黃仁勛最新2萬字演講實錄:機(jī)器人時代已經(jīng)到來(7)

當(dāng)人工智能數(shù)據(jù)通過合成方式生成,,并結(jié)合強(qiáng)化學(xué)習(xí)技術(shù)時,,數(shù)據(jù)生成的速率將得到顯著提升。隨著數(shù)據(jù)生成的增長,,對計算能力的需求也將相應(yīng)增加,。我們即將邁入一個新時代,在這個時代中,,人工智能將能夠?qū)W習(xí)物理定律,,理解并基于物理世界的數(shù)據(jù)進(jìn)行決策和行動。因此,,我們預(yù)計人工智能模型將繼續(xù)擴(kuò)大,,對GPU性能的要求也將越來越高。
為滿足這一需求,,Blackwell應(yīng)運而生,。這款GPU專為支持新一代人工智能設(shè)計,擁有幾項關(guān)鍵技術(shù),。這種芯片尺寸之大在業(yè)界首屈一指,。我們采用了兩片盡可能大的芯片,通過每秒10太字節(jié)的高速鏈接,,結(jié)合世界上最先進(jìn)的SerDes(高性能接口或連接技術(shù))將它們緊密連接在一起,。進(jìn)一步地,我們將兩片這樣的芯片放置在一個計算機(jī)節(jié)點上,,并通過Grace CPU進(jìn)行高效協(xié)調(diào),。
Grace CPU的用途廣泛,不僅適用于訓(xùn)練場景,,還在推理和生成過程中發(fā)揮關(guān)鍵作用,,如快速檢查點和重啟,。此外,它還能存儲上下文,,讓人工智能系統(tǒng)擁有記憶,,并能理解用戶對話的上下文,這對于增強(qiáng)交互的連續(xù)性和流暢性至關(guān)重要,。
我們推出的第二代Transformer引擎進(jìn)一步提升了人工智能的計算效率,。這款引擎能夠根據(jù)計算層的精度和范圍需求,動態(tài)調(diào)整至較低的精度,,從而在保持性能的同時降低能耗,。同時,Blackwell GPU還具備安全人工智能功能,,確保用戶能夠要求服務(wù)提供商保護(hù)其免受盜竊或篡改,。
在GPU的互聯(lián)方面,我們采用了第五代MV Link技術(shù),,它允許我們輕松連接多個GPU,。此外,Blackwell GPU還配備了第一代可靠性和可用性引擎(Ras系統(tǒng)),,這一創(chuàng)新技術(shù)能夠測試芯片上的每一個晶體管,、觸發(fā)器、內(nèi)存以及片外內(nèi)存,,確保我們在現(xiàn)場就能準(zhǔn)確判斷特定芯片是否達(dá)到了平均故障間隔時間(MTBF)的標(biāo)準(zhǔn),。
對于大型超級計算機(jī)來說,可靠性尤為關(guān)鍵,。擁有10,000個GPU的超級計算機(jī)的平均故障間隔時間可能以小時為單位,,但當(dāng)GPU數(shù)量增加至100,000個時,平均故障間隔時間將縮短至以分鐘為單位,。因此,,為了確保超級計算機(jī)能夠長時間穩(wěn)定運行,以訓(xùn)練那些可能需要數(shù)個月時間的復(fù)雜模型,,我們必須通過技術(shù)創(chuàng)新來提高可靠性,。而可靠性的提升不僅能夠增加系統(tǒng)的正常運行時間,,還能有效降低成本,。
最后,我們還在Blackwell GPU中集成了先進(jìn)的解壓縮引擎,。在數(shù)據(jù)處理方面,,解壓縮速度至關(guān)重要。通過集成這一引擎,,我們可以從存儲中拉取數(shù)據(jù)的速度比現(xiàn)有技術(shù)快20倍,,從而極大地提升了數(shù)據(jù)處理效率,。
Blackwell GPU的上述功能特性使其成為一款令人矚目的產(chǎn)品。在之前的GTC大會上,,我曾向大家展示了處于原型狀態(tài)的Blackwell,。而現(xiàn)在,我們很高興地宣布,,這款產(chǎn)品已經(jīng)投入生產(chǎn),。

各位,這就是Blackwell,,使用了令人難以置信的技術(shù),。這是我們的杰作,是當(dāng)今世界上最復(fù)雜,、性能最高的計算機(jī),。其中,我們特別要提到的是Grace CPU,,它承載了巨大的計算能力,。請看,這兩個Blackwell芯片,,它們緊密相連,。你注意到了嗎?這就是世界上最大的芯片,,而我們使用每秒高達(dá)A10TB的鏈接將兩片這樣的芯片融為一體,。
那么,Blackwell究竟是什么呢,?它的性能之強(qiáng)大,,簡直令人難以置信。請仔細(xì)觀察這些數(shù)據(jù),。在短短八年內(nèi),,我們的計算能力、浮點運算以及人工智能浮點運算能力增長了1000倍,。這速度,,幾乎超越了摩爾定律在最佳時期的增長。
Blackwell計算能力的增長簡直驚人,。而更值得一提的是,,每當(dāng)我們的計算能力提高時,成本卻在不斷下降,。讓我給你們展示一下,。我們通過提升計算能力,用于訓(xùn)練GPT-4模型(2萬億參數(shù)和8萬億Token)的能量下降了350倍,。
想象一下,,如果使用Pascal進(jìn)行同樣的訓(xùn)練,,它將消耗高達(dá)1000吉瓦時的能量。這意味著需要一個吉瓦數(shù)據(jù)中心來支持,,但世界上并不存在這樣的數(shù)據(jù)中心,。即便存在,它也需要連續(xù)運行一個月的時間,。而如果是一個100兆瓦的數(shù)據(jù)中心,,那么訓(xùn)練時間將長達(dá)一年。
顯然,,沒有人愿意或能夠創(chuàng)造這樣的數(shù)據(jù)中心,。這就是為什么八年前,像ChatGPT這樣的大語言模型對我們來說還是遙不可及的夢想,。但如今,,我們通過提升性能并降低能耗實現(xiàn)了這一目標(biāo)。
我們利用Blackwell將原本需要高達(dá)1000吉瓦時的能量降低到僅需3吉瓦時,,這一成就無疑是令人震驚的突破,。想象一下,使用1000個GPU,,它們所消耗的能量竟然只相當(dāng)于一杯咖啡的熱量,。而10,000個GPU,更是只需短短10天左右的時間就能完成同等任務(wù),。八年間取得的這些進(jìn)步,,簡直令人難以置信。

Blackwell不僅適用于推理,,其在Token生成性能上的提升更是令人矚目,。在Pascal時代,每個Token消耗的能量高達(dá)17,000焦耳,,這大約相當(dāng)于兩個燈泡運行兩天的能量,。而生成一個GPT-4的Token,幾乎需要兩個200瓦特的燈泡持續(xù)運行兩天,??紤]到生成一個單詞大約需要3個Token,這確實是一個巨大的能量消耗,。
然而,,現(xiàn)在的情況已經(jīng)截然不同。Blackwell使得生成每個Token只需消耗0.4焦耳的能量,,以驚人的速度和極低的能耗進(jìn)行Token生成,。這無疑是一個巨大的飛躍,。但即使如此,,我們?nèi)圆粷M足,。為了更大的突破,我們必須建造更強(qiáng)大的機(jī)器,。
這就是我們的DGX系統(tǒng),,Blackwell芯片將被嵌入其中。這款系統(tǒng)采用空氣冷卻技術(shù),,內(nèi)部配備了8個這樣的GPU,。看看這些GPU上的散熱片,,它們的尺寸之大令人驚嘆,。整個系統(tǒng)功耗約為15千瓦,完全通過空氣冷卻實現(xiàn),。這個版本兼容X86,,并已應(yīng)用于我們已發(fā)貨的服務(wù)器中。
然而,,如果你更傾向于液體冷卻技術(shù),,我們還有一個全新的系統(tǒng)——MGX。它基于這款主板設(shè)計,,我們稱之為“模塊化”系統(tǒng),。MGX系統(tǒng)的核心在于兩塊Blackwell芯片,每個節(jié)點都集成了四個Blackwell芯片,。它采用了液體冷卻技術(shù),,確保了高效穩(wěn)定的運行。
整個系統(tǒng)中,,這樣的節(jié)點共有九個,,共計72個GPU,構(gòu)成了一個龐大的計算集群,。這些GPU通過全新的MV鏈接技術(shù)緊密相連,,形成了一個無縫的計算網(wǎng)絡(luò)。MV鏈接交換機(jī)堪稱技術(shù)奇跡,。它是目前世界上最先進(jìn)的交換機(jī),,數(shù)據(jù)傳輸速率令人咋舌。這些交換機(jī)使得每個Blackwell芯片高效連接,,形成了一個巨大的72GPU集群,。

這一集群的優(yōu)勢何在?首先,,在GPU域中,,它現(xiàn)在表現(xiàn)得就像一個單一的、超大規(guī)模的GPU,。這個“超級GPU”擁有72個GPU的核心能力,,相較于上一代的8個GPU,,性能提升了9倍。同時,,帶寬增加了18倍,,AI FLOPS(每秒浮點運算次數(shù))更是提升了45倍,而功率僅增加了10倍,。也就是說,,一個這樣的系統(tǒng)能提供100千瓦的強(qiáng)勁動力,而上一代僅為10千瓦,。

云南5名網(wǎng)紅被抓 詐騙粉絲11萬余元
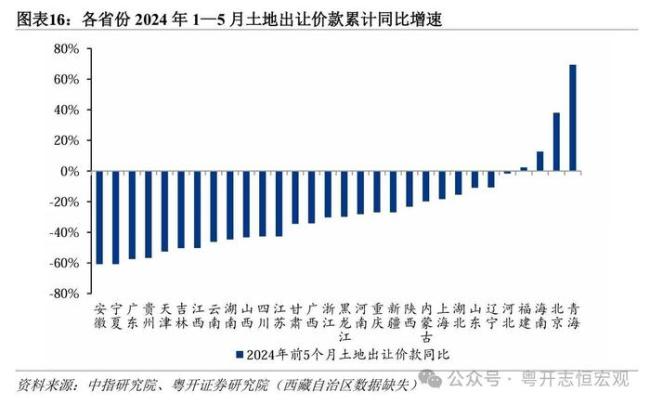
26省賣地收入下滑 地方政府財政承壓求變

17歲2米28女姚明入選大名單:國字號首秀能一鳴驚人嗎,?!

以色列前總理:我們在這幾個月中失去了世界的支持
云南5名網(wǎng)紅被抓 詐騙粉絲11萬余元

瞄準(zhǔn)中國,,美軍加速!
17歲2米28女姚明入選大名單:國字號首秀能一鳴驚人嗎?,!

秀肌肉?美軍“羅斯?!碧柡侥傅猪n,,將參加韓美日“自由之刃”軍演

娜扎新電影哭到我心里了,有點期待了,!

白宮擔(dān)憂以總理訪美:不知道他會說些什么

專家稱文理分科讓畢業(yè)生就業(yè)更難 跨學(xué)科能力缺失成障礙

欲升級擴(kuò)充核武庫 美國引全球走向“最危險的時刻”

全面戰(zhàn)爭,?美國向以色列保證

當(dāng)美國海軍“最可怕的噩夢”真的來了……

李凱爾辟謠退出男籃 期待再次披掛上陣
26省賣地收入下滑 地方政府財政承壓求變

以美就武器交付問題陷入爭吵,,以防長訪美尋求“解凍重型炸彈”

造價3億多美元扛不住4級風(fēng) 美軍碼頭為何這么脆

沙特朝覲現(xiàn)死亡潮 千人亡,半數(shù)因酷熱

普京強(qiáng)調(diào)國防只能依靠自己 自主軍工確保國家安全

村干部下潛徒手清淤 排水渠通了,,村民心暖了

普京:沒人會援俄武器,,我們能自給自足

“這就是宇宙中最道德的軍隊,?”

烏克蘭空襲克里米亞致5死逾百傷 俄方誓言回應(yīng)
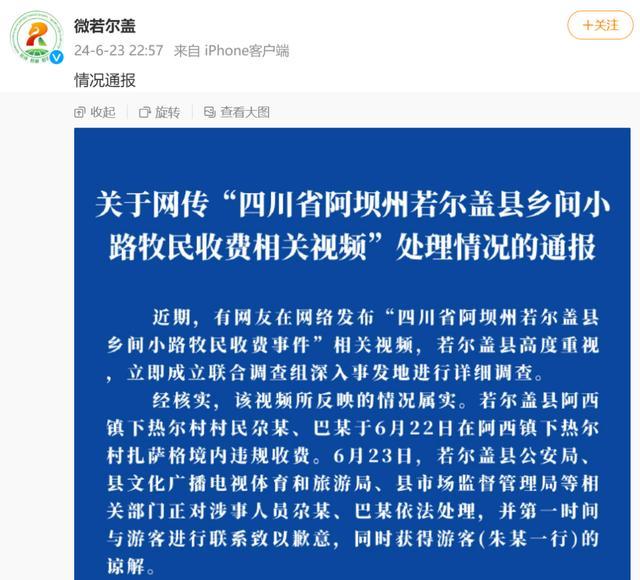
阿壩旅游遭攔路收費 官方通報處置結(jié)果

胡塞武裝趕跑了“艾森豪威爾”號航母,菲律賓懵了!

汽車高管花式推薦大學(xué)專業(yè) 新機(jī)遇在哪?

俄對烏能源設(shè)施發(fā)動集群打擊,!澤連斯基:去年冬季以來,,俄已摧毀烏一半發(fā)電能力

貴州村超少年圓夢歐洲杯 足球激情跨越國界

胡塞武裝“襲擊疑云”下,美軍“艾森豪威爾”號航母撤離紅海,!

享界S9內(nèi)飾曝光 8月上市 豪華行政級體驗來襲

針對中國意圖明顯,,效果遭到各界質(zhì)疑,!美軍加速組建關(guān)島“瀕海作戰(zhàn)團(tuán)”
美國宇航員滯留太空 生命安危引關(guān)注

多地鼓勵放棄,、退出農(nóng)村宅基地 新政策促房地產(chǎn)市場平穩(wěn)發(fā)展

警惕,!菲總統(tǒng)最新言論,,話里有話
相關(guān)新聞
黃仁勛妄稱臺灣為“國家”,,黃仁勛“飄”了?
美國英偉達(dá)公司的創(chuàng)辦人及CEO黃仁勛訪問臺灣,,此行引發(fā)臺灣地區(qū)的高度關(guān)注,,他的言論成為媒體聚焦點
2024-06-07 18:12:09黃仁勛妄稱臺灣為“國家”黃仁勛有望超越馬斯克成全球首富 GPU巨頭引領(lǐng)AI時代新篇章
2024-05-27 22:49:22黃仁勛有望超越馬斯克成全球首富黃仁勛稱臺灣為國家 言論引爭議
2024-06-07 08:18:25黃仁勛稱臺灣為國家馬斯克向左,,黃仁勛向右 華人首富之路加速?
華人問鼎全球首富的位置,正逐漸從夢想邁向現(xiàn)實,。英偉達(dá),,在人工智能時代的潮頭傲立,僅一年半內(nèi)股價激增十倍,,五年視野下更是實現(xiàn)了二十八倍的驚人飛躍
2024-06-01 12:37:58馬斯克向左黃仁勛加州理工畢業(yè)典禮演講:我是個好老板
2024-06-18 09:45:41黃仁勛加州理工畢業(yè)典禮演講:我是個好老板黃仁勛在女粉絲胸前簽名 引網(wǎng)絡(luò)熱議
2024-06-06 17:31:45黃仁勛在女粉絲胸前簽名








