拋棄OpenAI,F(xiàn)igure亮王牌:史上首次兩個機(jī)器人「共腦」

拋棄OpenAI,,F(xiàn)igure亮王牌:史上首次兩個機(jī)器人「共腦」!Figure在與OpenAI分手后,,自主研發(fā)了首個模型Helix,。這個視覺-語言-動作模型被直接應(yīng)用于人形機(jī)器人大腦中,讓機(jī)器人具備感知,、語言理解和學(xué)習(xí)控制的能力,,是一個端到端的通用模型,。Figure的目標(biāo)是發(fā)展家庭機(jī)器人,其內(nèi)部的AI需要像人一樣推理,,處理各種家庭用品,。
Helix目前主要用于Figure上半身的控制,包括手腕,、頭部,、單個手指和軀干,能夠以高速率執(zhí)行復(fù)雜任務(wù),。只需一句話,,機(jī)器人就可以拿起任何物品。例如,,當(dāng)被要求“撿起沙漠物品”時,,Helix會識別出玩具仙人掌,選擇最近的手,,并執(zhí)行精確的電機(jī)指令來抓住它,。
拋棄OpenAI,F(xiàn)igure亮王牌:史上首次兩個機(jī)器人「共腦」
此外,,Helix還能精準(zhǔn)地處理生活中的各種小物件,,如金屬鏈、帽子,、玩具等,。它還可以將物品放置在冰箱里,而且兩個Figure機(jī)器人可以協(xié)作完成這一任務(wù),。Helix是首個同時操控兩臺機(jī)器人的VLA,,使它們能夠解決共同的長序列操作任務(wù),即使面對從未見過的物品也能應(yīng)對自如,。
新款模型采用單一神經(jīng)網(wǎng)絡(luò)權(quán)重學(xué)習(xí)所有行為,,無需特定微調(diào)。它還是首款完全在嵌入式低功耗GPU上運(yùn)行的VLA,,未來商業(yè)部署甚至進(jìn)入家庭指日可待,。家庭環(huán)境對機(jī)器人技術(shù)來說是巨大挑戰(zhàn),因?yàn)榧抑谐錆M了無數(shù)不可預(yù)測形狀,、尺寸,、顏色和質(zhì)地的物品。為了讓機(jī)器人在家庭中發(fā)揮作用,,它們需要生成智能化的新行為來應(yīng)對各種情況,,特別是那些從未見過的物品。
當(dāng)前,教會機(jī)器人一個新行為需要大量人力投入,,要么博士級專家手動編程,,要么數(shù)千次示教。這兩種方法的成本都難以承受,。但通過Helix,,只需通過自然語言即可實(shí)時定義新技能。這種能力將從根本上改變機(jī)器人技術(shù)的發(fā)展軌跡,。突然間,,曾經(jīng)需要數(shù)百次示教才能掌握的新技能,現(xiàn)在只需通過自然語言與機(jī)器人對話就能立即獲得,。

你怎么看患者給醫(yī)生偷偷錄音 尊重與信任何在

今天北京北風(fēng)強(qiáng)勁 明天開始天晴氣溫升 晝夜溫差加大請注意保暖

美國空襲也門胡塞武裝目的是什么 警告伊朗停止支持

匈總理要求歐盟不讓烏克蘭加入 歐爾班提出12點(diǎn)要求

《五哈》五指山海報(bào),!節(jié)目組這波操作是要笑死人不償命?

丞磊公司嚴(yán)正聲明,,網(wǎng)友:支持維權(quán),!

劉曉慶對中年婚戀題材非常有把握 74歲挑戰(zhàn)忘年戀短劇

硬剛美國的加拿大是個什么樣的國家 能源武器與政治團(tuán)結(jié)

國安部公開4名“臺獨(dú)”網(wǎng)軍身份信息!臺資通電軍“倚網(wǎng)謀獨(dú)”終是死路一條,!

41歲歌手宣布復(fù)出,,有廣東歌迷跨省捧場!他的代表作很多人都聽過…… 《我的滑板鞋》再響舞臺

與大16歲女友同居31年 男子人財(cái)兩空 法律無情揭示真相
今天北京北風(fēng)強(qiáng)勁 明天開始天晴氣溫升 晝夜溫差加大請注意保暖

“用了18枚導(dǎo)彈”,!美國航母突然遭襲 胡塞武裝誓言報(bào)復(fù)

莫迪喊話烏克蘭和俄羅斯談才有用 直接對話是關(guān)鍵

3歲小女孩營養(yǎng)不良體重竟才16斤,,醫(yī)生:喂養(yǎng)不當(dāng) 再加重會影響孩子各個功能

震撼航拍!中國最長火車到底有多長

賣增重蝦仁公司負(fù)責(zé)人:被點(diǎn)名也沒辦法 違規(guī)添加保水劑引發(fā)關(guān)注

烏在庫爾斯克作戰(zhàn)行動結(jié)束意味著啥 戰(zhàn)場失利與外部施壓交織

歐豪說謝望和的故事就是自己的故事 角色共鳴深厚

英國邀20國派兵烏克蘭有何意味 歐洲戰(zhàn)略自主的嘗試
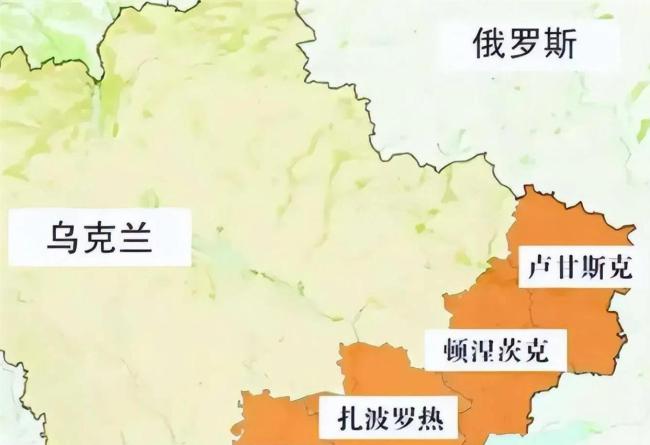
美方再次施壓烏克蘭割地 談判僵局難解
美國空襲也門胡塞武裝目的是什么 警告伊朗停止支持

春裝準(zhǔn)備好了嗎 帽子添彩防曬兩不誤
你怎么看患者給醫(yī)生偷偷錄音 尊重與信任何在

全網(wǎng)首拆小米SU7 Ultra,!金車標(biāo)成財(cái)富密碼,?小米U7Ultra首遭魔性拆解

莫迪對華最新表態(tài):確保分歧不會演變成爭端,進(jìn)行“健康且自然”的競爭 強(qiáng)調(diào)對話解決問題
FBI等部門警告:美數(shù)百用戶已遭“美杜莎”勒索軟件攻擊,!

資通電軍是干什么的 網(wǎng)絡(luò)攻擊與滲透真相

專家:烏克蘭正淪為犧牲品 大國博弈下的棋子

海底撈,,栽在兩個17歲男孩身上 公關(guān)失誤引發(fā)爭議
FBI等部門警告:美數(shù)百用戶已遭“美杜莎”勒索軟件攻擊,威脅范圍正在擴(kuò)大

每周跨40公里學(xué)模特門店要關(guān)門,,費(fèi)用怎么退?

學(xué)者解讀特朗普下令空襲胡塞武裝 意在向伊朗發(fā)出警告

匈總理要求歐盟不讓烏克蘭加入 向歐盟提出十二項(xiàng)要求

預(yù)測:菲律賓總統(tǒng)馬科斯的結(jié)局,,誰將笑到最后,?
相關(guān)新聞
SB OpenAI Japan成立 軟銀與OpenAI深化合作
2025-02-05 00:50:43SBOpenAIJapan成立SB OpenAI 軟銀與OpenAI聯(lián)手打造AI新合資企業(yè)
軟銀承諾每年花費(fèi)30億美元使用OpenAI的技術(shù)
2025-02-04 19:08:49SBOpenAI人民“拋棄”波司登,?
2024-12-26 20:13:51人民拋棄波司登馬斯克加碼訴訟OpenAI 指控壟斷市場
2024-11-27 15:41:00馬斯克加碼訴訟OpenAIOpenAI被提起訴訟 版權(quán)爭議升級
2024-12-01 13:39:00OpenAI被提起訴訟OpenAI希望與中國合作 愿盡最大努力
2025-02-12 09:26:53OpenAI希望與中國合作








