最新,!美國專家批駁國會DeepSeek報告(5)

第三,,
雖然存在關于DeepSeek在訓練過程中使用了更先進的美國模型輸出進行蒸餾的指控,但目前沒有任何確鑿證據(jù)證實此事,,蒸餾在DeepSeek V3和R1模型訓練中究竟扮演了多重要的角色也尚不明確。
從DeepSeek公開發(fā)布的論文來看,其所詳細描述的創(chuàng)新方法,,在解釋模型性能時顯然起到了更關鍵的作用,。
第四,正如我之前詳細說明過的,,
DeepSeek用于訓練其模型的先進GPU,,都是在美國出口管制尚未限制對華出口的時期合法獲得的。
市面上流傳的一些說法,,稱DeepSeek掌握了一個包含5萬顆H100GPU的大型集群,,但根據(jù)與眾多行業(yè)內部人士及了解中國高端GPU供應情況的人的交流,這種說法已經(jīng)被證實是沒有依據(jù)的,。此外,,DeepSeek將其模型開源,并在研究論文中詳細披露了訓練和優(yōu)化方法,,這些都清晰表明:DeepSeek的優(yōu)化策略是專門為了克服其可用硬件資源的限制而設計的,,包括一批A100GPU和少量H800GPU——而這些硬件都是在H800也被列入出口管制清單之前獲得的。無論如何,,很明顯,,DeepSeek會繼續(xù)利用現(xiàn)有的英偉達GPU資源,同時也在尋求使用國產(chǎn)AI硬件開發(fā)下一代模型,,特別是來自華為的硬件,,比如目前已經(jīng)部署在CloudMatrix384集群中、并在國內市場銷售的昇騰910C芯片,。未來,,DeepSeek還可能利用華為硬件和云服務的進一步升級,比如傳聞中的昇騰910D以及昇騰920系列處理器,。
關于所謂“中國軍方和政府資助DeepSeek研究”的報告,,其實相當牽強。
大約在《DeepSeek揭秘》報告發(fā)布的同時,,咨詢公司Exiger也發(fā)布了一份關于DeepSeek的報告,,這類“研究”在近期針對中國企業(yè)的報道中很常見。這份報告充滿了將關系錯誤歸因,、無端指控DeepSeek存在“欺騙”行為的低級錯誤,。 報告標題為《DeepSeek的欺騙:中國軍方和政府如何資助DeepSeek的AI研究》,但這一標題完全不準確,,因為DeepSeek的研發(fā)資金完全來自其母公司幻方資本(High Flyer Capital)的投資,,這一事實有清晰的文件記錄支持。

女孩考試后獨自挑行李回家 腳步鏗鏘有力

3天被拒18次,,老年人租房難背后

商家售賣北大未名湖湖水 北大回應 涉嫌虛假宣傳與欺詐

特朗普稱洛杉磯被外國入侵,,紐森稱特朗普是個騙子! 加州州長反對派兵決定

印度一地祈福圣水實際是水管破了 迷信與現(xiàn)實的碰撞

跪謝爺爺?shù)碾p胞胎獎狀貼滿四面墻 孝心與努力見證成長

網(wǎng)紅毒玩具為何還能大行其道 甲醛超標引擔憂

臺網(wǎng)紅館長上海被投喂美食三件套 大陸之行引關注

一船只在印度海域發(fā)生爆炸 船員傷亡情況引關注
3天被拒18次,,老年人租房難背后

王曼昱錢天一vs李雨琪向俊霖

美國版“我說城門樓子你說胯骨軸子”

宋兆普說絕不可以坑病人:病人是自己的恩人,,也是親人

“內戰(zhàn)”言論背后美國局勢如何發(fā)展 憲政危機浮現(xiàn)

特朗普稱抗議者為“畜生”“外敵” 誓言恢復秩序

司機說跑車20多天退車倒欠8千 想給同行提個醒
女孩考試后獨自挑行李回家 腳步鏗鏘有力

38歲教師第4次帶高中畢業(yè)生長途騎行 瓊島逐夢之旅
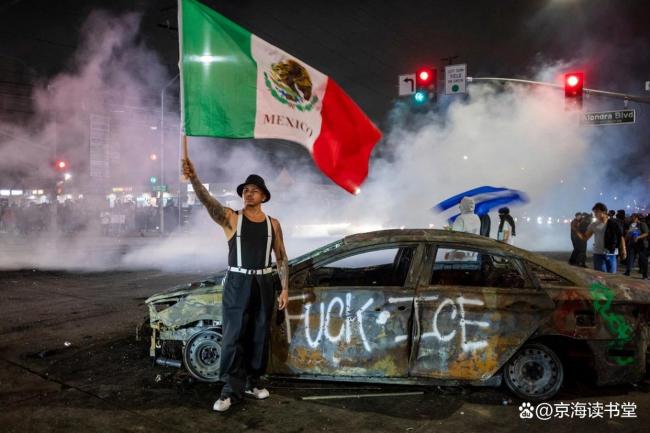
美國洛杉磯爆發(fā)的大規(guī)模騷亂的本質及未來趨勢

俄稱在多地攔截和擊落烏無人機 俄軍防空系統(tǒng)高效響應
商家售賣北大未名湖湖水 北大回應 涉嫌虛假宣傳與欺詐

英澳加等制裁以財長及國安部長 五國聯(lián)合行動

專家:李在明要強化韓美關系 展開實用外交策略

澤連斯基要求美國歐洲采取行動 施壓促和平

美醫(yī)學界要求特朗普政府撤銷決定 突然撤換CDC疫苗咨詢小組所有成員

以治癌為幌子詐騙9人共70余萬元 “劉神醫(yī)”獲刑十二年

臺灣網(wǎng)紅“館長”來大陸:看看就知道誰說謊了 實地體驗破除謠言

渝萬高鐵站前2標忠縣段首榀箱梁架設 橋梁工程邁進新階段

馬斯克2.7億政治捐款打水漂 盟友變對手

中美經(jīng)貿(mào)磋商原則上達成協(xié)議框架 會談取得積極進展

李成鋼:中美原則上達成協(xié)議框架

特斯拉市值一夜大漲4000億 科技股領漲美股

女業(yè)主發(fā)視頻求交房陷擦邊爭議 維權之路艱難曲折

只有中國能打掉美國的優(yōu)越感,!
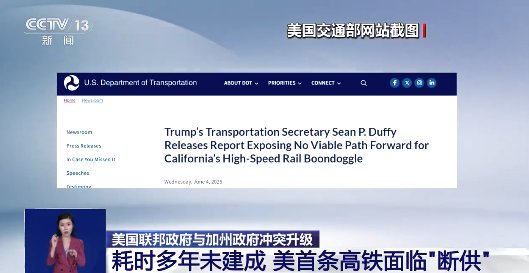
遭特朗普斷供!美國首條高鐵預計將花25年建成
相關新聞
美國專家喊話Deepseek創(chuàng)始人聯(lián)系自己 探討技術與地緣政治影響
在過去幾周里,,美國科技界對DeepSeek的討論異常熱烈,,焦點集中在芯片供應和技術壁壘上。人們紛紛猜測,,DeepSeek到底囤積了多少芯片,,又通過哪些手段繞過了美國的出口管制
2025-02-16 10:26:58美國專家喊話Deepseek創(chuàng)始人聯(lián)系自己美國專家:DeepSeek將AI推向低成本 推動AI開發(fā)新階段
2025-03-15 10:25:01美國專家中醫(yī)專家回應DeepSeek開藥方 AI建議僅供參考
2025-02-20 22:49:06中醫(yī)專家回應DeepSeek開藥方美關稅政策計算依據(jù)遭廣泛質疑 專家批駁其不合理性
2025-04-05 09:42:52美關稅政策計算依據(jù)遭廣泛質疑專家:DeepSeek的成功是誰的勝利 中國教育體系的勝利
2025-02-13 02:20:14專家業(yè)內給DeepSeek上車潑冷水 股市狂歡與專家警告并存
2025-02-16 15:24:54業(yè)內給DeepSeek上車潑冷水