天才創(chuàng)始人對(duì)談AI教父Hinton:多模態(tài)是AI的未來(lái),,醫(yī)療將發(fā)揮AI最大的潛力(6)

主持人:你可能會(huì)說(shuō),它會(huì)超越人類(lèi)的認(rèn)知,。盡管我們看到了一些例子,,但貌似尚未真正見(jiàn)到你說(shuō)的這點(diǎn)。很大程度上,,我們?nèi)匀惶幱诋?dāng)前的科學(xué)水平,。你認(rèn)為什么能讓它開(kāi)始有所超越呢?
Hinton:我覺(jué)得在特定情況中已經(jīng)看到這點(diǎn)了,。以AlphaGo為例,。與李世石的那場(chǎng)著名比賽中,AlphaGo的第37步,,所有專(zhuān)家看來(lái)都覺(jué)得是錯(cuò)棋,,但后來(lái)他們意識(shí)到這又是一步妙棋。
這已經(jīng)是在那個(gè)有限的領(lǐng)域內(nèi),,頗具創(chuàng)造力的動(dòng)作,。隨著模型規(guī)模增加,這樣的例子會(huì)更多的,。
主持人:AlphaGo的不同之處在于,,它使用了強(qiáng)化學(xué)習(xí),能夠超越當(dāng)前狀態(tài),。它從模仿學(xué)習(xí)開(kāi)始,,觀察人類(lèi)如何在棋盤(pán)上博弈,然后通過(guò)自我對(duì)弈,,最終有所超越,。你認(rèn)為這是當(dāng)前數(shù)據(jù)實(shí)驗(yàn)室缺少的嗎?
Hinton:我認(rèn)為這很可能有所缺失,。AlphaGo和AlphaZero的自我對(duì)弈,,是它能夠做出這些創(chuàng)造性舉動(dòng)的重要原因。但這不是完全必要的,。
很久以前我做過(guò)一個(gè)小實(shí)驗(yàn),,訓(xùn)練神經(jīng)網(wǎng)絡(luò)識(shí)別手寫(xiě)數(shù)字,。給它訓(xùn)練數(shù)據(jù),一半的答案是錯(cuò)誤的,。它能學(xué)得多好,?你把一半的答案弄錯(cuò)一次,然后保持這種狀態(tài),。所以,,它不能通過(guò)只看同一個(gè)例子來(lái)把錯(cuò)誤率平均。有時(shí)答案正確,,有時(shí)答案錯(cuò)誤,,訓(xùn)練數(shù)據(jù)的誤差為50%。
但是你訓(xùn)練反向傳播,,誤差會(huì)降到5%或更低,。換句話說(shuō),從標(biāo)記不良的數(shù)據(jù)中,,它可以得到更好的結(jié)果,。它可以看到訓(xùn)練數(shù)據(jù)是錯(cuò)誤的。
聰明的學(xué)生能比他們的導(dǎo)師更聰明,。即使接收了導(dǎo)師傳授的所有內(nèi)容,,但他們能取其精華去其糟粕,最終比導(dǎo)師更聰明,。因此,,這些大型神經(jīng)網(wǎng)絡(luò),,其實(shí)具有超越訓(xùn)練數(shù)據(jù)的能力,,大多數(shù)人沒(méi)有意識(shí)到。
主持人:這些模型能夠獲得推理能力嗎,?一種可能的方法是,,在這些模型之上添加某種啟發(fā)式方法。目前,,許多研究都在嘗試這種,,即將一個(gè)思維鏈的推理反饋到模型自身中。另一種可能的方法是,,在模型本身中增加參數(shù)規(guī)模,。你對(duì)此有何看法?
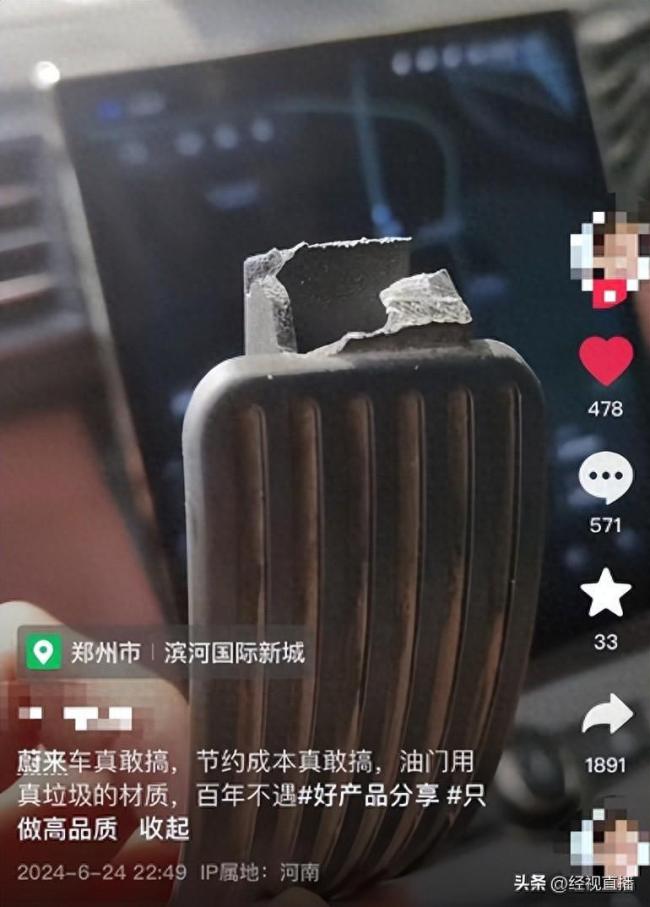
蔚來(lái)回應(yīng)加速踏板斷裂 涉事車(chē)輛系二手事故車(chē)

姆巴佩歐洲杯首球刷爆4大紀(jì)錄,!神劇本:8強(qiáng)戰(zhàn),,姆皇有望對(duì)決C羅

姆巴佩打入歐洲杯首球,,法國(guó)隊(duì)卻落入淘汰賽“死亡半?yún)^(qū)” 巨星救主難阻危局

美軍艦艇,煉就“金剛不壞之身”,?軍事觀察員解讀

事發(fā)日本,,以色列游客預(yù)定被取消……
姆巴佩打入歐洲杯首球,法國(guó)隊(duì)卻落入淘汰賽“死亡半?yún)^(qū)” 巨星救主難阻危局
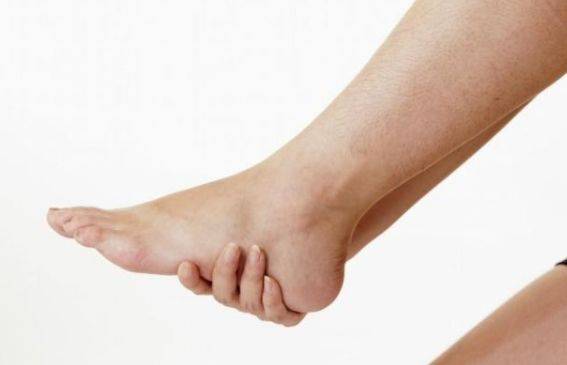
走路多了腳底痛,?若出現(xiàn)這些癥狀,可能是“足弓塌陷”在預(yù)警

匈牙利反對(duì)?歐盟提出變通方法,,直接繞過(guò)

再?gòu)?fù)活,?臺(tái)軍公開(kāi)展示“輪型戰(zhàn)車(chē)”樣車(chē)

于根偉下課進(jìn)入倒計(jì)時(shí)?津門(mén)虎新帥或敲定大牌洋教頭

魏大勛舞會(huì)穿搭,,工作室曬圖,網(wǎng)友:很帥氣

馬來(lái)西亞前總理馬哈蒂爾接受專(zhuān)訪:美國(guó)喜歡“引戰(zhàn)”,,然后大發(fā)戰(zhàn)爭(zhēng)之財(cái)
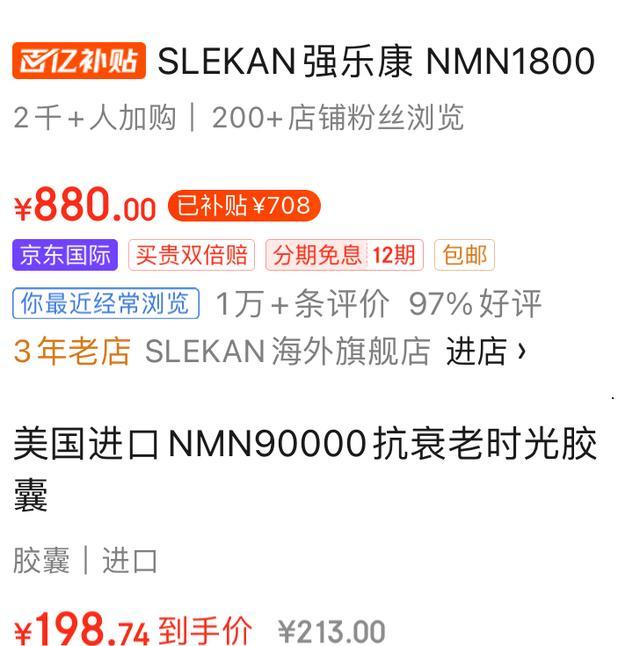
長(zhǎng)生不老“神藥”NMN禁售風(fēng)波 多方回應(yīng)

內(nèi)塔尼亞胡稱(chēng)加沙激戰(zhàn)“接近結(jié)束”,美媒:戰(zhàn)爭(zhēng)可能很快進(jìn)入一個(gè)變化時(shí)期
三只羊被指售假茅臺(tái) 官方聲明嚴(yán)守正品承諾

這個(gè)可憐人,,最終向美國(guó)低了頭
就這,?美軍又來(lái)跟龍王比寶了……

菲外長(zhǎng)最新表態(tài)!“希望與中國(guó)進(jìn)行對(duì)話”

什么信號(hào),?臺(tái)軍演習(xí)出現(xiàn)新變化

爺爺病床上撫摸奶奶臉頰攜手凝望 本來(lái)答應(yīng)好奶奶要回家的

多地“老破小”掛牌1天“秒售”,!部分房源價(jià)格回落到5年前

警惕!烏克蘭戰(zhàn)場(chǎng)的“薩拉熱窩時(shí)刻”正在逼近

特朗普前顧問(wèn)出招逼俄烏和談,,自信“俄羅斯會(huì)因這一承諾被哄騙至談判桌前”

荷蘭2-3慘敗卻大賺,法國(guó)1-1沒(méi)輸反而虧慘,,姆巴佩臉色難看真急了
蔚來(lái)回應(yīng)加速踏板斷裂 涉事車(chē)輛系二手事故車(chē)
父母假裝不知成績(jī)配合女兒查分歡呼 網(wǎng)友:父母提供的情緒價(jià)值拉滿了

長(zhǎng)生不老“神藥”NMN禁售風(fēng)波 市場(chǎng)混亂與監(jiān)管收緊并行

俄羅斯警告美國(guó)后,,這兩位防長(zhǎng)首次通話

羅云熙:“潤(rùn)玉”紅利吃了6年,新劇因?yàn)樘莘?chē) 古裝美男變尷尬

不愧是韓國(guó),!直接威脅俄羅斯……

俄羅斯直接指責(zé)美國(guó)參與克里米亞襲擊:后果自負(fù)

武僧一龍兩次都打不贏的日本人,,碰上中國(guó)小將,,被打的滿臉都是血

造價(jià)3億多美元扛不住4級(jí)風(fēng) 美軍碼頭為何這么脆
姆巴佩歐洲杯首球刷爆4大紀(jì)錄,!神劇本:8強(qiáng)戰(zhàn),姆皇有望對(duì)決C羅

為何補(bǔ)時(shí)8分鐘?魔笛主帥不服,,董路猜想
相關(guān)新聞
馬斯克:我最大的恐懼是AI,,未來(lái)工作何去何從,?
2024-05-25 22:56:38馬斯克:我最大的恐懼是AI多地高校將嚴(yán)查AI代寫(xiě)論文 引進(jìn)AIGC檢測(cè)系統(tǒng)查AI
2024-05-17 14:08:12多地高校將嚴(yán)查AI代寫(xiě)論文OpenAI發(fā)布全新生成式AI模型GPT-4o 交互革新,,實(shí)時(shí)多模態(tài)引熱議
2024-05-15 09:10:07OpenAI發(fā)布全新生成式AI模型GPT-4o知識(shí)之舟導(dǎo)航未來(lái),!AI僅10秒寫(xiě)完主題是AI的高考作文
2024-06-07 13:23:08AI僅10秒寫(xiě)完主題是AI的高考作文AI時(shí)政視界|未來(lái)之城 日新月異
2024-04-02 08:27:40AI時(shí)政視界|未來(lái)之城Windows 11 AI PC品類(lèi)發(fā)布:專(zhuān)為AI體驗(yàn)而設(shè)計(jì),,重塑未來(lái)計(jì)算
2024-05-21 15:48:2611








