黃仁勛最新2萬(wàn)字演講實(shí)錄:機(jī)器人時(shí)代已經(jīng)到來(lái)(8)

當(dāng)然,,你還可以將更多的這些系統(tǒng)連接在一起,,形成更龐大的計(jì)算網(wǎng)絡(luò)。但真正的奇跡在于這個(gè)MV鏈接芯片,,隨著大語(yǔ)言模型的日益龐大,,其重要性也日益凸顯,。因?yàn)檫@些大語(yǔ)言模型已經(jīng)不適合單獨(dú)放在一個(gè)GPU或節(jié)點(diǎn)上運(yùn)行,它們需要整個(gè)GPU機(jī)架的協(xié)同工作,。就像我剛才提到的那個(gè)新DGX系統(tǒng),,它能夠容納參數(shù)達(dá)到數(shù)十萬(wàn)億的大語(yǔ)言模型。
MV鏈接交換機(jī)本身就是一個(gè)技術(shù)奇跡,,擁有500億個(gè)晶體管,,74個(gè)端口,每個(gè)端口的數(shù)據(jù)速率高達(dá)400GB,。但更重要的是,,交換機(jī)內(nèi)部還集成了數(shù)學(xué)運(yùn)算功能,可以直接進(jìn)行歸約操作,,這在深度學(xué)習(xí)中具有極其重要的意義,。這就是現(xiàn)在的DGX系統(tǒng)的全新面貌。
許多人對(duì)我們表示好奇,。他們提出疑問(wèn),,對(duì)英偉達(dá)的業(yè)務(wù)范疇存在誤解。人們疑惑,,英偉達(dá)怎么可能僅憑制造GPU就變得如此龐大,。因此,很多人形成了這樣一種印象:GPU就應(yīng)該是某種特定的樣子,。
然而,,現(xiàn)在我要展示給你們的是,這確實(shí)是一個(gè)GPU,,但它并非你們想象中的那種,。這是世界上最先進(jìn)的GPU之一,但它主要用于游戲領(lǐng)域,。但我們都清楚,,GPU的真正力量遠(yuǎn)不止于此。
各位,,請(qǐng)看這個(gè),,這才是GPU的真正形態(tài)。這是DGX GPU,專為深度學(xué)習(xí)而設(shè)計(jì),。這個(gè)GPU的背面連接著MV鏈接主干,,這個(gè)主干由5000條線組成,長(zhǎng)達(dá)3公里,。這些線,,就是MV鏈接主干,它們連接了70個(gè)GPU,,形成一個(gè)強(qiáng)大的計(jì)算網(wǎng)絡(luò),。這是一個(gè)電子機(jī)械奇跡,其中的收發(fā)器讓我們能夠在銅線上驅(qū)動(dòng)信號(hào)貫穿整個(gè)長(zhǎng)度,。
因此,,這個(gè)MV鏈接交換機(jī)通過(guò)MV鏈接主干在銅線上傳輸數(shù)據(jù),使我們能夠在單個(gè)機(jī)架中節(jié)省20千瓦的電力,,而這20千瓦現(xiàn)在可以完全用于數(shù)據(jù)處理,,這的確是一項(xiàng)令人難以置信的成就。這就是MV鏈接主干的力量,。

為生成式AI推以太網(wǎng)
但這還不足以滿足需求,,特別是對(duì)于大型人工智能工廠來(lái)說(shuō)更是如此,那么我們還有另一種解決方案,。我們必須使用高速網(wǎng)絡(luò)將這些人工智能工廠連接起來(lái),。我們有兩種網(wǎng)絡(luò)選擇:InfiniBand和以太網(wǎng)。其中,,InfiniBand已經(jīng)在全球各地的超級(jí)計(jì)算和人工智能工廠中廣泛使用,,并且增長(zhǎng)迅速。然而,,并非每個(gè)數(shù)據(jù)中心都能直接使用InfiniBand,因?yàn)樗麄冊(cè)谝蕴W(wǎng)生態(tài)系統(tǒng)上進(jìn)行了大量投資,,而且管理InfiniBand交換機(jī)和網(wǎng)絡(luò)確實(shí)需要一定的專業(yè)知識(shí)和技術(shù),。
因此,我們的解決方案是將InfiniBand的性能帶到以太網(wǎng)架構(gòu)中,,這并非易事,。原因在于,每個(gè)節(jié)點(diǎn),、每臺(tái)計(jì)算機(jī)通常與互聯(lián)網(wǎng)上的不同用戶相連,,但大多數(shù)通信實(shí)際上發(fā)生在數(shù)據(jù)中心內(nèi)部,即數(shù)據(jù)中心與互聯(lián)網(wǎng)另一端用戶之間的數(shù)據(jù)傳輸,。然而,,在人工智能工廠的深度學(xué)習(xí)場(chǎng)景下,GPU并不是與互聯(lián)網(wǎng)上的用戶進(jìn)行通信,而是彼此之間進(jìn)行頻繁的,、密集的數(shù)據(jù)交換,。
它們相互通信是因?yàn)樗鼈兌荚谑占糠纸Y(jié)果。然后它們必須將這些部分結(jié)果進(jìn)行規(guī)約(reduce)并重新分配(redistribute),。這種通信模式的特點(diǎn)是高度突發(fā)性的流量,。重要的不是平均吞吐量,而是最后一個(gè)到達(dá)的數(shù)據(jù),,因?yàn)槿绻阏趶乃腥四抢锸占糠纸Y(jié)果,,并且我試圖接收你所有的部分結(jié)果,如果最后一個(gè)數(shù)據(jù)包晚到了,,那么整個(gè)操作就會(huì)延遲,。對(duì)于人工智能工廠而言,延遲是一個(gè)至關(guān)重要的問(wèn)題,。
所以,,我們關(guān)注的焦點(diǎn)并非平均吞吐量,而是確保最后一個(gè)數(shù)據(jù)包能夠準(zhǔn)時(shí),、無(wú)誤地抵達(dá),。然而,傳統(tǒng)的以太網(wǎng)并未針對(duì)這種高度同步化,、低延遲的需求進(jìn)行優(yōu)化,。為了滿足這一需求,我們創(chuàng)造性地設(shè)計(jì)了一個(gè)端到端的架構(gòu),,使NIC(網(wǎng)絡(luò)接口卡)和交換機(jī)能夠通信,。為了實(shí)現(xiàn)這一目標(biāo),我們采用了四種關(guān)鍵技術(shù):
第一,,英偉達(dá)擁有業(yè)界領(lǐng)先的RDMA(遠(yuǎn)程直接內(nèi)存訪問(wèn))技術(shù)?,F(xiàn)在,我們有了以太網(wǎng)網(wǎng)絡(luò)級(jí)別的RDMA,,它的表現(xiàn)非常出色,。
第二,我們引入了擁塞控制機(jī)制,。交換機(jī)具備實(shí)時(shí)遙測(cè)功能,,能夠迅速識(shí)別并響應(yīng)網(wǎng)絡(luò)中的擁塞情況。當(dāng)GPU或NIC發(fā)送的數(shù)據(jù)量過(guò)大時(shí),,交換機(jī)會(huì)立即發(fā)出信號(hào),,告知它們減緩發(fā)送速率,從而有效避免網(wǎng)絡(luò)熱點(diǎn)的產(chǎn)生,。
第三,,我們采用了自適應(yīng)路由技術(shù),。傳統(tǒng)以太網(wǎng)按固定順序傳輸數(shù)據(jù),但在我們的架構(gòu)中,,我們能夠根據(jù)實(shí)時(shí)網(wǎng)絡(luò)狀況進(jìn)行靈活調(diào)整,。當(dāng)發(fā)現(xiàn)擁塞或某些端口空閑時(shí),我們可以將數(shù)據(jù)包發(fā)送到這些空閑端口,,再由另一端的Bluefield設(shè)備重新排序,,確保數(shù)據(jù)按正確順序返回。這種自適應(yīng)路由技術(shù)極大地提高了網(wǎng)絡(luò)的靈活性和效率,。
第四,,我們實(shí)施了噪聲隔離技術(shù)。在數(shù)據(jù)中心中,,多個(gè)模型同時(shí)訓(xùn)練產(chǎn)生的噪聲和流量可能會(huì)相互干擾,,并導(dǎo)致抖動(dòng)。我們的噪聲隔離技術(shù)能夠有效地隔離這些噪聲,,確保關(guān)鍵數(shù)據(jù)包的傳輸不受影響,。
通過(guò)采用這些技術(shù),我們成功地為人工智能工廠提供了高性能,、低延遲的網(wǎng)絡(luò)解決方案,。在價(jià)值高達(dá)數(shù)十億美元的數(shù)據(jù)中心中,如果網(wǎng)絡(luò)利用率提升40%而訓(xùn)練時(shí)間縮短20%,,這實(shí)際上意味著價(jià)值50億美元的數(shù)據(jù)中心在性能上等同于一個(gè)60億美元的數(shù)據(jù)中心,,揭示了網(wǎng)絡(luò)性能對(duì)整體成本效益的顯著影響。
幸運(yùn)的是,,帶有Spectrum X的以太網(wǎng)技術(shù)正是我們實(shí)現(xiàn)這一目標(biāo)的關(guān)鍵,,它大大提高了網(wǎng)絡(luò)性能,使得網(wǎng)絡(luò)成本相對(duì)于整個(gè)數(shù)據(jù)中心而言幾乎可以忽略不計(jì),。這無(wú)疑是我們?cè)诰W(wǎng)絡(luò)技術(shù)領(lǐng)域取得的一大成就,。
我們擁有一系列強(qiáng)大的以太網(wǎng)產(chǎn)品線,其中最引人注目的是Spectrum X800,。這款設(shè)備以每秒51.2 TB的速度和256路徑(radix)的支持能力,,為成千上萬(wàn)的GPU提供了高效的網(wǎng)絡(luò)連接。接下來(lái),,我們計(jì)劃一年后推出X800 Ultra,,它將支持高達(dá)512路徑的512 radix,,進(jìn)一步提升了網(wǎng)絡(luò)容量和性能,。而X 1600則是為更大規(guī)模的數(shù)據(jù)中心設(shè)計(jì)的,能夠滿足數(shù)百萬(wàn)個(gè)GPU的通信需求,。

隨著技術(shù)的不斷進(jìn)步,,數(shù)百萬(wàn)個(gè)GPU的數(shù)據(jù)中心時(shí)代已經(jīng)指日可待。這一趨勢(shì)的背后有著深刻的原因。一方面,,我們渴望訓(xùn)練更大,、更復(fù)雜的模型;但更重要的是,,未來(lái)的互聯(lián)網(wǎng)和計(jì)算機(jī)交互將越來(lái)越多地依賴于云端的生成式人工智能,。這些人工智能將與我們一起工作、互動(dòng),,生成視頻,、圖像、文本甚至數(shù)字人,。因此,,我們與計(jì)算機(jī)的每一次交互幾乎都離不開生成式人工智能的參與。并且總是有一個(gè)生成式人工智能與之相連,,其中一些在本地運(yùn)行,,一些在你的設(shè)備上運(yùn)行,很多可能在云端運(yùn)行,。
這些生成式人工智能不僅具備強(qiáng)大的推理能力,,還能對(duì)答案進(jìn)行迭代優(yōu)化,以提高答案的質(zhì)量,。這意味著我們未來(lái)將產(chǎn)生海量的數(shù)據(jù)生成需求,。今晚,我們共同見證了這一技術(shù)革新的力量,。
Blackwell,,作為NVIDIA平臺(tái)的第一代產(chǎn)品,自推出以來(lái)便備受矚目,。如今,,全球范圍內(nèi)都迎來(lái)了生成式人工智能的時(shí)代,這是一個(gè)全新的工業(yè)革命的開端,,每個(gè)角落都在意識(shí)到人工智能工廠的重要性,。我們深感榮幸,獲得了來(lái)自各行各業(yè)的廣泛支持,,包括每一家OEM(原始設(shè)備制造商),、電腦制造商、CSP(云服務(wù)提供商),、GPU云,、主權(quán)云以及電信公司等。
Blackwell的成功,、廣泛的采用以及行業(yè)對(duì)其的熱情都達(dá)到了前所未有的高度,,這讓我們深感欣慰,,并在此向大家表示衷心的感謝。然而,,我們的腳步不會(huì)因此而停歇,。在這個(gè)飛速發(fā)展的時(shí)代,我們將繼續(xù)努力提升產(chǎn)品性能,,降低培訓(xùn)和推理的成本,,同時(shí)不斷擴(kuò)展人工智能的能力,使每一家企業(yè)都能從中受益,。我們堅(jiān)信,,隨著性能的提升,成本將進(jìn)一步降低,。而Hopper平臺(tái),,無(wú)疑可能是歷史上最成功的數(shù)據(jù)中心處理器。

Blackwell Ultra將于明年發(fā)布,,下一代平臺(tái)名為Rubin

云南5名網(wǎng)紅被抓 詐騙粉絲11萬(wàn)余元
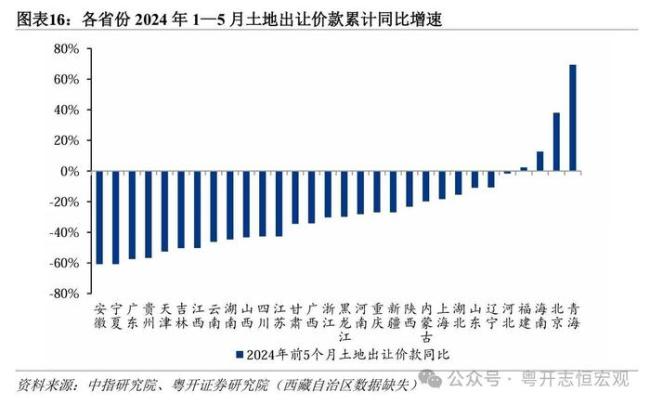
26省賣地收入下滑 地方政府財(cái)政承壓求變

17歲2米28女姚明入選大名單:國(guó)字號(hào)首秀能一鳴驚人嗎,?!

以色列前總理:我們?cè)谶@幾個(gè)月中失去了世界的支持
云南5名網(wǎng)紅被抓 詐騙粉絲11萬(wàn)余元

瞄準(zhǔn)中國(guó),,美軍加速!
17歲2米28女姚明入選大名單:國(guó)字號(hào)首秀能一鳴驚人嗎?,!

秀肌肉?美軍“羅斯?!碧?hào)航母抵韓,,將參加韓美日“自由之刃”軍演

娜扎新電影哭到我心里了,有點(diǎn)期待了,!

白宮擔(dān)憂以總理訪美:不知道他會(huì)說(shuō)些什么

專家稱文理分科讓畢業(yè)生就業(yè)更難 跨學(xué)科能力缺失成障礙

欲升級(jí)擴(kuò)充核武庫(kù) 美國(guó)引全球走向“最危險(xiǎn)的時(shí)刻”

全面戰(zhàn)爭(zhēng),?美國(guó)向以色列保證

當(dāng)美國(guó)海軍“最可怕的噩夢(mèng)”真的來(lái)了……

李凱爾辟謠退出男籃 期待再次披掛上陣
26省賣地收入下滑 地方政府財(cái)政承壓求變

以美就武器交付問(wèn)題陷入爭(zhēng)吵,,以防長(zhǎng)訪美尋求“解凍重型炸彈”

造價(jià)3億多美元扛不住4級(jí)風(fēng) 美軍碼頭為何這么脆

沙特朝覲現(xiàn)死亡潮 千人亡,半數(shù)因酷熱

普京強(qiáng)調(diào)國(guó)防只能依靠自己 自主軍工確保國(guó)家安全

村干部下潛徒手清淤 排水渠通了,,村民心暖了

普京:沒(méi)人會(huì)援俄武器,,我們能自給自足

“這就是宇宙中最道德的軍隊(duì),?”

烏克蘭空襲克里米亞致5死逾百傷 俄方誓言回應(yīng)
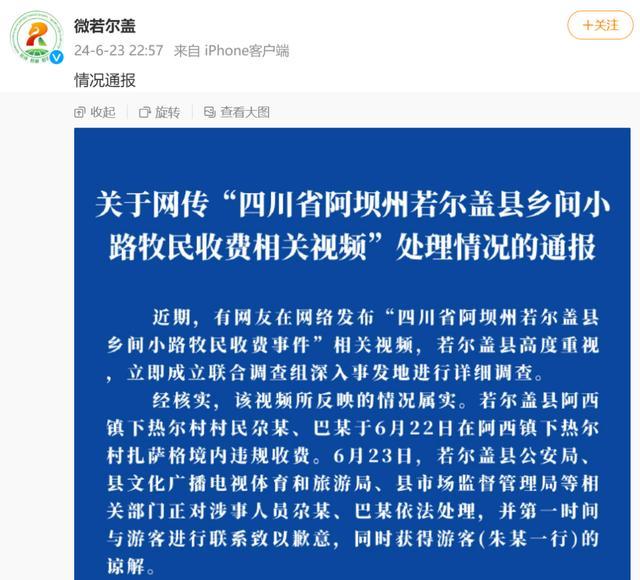
阿壩旅游遭攔路收費(fèi) 官方通報(bào)處置結(jié)果

胡塞武裝趕跑了“艾森豪威爾”號(hào)航母,菲律賓懵了,!

汽車高管花式推薦大學(xué)專業(yè) 新機(jī)遇在哪,?

俄對(duì)烏能源設(shè)施發(fā)動(dòng)集群打擊,!澤連斯基:去年冬季以來(lái),俄已摧毀烏一半發(fā)電能力

貴州村超少年圓夢(mèng)歐洲杯 足球激情跨越國(guó)界

胡塞武裝“襲擊疑云”下,美軍“艾森豪威爾”號(hào)航母撤離紅海,!

享界S9內(nèi)飾曝光 8月上市 豪華行政級(jí)體驗(yàn)來(lái)襲

針對(duì)中國(guó)意圖明顯,,效果遭到各界質(zhì)疑,!美軍加速組建關(guān)島“瀕海作戰(zhàn)團(tuán)”
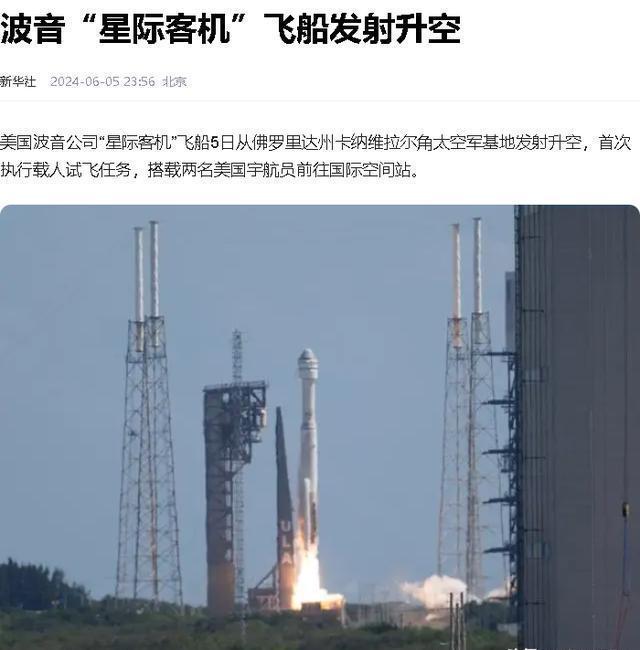
美國(guó)宇航員滯留太空 生命安危引關(guān)注

多地鼓勵(lì)放棄,、退出農(nóng)村宅基地 新政策促房地產(chǎn)市場(chǎng)平穩(wěn)發(fā)展

警惕,!菲總統(tǒng)最新言論,,話里有話
相關(guān)新聞
黃仁勛妄稱臺(tái)灣為“國(guó)家”,,黃仁勛“飄”了?
2024-06-07 18:12:09黃仁勛妄稱臺(tái)灣為“國(guó)家”黃仁勛有望超越馬斯克成全球首富 GPU巨頭引領(lǐng)AI時(shí)代新篇章
2024-05-27 22:49:22黃仁勛有望超越馬斯克成全球首富黃仁勛稱臺(tái)灣為國(guó)家 言論引爭(zhēng)議
2024-06-07 08:18:25黃仁勛稱臺(tái)灣為國(guó)家馬斯克向左,,黃仁勛向右 華人首富之路加速,?
2024-06-01 12:37:58馬斯克向左黃仁勛加州理工畢業(yè)典禮演講:我是個(gè)好老板
2024-06-18 09:45:41黃仁勛加州理工畢業(yè)典禮演講:我是個(gè)好老板黃仁勛在女粉絲胸前簽名 引網(wǎng)絡(luò)熱議
2024-06-06 17:31:45黃仁勛在女粉絲胸前簽名