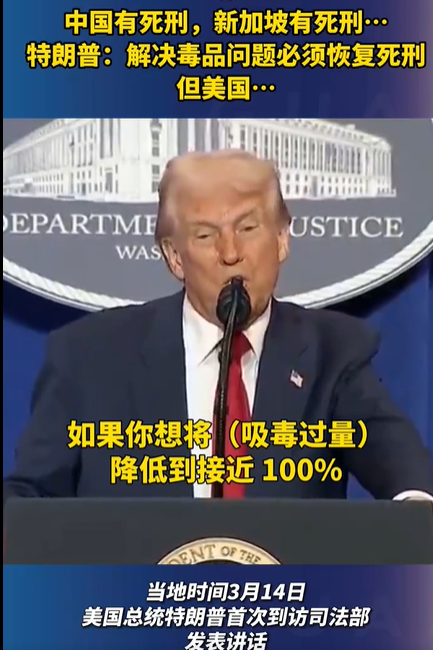
特朗普:解決毒品問題必須恢復(fù)死刑
每天多睡1小時3年體重會輕24斤

官方查封一次性內(nèi)褲涉事企業(yè) 立即行動嚴(yán)肅查處
中國航空工業(yè)集團(tuán)原董事長譚瑞松被捕 涉嫌貪污受賄案進(jìn)展

臺灣屏東市區(qū)凌晨爆發(fā)槍戰(zhàn) 5人受傷警方追緝中

太原620名新兵將踏上軍旅征程 青春熱血獻(xiàn)國防

澤連斯基:俄烏沖突領(lǐng)土問題非常復(fù)雜 對美官員與普京會晤具體內(nèi)容一無所知 ?;饤l件成焦點

也門戰(zhàn)局將會如何發(fā)展 美軍行動引發(fā)局勢升級

男子知假買假獲得10倍賠償

初醫(yī)生緊急下架所有一次性產(chǎn)品 回應(yīng)非滅菌問題

金秀賢金賽綸2015年被拍到過

時間定了,!油價即將大跌!
海底撈“小便門”后續(xù):客流量受影響 忠實客戶仍在支持

專家:美國為何突襲也門胡塞武裝,特朗普在中東再燃戰(zhàn)火,?軍事行動升級引發(fā)關(guān)注

美國務(wù)卿與俄外長通話 同意繼續(xù)努力恢復(fù)美俄溝通 討論胡塞武裝問題

美官員否認(rèn)美航母遭襲 無人機被成功攔截
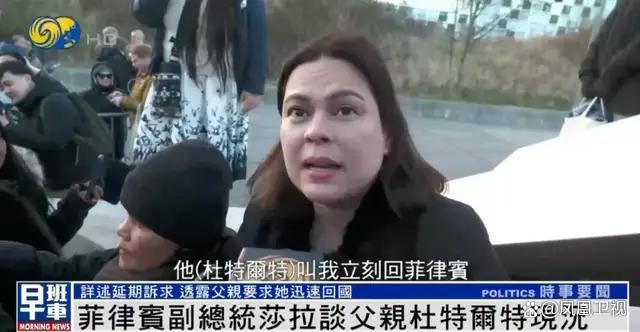
杜特爾特女兒講述:父親要求我立刻回菲律賓 履行國家職責(zé)

老鋪黃金“煉金術(shù)”調(diào)查:排隊黃牛,、熟練工匠和被模仿的古法金 高奢平替引關(guān)注

庫爾斯克戰(zhàn)事持續(xù),澤連斯基:“按需”作戰(zhàn) 烏軍否認(rèn)被圍困

特朗普突然下令開戰(zhàn) 對胡塞武裝發(fā)動空襲 向伊朗發(fā)出強烈信號
廣東“最強春招會”提供5萬個職位 吸引12萬學(xué)生報名

女子路邊撿小孩 孩子哭訴爸爸把媽媽接走了把自己給漏了

蜜雪冰城門店被立案調(diào)查 違規(guī)操作引關(guān)注

俄總統(tǒng)助理:俄方正在為普京與特朗普會晤做準(zhǔn)備 會晤將視需要舉行

加方被批夢游般地陷入與中國貿(mào)易戰(zhàn) 雙重壓力下的加拿大困境
相關(guān)新聞
媒體揭秘國產(chǎn)大模型DeepSeek 硅谷震撼變革
中國國產(chǎn)大模型Deepseek在硅谷引起了轟動,。從斯坦福到麻省理工,,Deepseek R1幾乎一夜之間成為美國頂尖大學(xué)研究人員的首選模型
2025-01-27 15:33:19媒體揭秘國產(chǎn)大模型DeepSeekDeepSeek解析劉謙的魔術(shù)表演 揭秘神奇邏輯
2025-01-30 20:11:58DeepSeek解析劉謙的魔術(shù)表演DeepSeek分析大學(xué)生每月1500夠不夠 實際花費揭秘
2025-02-22 09:32:30DeepSeek分析大學(xué)生每月1500夠不夠DeepSeek理論利潤率高達(dá)545% 模型成本利潤揭秘
2025-03-02 08:07:03DeepSeek理論利潤率高達(dá)545%給游戲上中文配音,,到底多貴 行業(yè)內(nèi)幕揭秘
2025-02-24 13:03:02給游戲上中文配音DeepSeek回答六姊妹移居的原因 六大原因揭秘
2025-02-08 15:02:18DeepSeek回答六姊妹移居的原因